While trying to decide whether I want my next project to focus more on InfoVis or GenArt I definitely find myself stuck somewhere in between. What I do know is that I’m fascinated with 3D forms and physical artifacts generated through code, and, in particular, would love to explore means of being able to create unique objects through making sounds (singing, talking, screaming, etc), which reflect the nature of the sound. Below are a few nifty things I stumbled upon while exploring that space.
…But Narcissus & Nemesis
http://www.new-territories.com/blog/ncertainties/col12/scenariopair/luisandriana/
Let me be totally frank: At first, I had no idea what this was, and I clicked on it mainly because I was sick of looking at post-modern architecture and saw a link with alliteration and mythology in the title. In retrospect, I still am not sure I know what this is. Things I do know: 1) there are a lot of calculations going on here, 2) there is a lot of poetry and metaphysics going on here, 3) the presentation style leaves it incredibly ambiguous as to what falls under category (1) vs. (2). 4) Design fiction or fact, I’m a little bit obsessed with it. Maybe a lot.
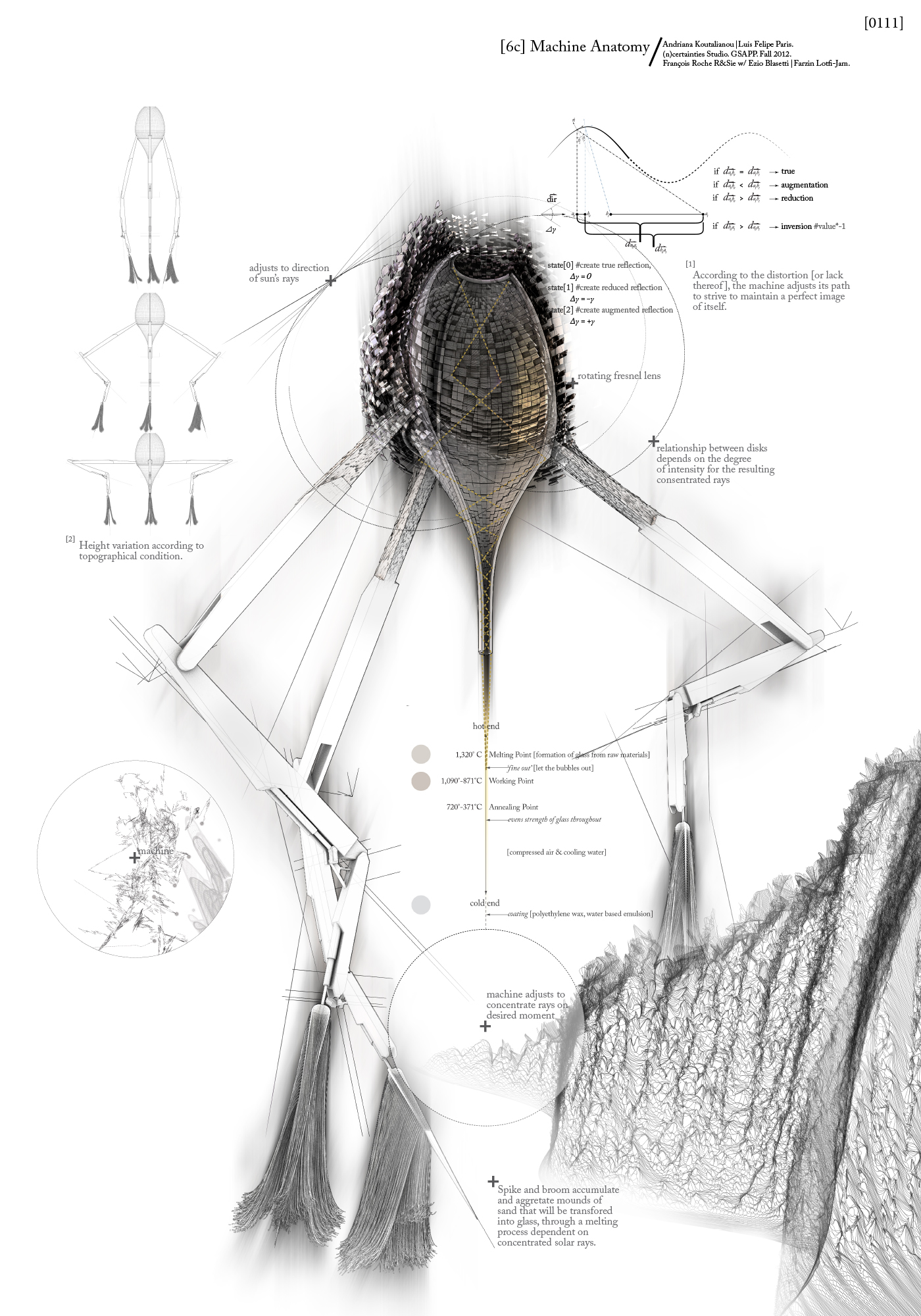
I think the most interesting idea contained in this piece is that coded generative behavior can stem from something higher and more abstract than math models, biological transport systems, cellular behavior, plant growth, or basic instincts like hunger or fear. Here, the ‘machine’ is driven by the weighty and cerebral desire to ‘maintain a perfect image of itself” as it continually moves and melts sand into glass. As the environment shifts and the glass causes distortions, the machine must move, but in doing so, creates more distortions in its environment…. it all just screams kafka novel to me.
So much of this system is entirely narrative. You could, I suppose, invent any number of stories to superimpose upon the graphs generated by the code, but the fact that the code seems to have been written in order to bring this story to life, and to address such an interesting concept of self-image and paranoia, anxiety, identity, makes this piece stand out among other examples I’ve seen. It’s also fair to say that I may have interpreted the thing entirely wrong, and it doesn’t really matter to me, because I’m still moved.
ShapeShift
http://www.caad-eap.blogspot.com/p/exhibition_15.html
I was a MatSci geek in undergrad, and did a lot of experiments trying to create piezoelectric ceramic thin films. I liked the idea that a material that looked rigid and immoveable could take on a completely different character in the presence of electricity. From what I can tell, there’s no real code in this demo, but I appreciate the potential for interacting with this material using code. Consider, for instance, talking into a microphone, and watching the material cringe away from the words you say because of the way you said them. In a way, that’s both visualizing information, and generative art, but both are embedded within the polymer itself!
Digimorph
http://digimorph.org/
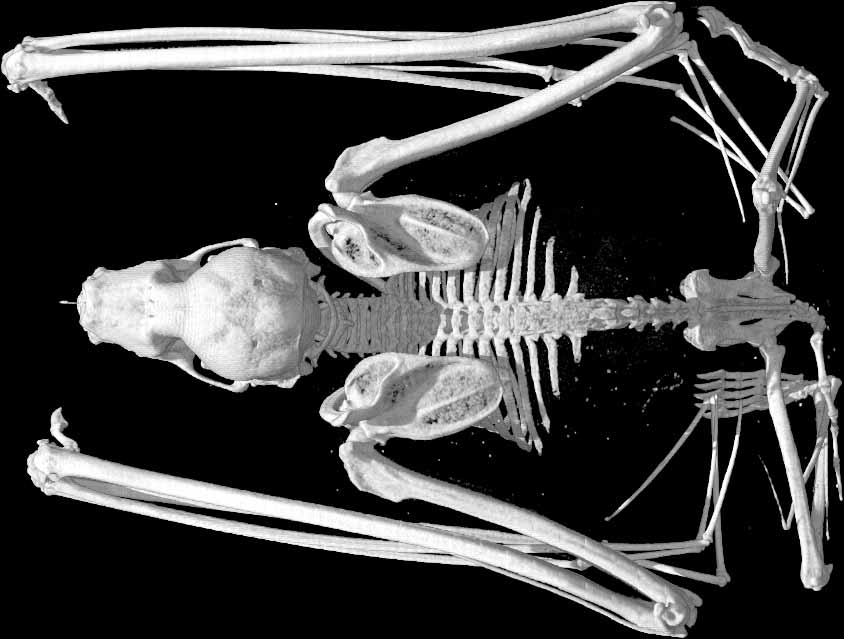
Um, no, this isn’t some odd genetic hybrid of Digimon and the Animorphs—but it does have something to do with genetics and weird animals. As the website explains (if you can suffer through its rather ugly design), this is a database of hi-res, x-ray computed tomography of a whole slew of animals, living and extinct. I’m including it both because they have a fairly interesting description of what goes into generating these scans, and how the computer constructs X-Ray tomographs from fragments and slices of images, and because it could possibly serve as an incredible database to mine for an infoVis project (there has to be a better way to display all these amazing images than that website! yikes…)