Nir Rachmel | InfoVis
Location based, time based, dynamic mood board
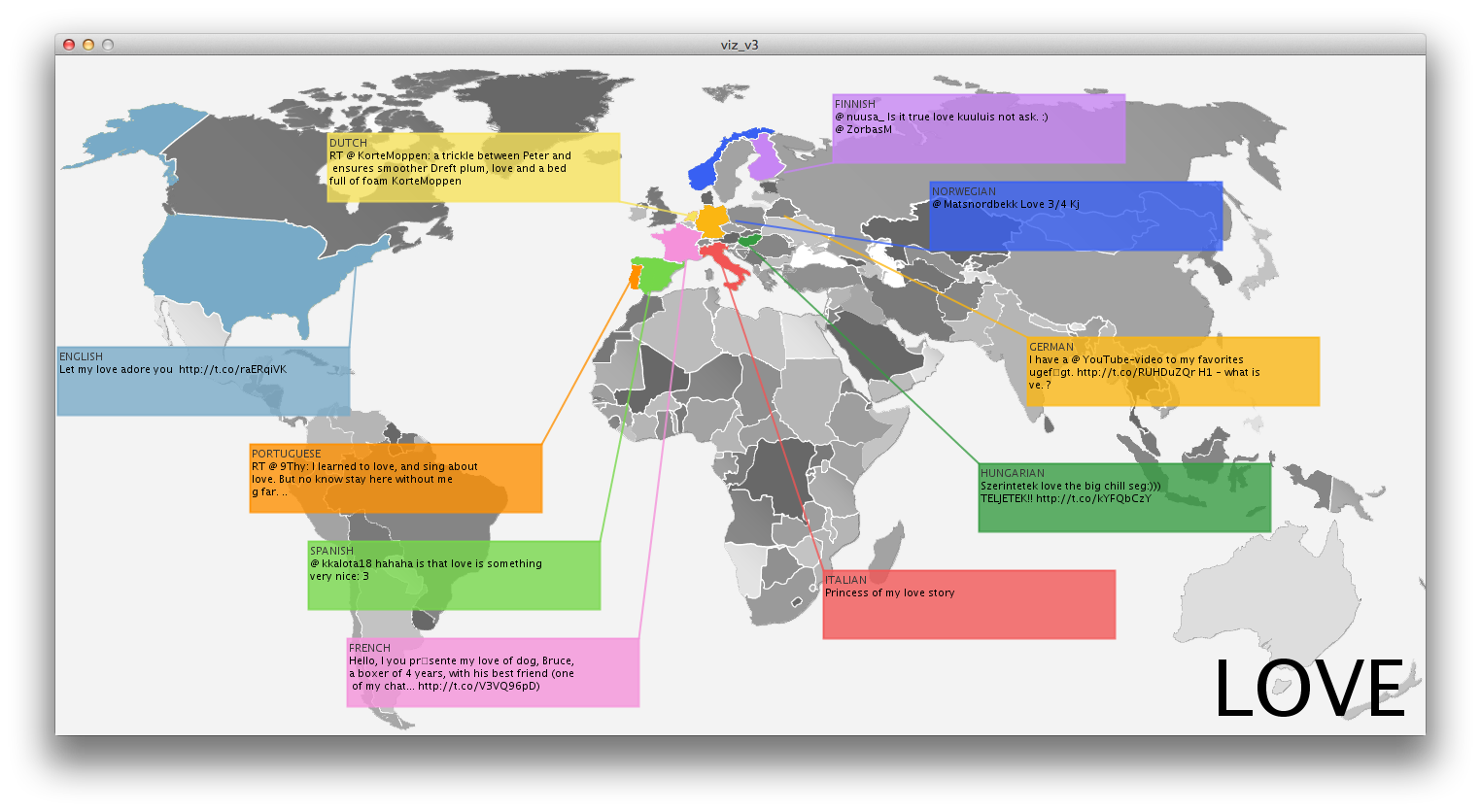
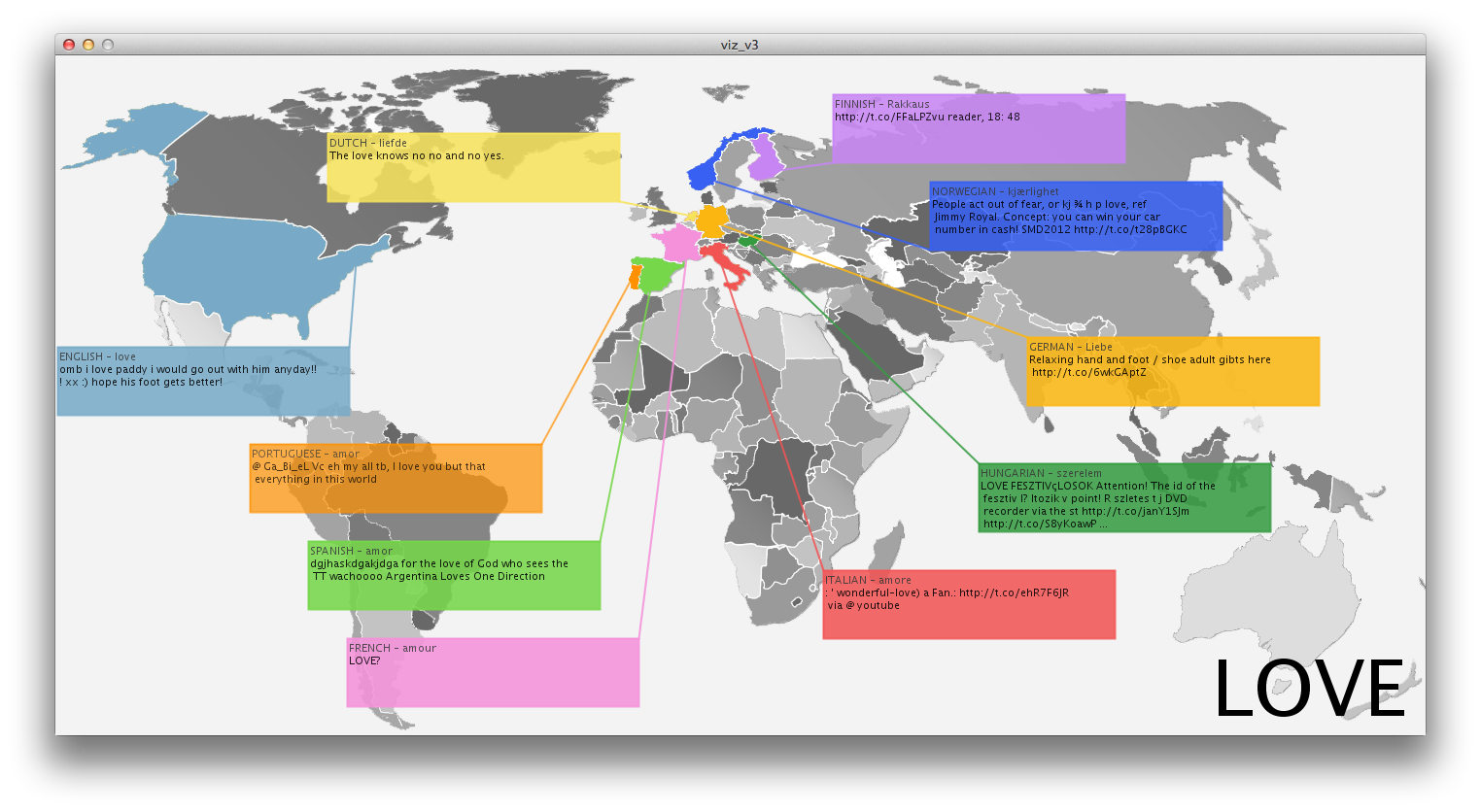
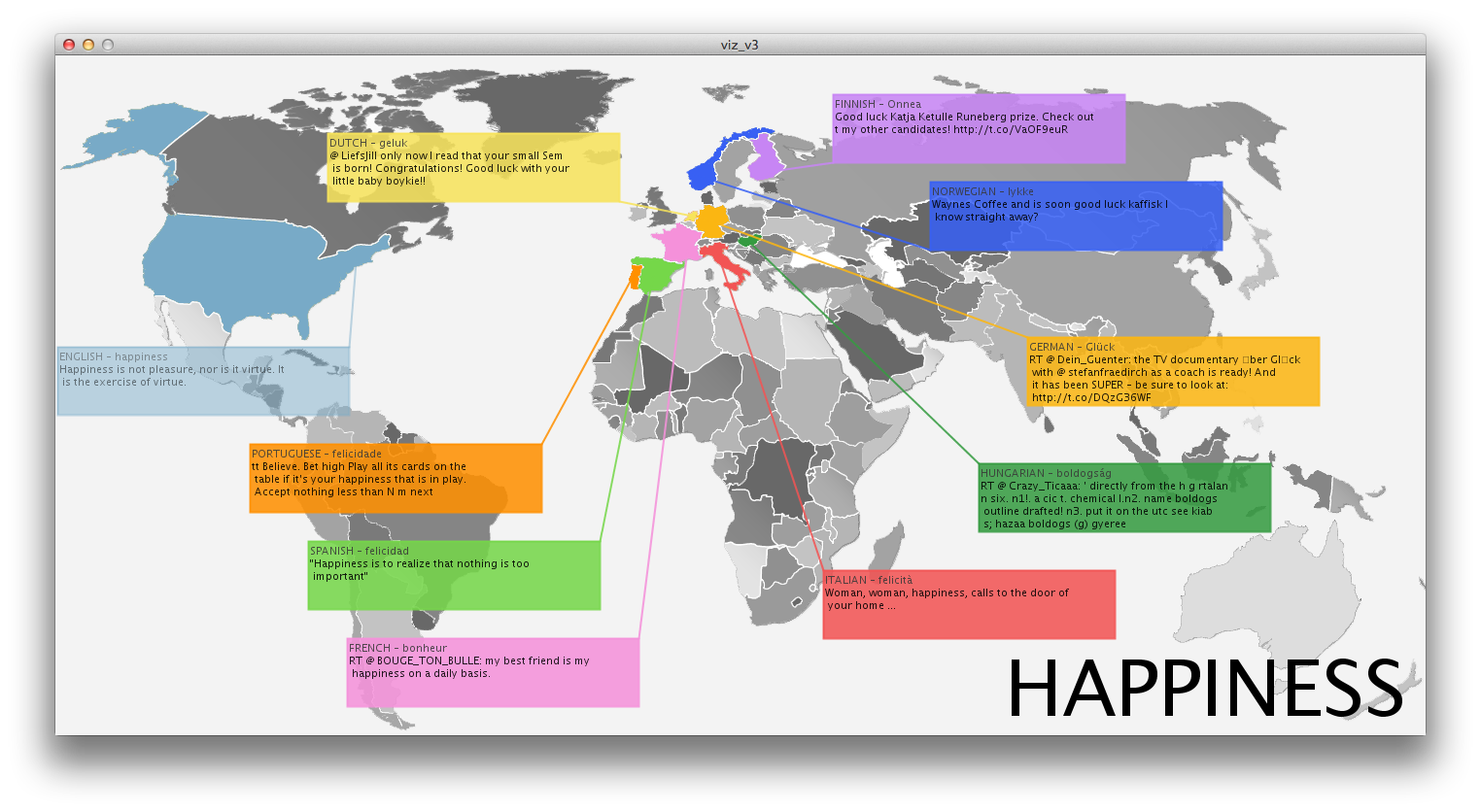
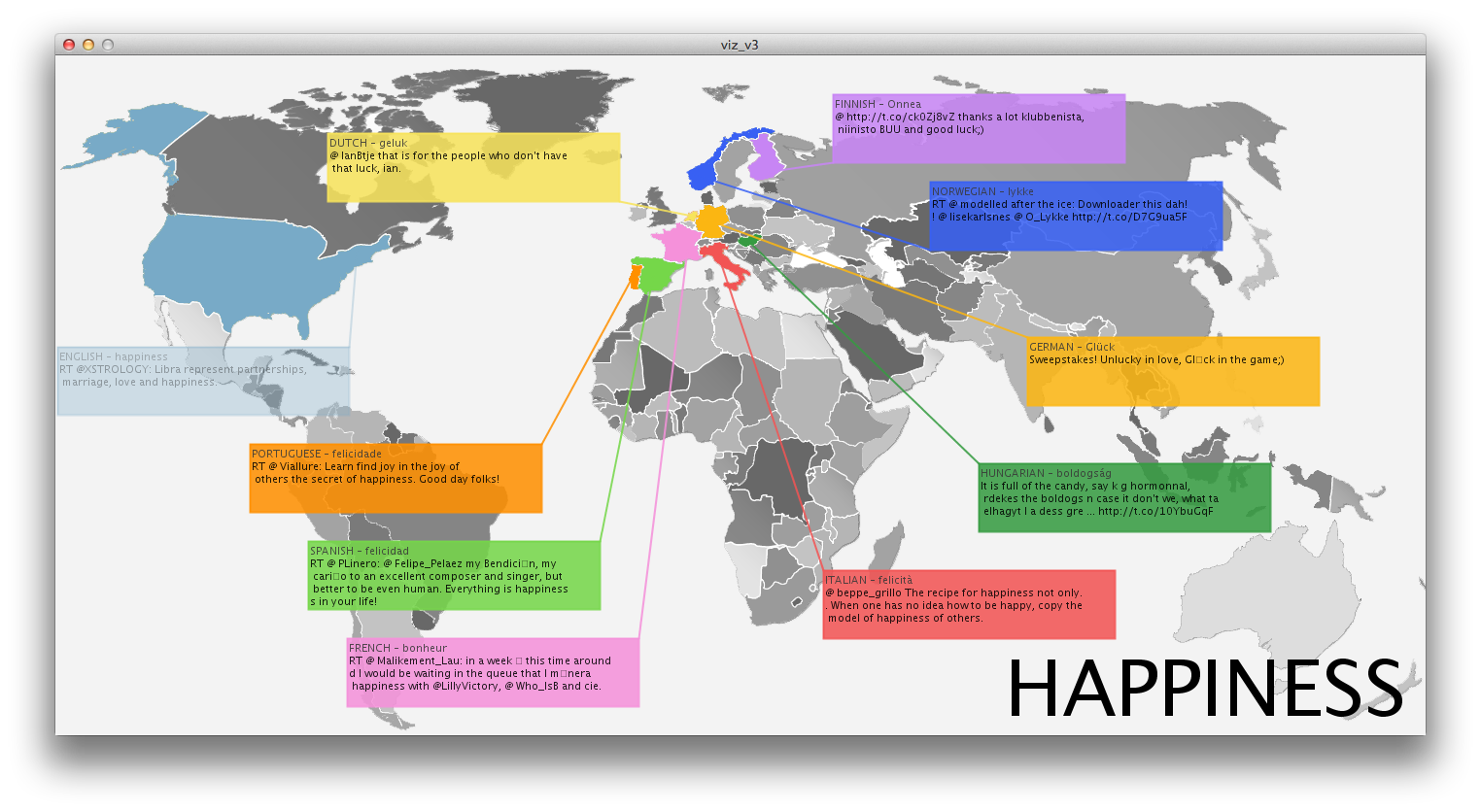
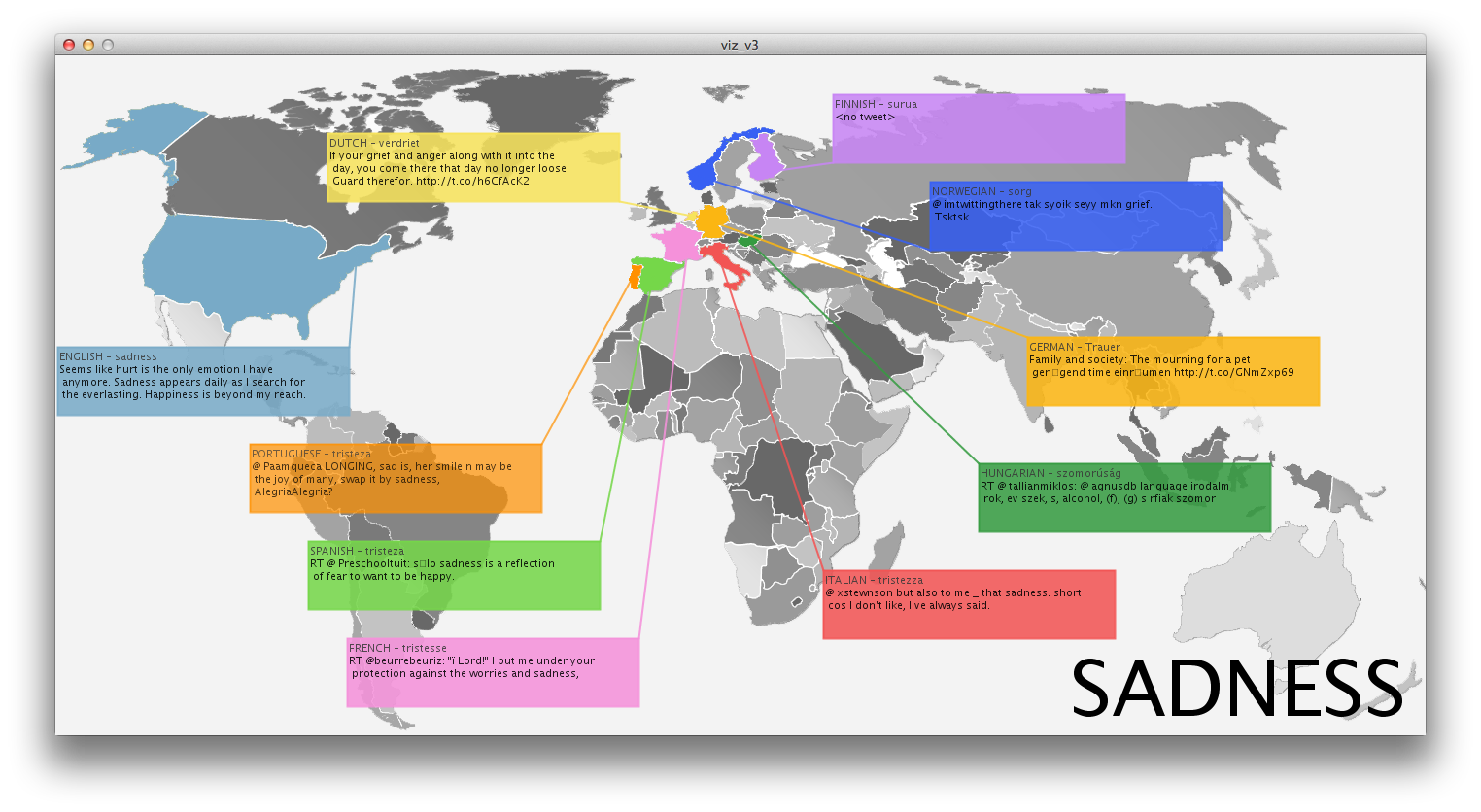
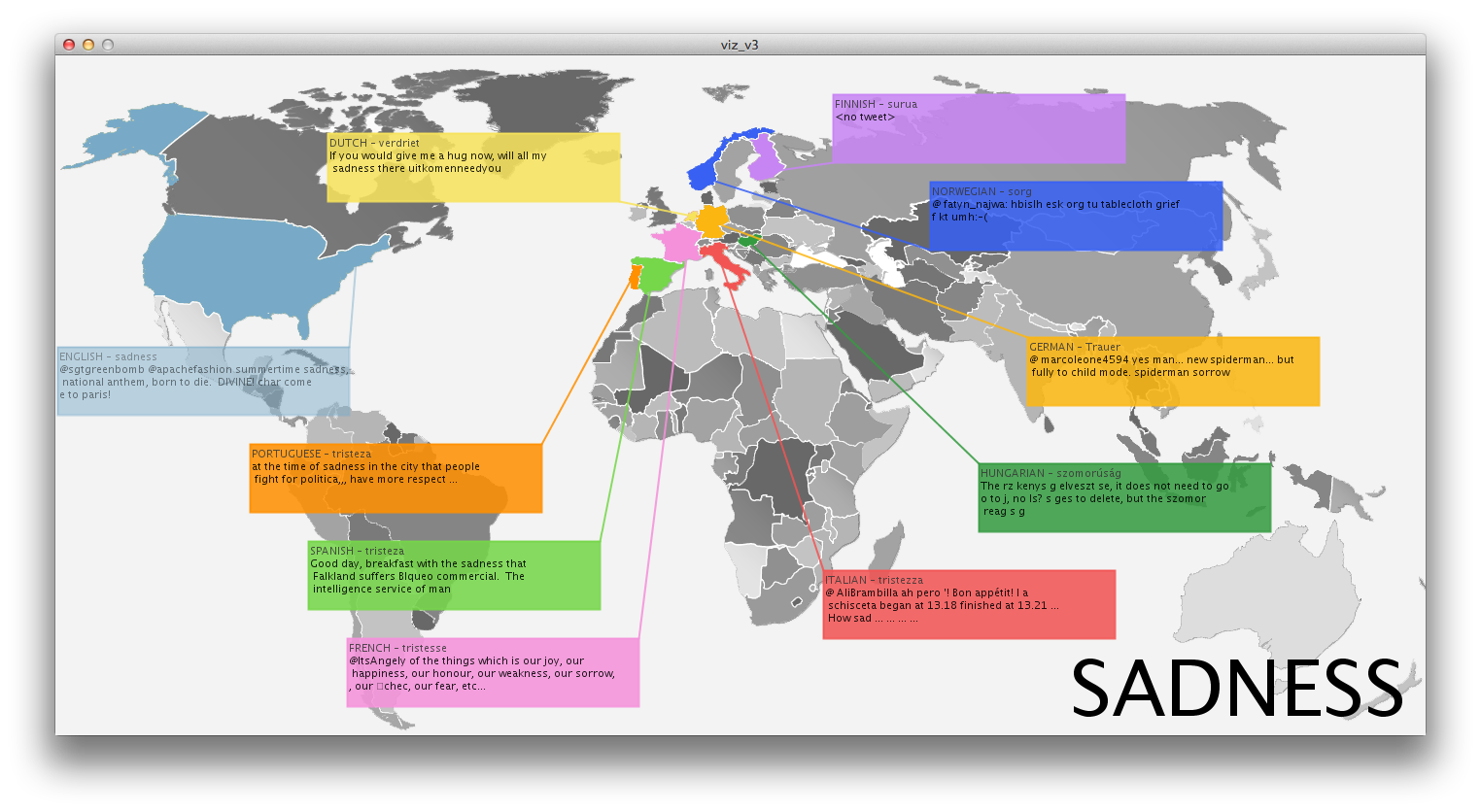
Inspired by instagram photo stream of several friends, I thought it would be interesting to display an aggregation of photos from users that can be associated to the same time and place. This can provide an alternative to the official, polished photographs we get on a daily basis from endless sources. While many people share their instagram photos, they are actually pretty private moments, many of the times. The fact that people share their photos triggered my idea that it would be cool if people could search this database in a way they couldn’t until now (Instragram doesn’t offer such an interface).
Instagram photos for example:




In order to obtain the data, I had to hack into Instagram’s API and understand how to make queries using authentication. Also, they limit the amount of photogrphs you receive per query (around 40), so that required for me to break down queries in the code to several smaller ones in order to get the maximum amount of pictures I can.
Last, in an attempt to put some order in the chaos the photos create as they appear and re-appear, I used openCV to try and analyze the photos. What interested me was to differentiate photos that have people’s faces in them from photos of scenery. As can be seen in the example below, openCV does a fair job in these situations, but remote from being perfect. In general, photos on the left hand-side of the screen would be “without photos” and the week after wards, they did.
Currently, the search for queries is done via a separate python script whose output is fed to the processing application that does all the magical graphics. In order to make this application more engaging, I would add some controls to allow the user to perform search in an easy and intuitive way, rather than have to run a separate script.