Reddit Bible
About
In short, the Reddit Bible compares questions found on 8 advice boards of reddit with interrogative sentences found in the bible.
After much wrangling with religious-text based concepts, I decided to create a "Reddit Advice" board by answering biblical questions with Reddit content. I scraped the Bible for interrogative sentences, and found similarities in questions scraped from Reddit advice boards, using sentence embedding. From there, I wanted to to answer the Bible Questions with Markov-chain generated answers based on the thread responses of the respective Reddit questions.
Unexpectedly, I loved the results of the "similar" reddit and bible questions--the seeming connections between the two almost hint at some sort of relation between the questions people are asking now and in Biblical times. Though I did go through with the Markov chained responses, the results were a bit jumble-y and seemed to take away from what I liked about the juxtaposed questions. Ultimately, I made the decision to cut the Markov chains, and to highlight the contrast in pairs of questions, as well as how similar the computer thinks the question pairs are.
Inspiration
I originally wanted to generate some sort of occult text, ie. Chinese Divination. I ended up pivoting to the more normative of religious texts, the Bible to be specific, since I have a lot of personal experience with this one. Prior to the "reddit advice" board, I actually had the opposite idea, of making a "christian advice" board where I would gather 4chan questions, and answer them with markov chain generated responses based on real christian advice forums. I scraped a christian advice forum, but the results were too few and inconsistent, so I knew I had to pivot a bit. That's when I flipped the idea and decided to reverse it to answering bible questions with reddit data. (4chan's threads were a little too inconsistent and lacking compared with reddits thousand-count response threads).
If anyone ever wants buttloads of responses from a christian forum: https://github.com/swlsheltie/christian-forum-data
Process
Once I solidified my concept, it was time to execute, one step at a time.
- Getting matching question pairs from Reddit and the Bible
- Getting questions from Reddit
- Reddit has a great API called PRAW
- Originally I only scraped r/advice, but towards the end, I decided to bump it up and scrape 8 different advice subreddits: r/advice, r/internetparents, r/legal_advice, r/need_a_friend, r/need_advice, r/relationship_advice, r/tech_support, r/social_skills
- Using PRAW, i looked at top posts of all time, with no limit
- r/Advice yielded over 1000 question sentences, and the other advice subreddits ranged more or less around that number.
- Lists with the lists of scraped questions:
-
# REDDIT QUESTIONS X BIBLE QUESTIONS # ENTER A SUBREDDIT # FIND ALL QUESTIONS # INFERSENT WITH BIBLE QUESTIONS # GET LIST OF [DISTANCE, SUBREDDIT, THREAD ID, SUBMISSION TEXT, BIBLE TEXT] # HIGHLIGHT SPECIFIC QUESTION # load 400 iterations # format [distance, subreddit, reddit question, bible verse, bible question] # get bible questions from final_bible_questions import bible_questions from split_into_sentences import split_into_sentences # write to file data_file= open("rqbq_data.txt", "w") rel_advice_file = open("rel_advice.txt", "w") legal_advice_file = open("legal_advice.txt", "w") tech_support_file = open("tech_support.txt", "w") need_friend_file = open("needfriend.txt", "w") internetparents_file = open("internetparents.txt", "w") socialskills_file = open("socialskills.txt", "w") advice_file = open("advice.txt", "w") needadvice_file = open("needadvice.txt", "w") files = [rel_advice_file, legal_advice_file, tech_support_file, need_friend_file, internetparents_file, socialskills_file, advice_file, needadvice_file] # libraries import praw import re # reddit keys reddit = praw.Reddit(client_id='---', client_secret='---', user_agent='script: http://0.0.0.0:8000/: v.0.0(by /u/swlsheltie)') # enter subreddit here ------------------------------------------------------------------------------------action required list_subreddits = ["relationship_advice", "legaladvice", "techsupport", "needafriend", "internetparents", "socialskills", "advice", "needadvice"] relationshipadvice = {} legaladvice={} techsupport={} needafriend={} internetparents={} socialskills={} advice={} needavice={} subreddit_dict_list=[relationshipadvice, legaladvice, techsupport, needafriend, internetparents, socialskills, advice, needavice] relationshipadvice_questions = [] legaladvice_questions =[] techsupport_questions=[] needafriend_questions=[] internetparents_questions=[] socialskills_questions=[] advice_questions=[] needavice_questions=[] questions_list_list=[relationshipadvice_questions, legaladvice_questions, techsupport_questions, needafriend_questions, internetparents_questions, socialskills_questions, advice_questions, needavice_questions] # sub_reddit = reddit.subreddit('relationship_advice') for subreddit in list_subreddits: counter=0 print(subreddit) i = list_subreddits.index(subreddit) sub_reddit = reddit.subreddit(subreddit) txt_file_temp = [] for submission in sub_reddit.top(limit=1000): # print(submission) print("...getting from reddit", counter) submission_txt = str(reddit.submission(id=submission).selftext.replace('\n', ' ').replace('\r', '')) txt_file_temp.append(submission_txt) counter+=1 print("gottem") for sub_txt in txt_file_temp: print("splitting") sent_list = split_into_sentences(sub_txt) for sent in sent_list: print("grabbing questions") if sent.endswith("?"): questions_list_list[i].append(sent) print("writing file") files[i].write(str(questions_list_list[i])) print("written file, next") # for list_ in questions_list_list: # print("\n") # print(list_subreddits[questions_list_list.index(list_)]) # print(list_) # print("\n")
- Getting questions from the bible
- Used the King James Version, because of this awesome text file, that only has the text in it (no verse numbers, etc) (would bite me in the ass later on)
- Found some code on Stack Overflow that allowed me to get a list of the sentences in the bible
- Originally used RITA to get the question sentences, then towards the end (since rita --> python was too much of a hassle), I just went through found all sentences that ended with a "?".
-
file = open("bible.txt", "r") empty= open("bible_sent.txt", "w") bible = file.read() from nltk import tokenize import csv import re alphabets= "([A-Za-z])" prefixes = "(Mr|St|Mrs|Ms|Dr)[.]" suffixes = "(Inc|Ltd|Jr|Sr|Co)" starters = "(Mr|Mrs|Ms|Dr|He\s|She\s|It\s|They\s|Their\s|Our\s|We\s|But\s|However\s|That\s|This\s|Wherever)" acronyms = "([A-Z][.][A-Z][.](?:[A-Z][.])?)" websites = "[.](com|net|org|io|gov)" # final_output=[] def split_into_sentences(text): text = " " + text + " " text = text.replace("\n"," ") text = re.sub(prefixes,"\\1",text) text = re.sub(websites,"\\1",text) if "Ph.D" in text: text = text.replace("Ph.D.","PhD") text = re.sub("\s" + alphabets + "[.] "," \\1 ",text) text = re.sub(acronyms+" "+starters,"\\1 \\2",text) text = re.sub(alphabets + "[.]" + alphabets + "[.]" + alphabets + "[.]","\\1\\2\\3",text) text = re.sub(alphabets + "[.]" + alphabets + "[.]","\\1\\2",text) text = re.sub(" "+suffixes+"[.] "+starters," \\1 \\2",text) text = re.sub(" "+suffixes+"[.]"," \\1",text) text = re.sub(" " + alphabets + "[.]"," \\1",text) if "”" in text: text = text.replace(".”","”.") if "\"" in text: text = text.replace(".\"","\".") if "!" in text: text = text.replace("!\"","\"!") if "?" in text: text = text.replace("?\"","\"?") text = text.replace(".",".") text = text.replace("?","?") text = text.replace("!","!") text = text.replace("",".") sentences = text.split("") sentences = sentences[:-1] sentences = [s.strip() for s in sentences] return (sentences) # final_output.append(sentences) print(split_into_sentences(bible)) # with open('christian_forums1.csv', newline='') as csvfile: # reader = csv.reader(csvfile) # for row in reader: # for i in range(2): # if (i==1) and (row[i]!= ""): # input_txt = row[0] # # print(text) # # list_sent = tokenize.sent_tokenize(text) # # sentences.append(list_sent) # list_sent= split_into_sentences(input_txt) # final_output.append(list_sent) # list_sent = split_into_sentences(bible) # for sent in list_sent: # # print(sent) # empty.write(sent+"\n") # empty.close() # print(list_sent)
-
- Results: around 1000+ Bible questions, find them here
- Get matching pairs!!!
- My boyfriend suggested that I use sentence embeddings to find the best matching pairs. This library is the one i used. It was super easy to install+use! 4.75 Stars
- Infersent pumps out a 2d matrix containing each vector of each sentence in the list of sentences that you provide. I gave it the list of bible questions, then ran a loop to get the embeddings of all 8 subreddit question lists.
- Then another loop with matrix multiplication to get each matrix with the distances between the bible vs. [respective] subreddit sentences.
- Since the matrix contains such precise information about how close two sentences, are I wanted to visualize this data. I saved the "distances," and used circle size to show how close they are.
- I didn't have that much time to visually design the book, which I regret, and the circle sizes were obviously not that communicative about what they represented. I ended up including a truncated version of the distances on each page.
- Markov chaining the responses
-
- Now that I had my reddit questions to their bible question counterparts, I wanted to get a mishmash of the respective response threads of the submissions that the questions came from.
-
submission = reddit.submission(pair["thread_id"]) for top_level_comment in submission.comments: if isinstance(top_level_comment, MoreComments): continue # print(top_level_comment.body) comment_body.append(top_level_comment.body) comment_body_single_str="".join(comment_body) comment_body = split_into_sentences(comment_body_single_str) # print(" ".join(comment_body)) text_model = markovify.Text(comment_body) for i in range(10): print(text_model.make_sentence())
- This was an example of my result:
-
Submission Data: {'thread_id': '7zg0rt', 'submission': 'Deep down, everyone likes it when someone has a crush on them right? So why not just tell people that you like them if you do? Even if they reject you, deep down they feel good about themselves right? '}
Markov Result: Great if you like it, you generally say yes, even if they have a hard time not jumping for joy.
Us guys really do love it when someone has a crush on them right?
I think it's a much more nuanced concept.
In an ideal world, yesDepends on the maturity of the art.
But many people would not recommend lying there and saying "I don't like you", they would benefit from it, but people unequipped to deal with rejection in a more positive way.
If it's not mutual, then I definitely think telling them how you feel, they may not be friends with you or ignore you, or not able to answer?
I've always been open about how I feel, and be completely honest.
In an ideal world, yesDepends on the maturity of the chance to receive a big compliment.
So while most people would argue that being honest there.
I think that in reality it's a much more nuanced examples within relationships too.
-
- While this was ok, I felt like the Markov data just probably wasn't good (extensive) enough to sound that different from the source. It didn't seem like this would add anything to the concept, so I decided to cut it.
-
- Organizing the matching pairs
- The part that I probably had the most difficulty with was trying to organize the lists into [least distant] to [most distant] pairs. Seemed really easy in my head, but for reason, I just had a lot of trouble executing.
- However, it paid off in the end, as I was able to get random pairs from only the closest related 100 pairs from each of the 8 subreddit/bible lists.
-
import numpy import torch import json from rel_advice import rel_advice from legal_advice import legal_advice from techsupport import techsupport from needfriend import needfriend from internetparents import internet_parents from socialskills import socialskills from advice import advice from needadvice import needadvice from final_bible_questions import bible_questions from bible_sent import bible_sentences final_pairs= open("final_pairs.txt", "w") # final_pairs_py= open("final_pairs_py.txt", "w") with open("kjv.json", "r") as read_file: bible_corpus = json.load(read_file) rqbq_data_file = open("rqbq_data.txt", "w") subreddit_questions = [rel_advice, legal_advice, techsupport, needfriend, internet_parents, socialskills, advice, needadvice] list_subreddits = ["relationship_advice", "legaladvice", "techsupport", "needafriend", "internetparents", "socialskills", "advice", "needadvice"] bible_verses=[] # for from models import InferSent V = 2 MODEL_PATH = 'encoder/infersent%s.pkl' % V params_model = {'bsize': 64, 'word_emb_dim': 300, 'enc_lstm_dim': 2048, 'pool_type': 'max', 'dpout_model': 0.0, 'version': V} print("HELLO", MODEL_PATH) infersent = InferSent(params_model) infersent.load_state_dict(torch.load(MODEL_PATH)) W2V_PATH = 'dataset/fastText/crawl-300d-2M.vec' infersent.set_w2v_path(W2V_PATH) with open("encoder/samples.txt", "r") as f: sentences = f.readlines() infersent.build_vocab_k_words(K=100000) infersent.update_vocab(bible_sentences) print("embed bible") temp_bible = bible_questions embeddings_bible = infersent.encode(temp_bible, tokenize=True) normalizer_bible = numpy.linalg.norm(embeddings_bible, axis=1) normalized_bible = embeddings_bible/normalizer_bible.reshape(1539,1) pairs = {} for question_list in range(len(subreddit_questions)): pairs[list_subreddits[question_list]]={} print("setting variables: ", list_subreddits[question_list]) temp_reddit = subreddit_questions[question_list] #TRIM THESE TO TEST SMALLER LIST SIZES print("embed", list_subreddits[question_list], "questions") embeddings_reddit = infersent.encode(temp_reddit, tokenize=True) print("embed_reddit dim: ",embeddings_reddit.shape) print("embed_bible dim: ", embeddings_bible.shape) normalizer_reddit = numpy.linalg.norm(embeddings_reddit, axis=1) print("normalizer_reddit dim: ", normalizer_reddit.shape) print("normalizer_bible dim: ", normalizer_bible.shape) temp_tuple = normalizer_reddit.shape normalized_reddit = embeddings_reddit/normalizer_reddit.reshape(temp_tuple[0],1) print("normalized_reddit dim:", normalized_reddit) print("normalized_bible dim:", normalized_bible) print("normed normalized_reddit dim: ", numpy.linalg.norm(normalized_reddit, ord=2, axis=1)) print("normed normalized_bible dim: ", numpy.linalg.norm(normalized_bible, ord=2, axis=1)) reddit_x_bible = numpy.matmul(normalized_reddit, normalized_bible.transpose()) print("reddit x bible", reddit_x_bible) matrix = reddit_x_bible.tolist() distances = [] distances_double=[] distances_index = [] bible_indeces=[] for reddit_row in matrix: closest = max(reddit_row) bible_indeces.append(reddit_row.index(closest)) distances.append(closest) distances_double.append(closest) cur_index = matrix.index(reddit_row) final_pairs.write("\n-------\n" + "distance: "+ str(closest)+"\n" +str(list_subreddits[question_list])+"\n"+subreddit_questions[question_list][cur_index]+"\n"+ bible_questions[reddit_row.index(closest)]+"\n-------\n") distances.sort() distances.reverse() for distance in distances: inde_x = distances_double.index(distance) distances_index.append(inde_x) pairs[list_subreddits[question_list]]["distances"]=distances pairs[list_subreddits[question_list]]["distances_indexer"]=distances_index pairs[list_subreddits[question_list]]["bible_question"]=bible_indeces # print(pairs) rqbq_data_file.write(str(pairs)) rqbq_data_file.close() # for pair in pairs: # # print( "\n-------\n", reddit_questions[pair],"\n", bible_questions[pairs[pair]], "\n-------\n") # # export_list.append([max_nums[counter], pair, pairs[pair], reddit_questions[pair], bible_questions[pairs[pair]]]) # counter+=1 # # final_pairs_py.write(str(export_list)) # # final_pairs_py.close() # final_pairs.close() # nums.append(closest) # max_nums.append(closest) # for distance in max_nums: # row = nums.index(distance) #matrix row # column = matrix[row].index(distance) # pairs[row]= column # pairs[list_subreddits[question_list]][closest]={} # reddit_bodies.append() # export_list = [] # nums=[] # max_nums = [] # max_nums.sort() # max_nums.reverse() # load 400 iterations # format [distance, subreddit, reddit question, bible verse, bible question] # build dictionary in loop, and keep list of min distances # final_pairs.write(str(pairs)) # counter = 0 # bible_x_reddit = numpy.matmul(embeddings_bible, reddit_trans) # print(bible_x_reddit)
- The part that I probably had the most difficulty with was trying to organize the lists into [least distant] to [most distant] pairs. Seemed really easy in my head, but for reason, I just had a lot of trouble executing.
- Getting questions from Reddit
- Basil.js
- Using Basil's CSV method, I was able to load pair data into the book.
-
from rqbq_data import rqbq_dictionary from bibleverses import find_verse import random import csv from rel_advice import rel_advice from legal_advice import legal_advice from techsupport import techsupport from needfriend import needfriend from internetparents import internet_parents from socialskills import socialskills from advice import advice from needadvice import needadvice from final_bible_questions import bible_questions # print(len(rqbq_dictionary)) # print(rqbq_dictionary.keys()) list_subreddits = ["relationship_advice", "legaladvice", "techsupport", "needafriend", "internetparents", "socialskills", "advice", "needadvice"] subreddit_questions = [rel_advice, legal_advice, techsupport, needfriend, internet_parents, socialskills, advice, needadvice] write_csv=[] def getPage(): subreddit_index=random.randint(0,7) subreddit = list_subreddits[subreddit_index] print("subreddit: ", subreddit) length = len(rqbq_dictionary[subreddit]["distances"]) print("length: ", length) random_question = random.randint(0,500) #SPECIFY B AS CUT OFF FOR REDDIT/BIBLE ACCURACY. 1=MOST ACCURATE, LENGTH-1 = LEAST ACCURATE print("random question num: ", random_question) print("distance of random question: ", rqbq_dictionary[subreddit]["distances"][random_question]) print("index of random question: ", rqbq_dictionary[subreddit]["distances_indexer"][random_question]) index_rand_q=rqbq_dictionary[subreddit]["distances_indexer"][random_question] index_rand_q_bible = rqbq_dictionary[subreddit]["bible_question"][index_rand_q] # print(index_rand_q, index_rand_q_bible) print("question: ", subreddit_questions[subreddit_index][index_rand_q]) print("verse: ", bible_questions[index_rand_q_bible]) verse = find_verse(bible_questions[index_rand_q_bible]) write_csv.append([rqbq_dictionary[subreddit]["distances"][random_question], subreddit, subreddit_questions[subreddit_index][index_rand_q], verse, bible_questions[index_rand_q_bible]]) # getPage() for i in range(15): getPage() with open('redditxBible.csv', 'w', newline='') as f: writer = csv.writer(f) writer.writerow(["distance", "subreddit", "reddit_question", "verse", "bible_question"]) writer.writerows(write_csv)
- Example of one of the books' CSV: redditxBible
-
- As said earlier, not having the Bible verse data was a pain when I realized it would be nice to have the verses. So I had to run each bible question in this code to get the verses:
-
import json with open("kjv.json", "r") as read_file: bible_corpus = json.load(read_file) sample = " went up against the king of Assyria to the river Euphrates: and king Josiah went against him; and he slew him at Megiddo, when he had seen him." def find_verse(string): for x in bible_corpus["books"]: for chapter in x["chapters"]: # print(chapter["verses"]) for verse in chapter["verses"]: if string in verse["text"]: return (verse["name"])
-
- Designing the book
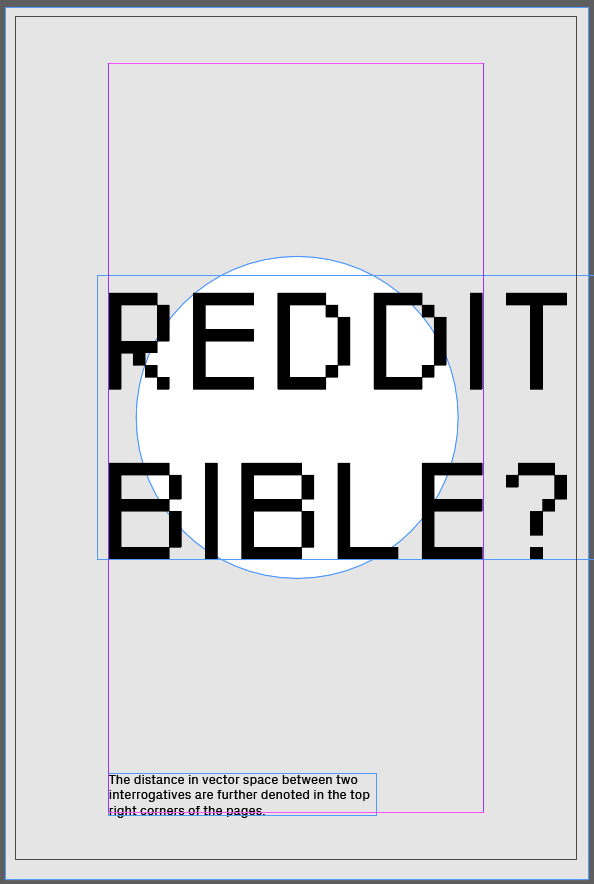

- Unfortunately, I didn't save many iterations from my design process, but I did play with having two columns, and other ways of organizing the text+typography.
- I had used Basil.js before in Kyu's class last year, so that was really helpful in knowing how to auto-resize the text box sizes.
- That way, I was able to get exact distances between all the text boxes.
- I had some trouble with rotating the text boxes and getting the locations after rotation.
- The circle was drawn easily by mapping the distance between sentences to a relative size of the page.
- Using Basil's CSV method, I was able to load pair data into the book.
Examples
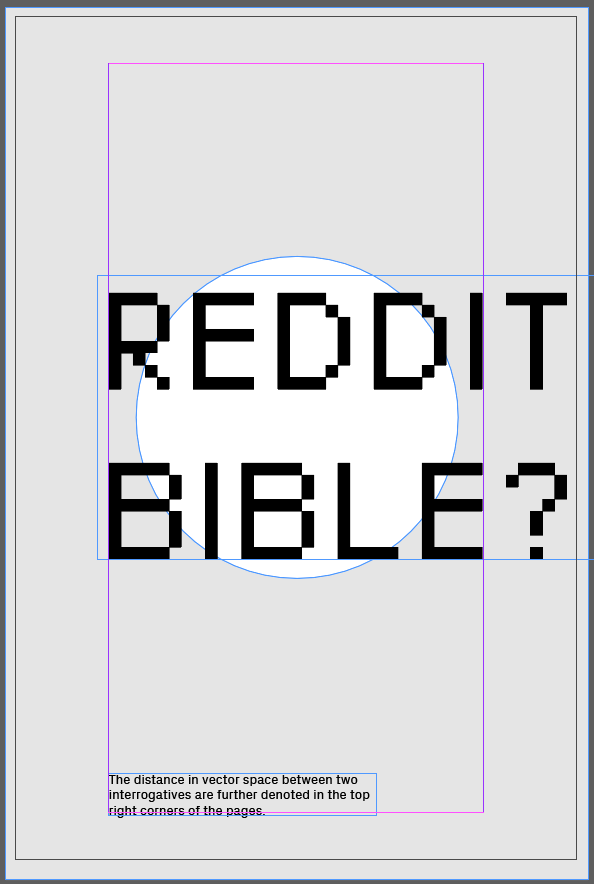


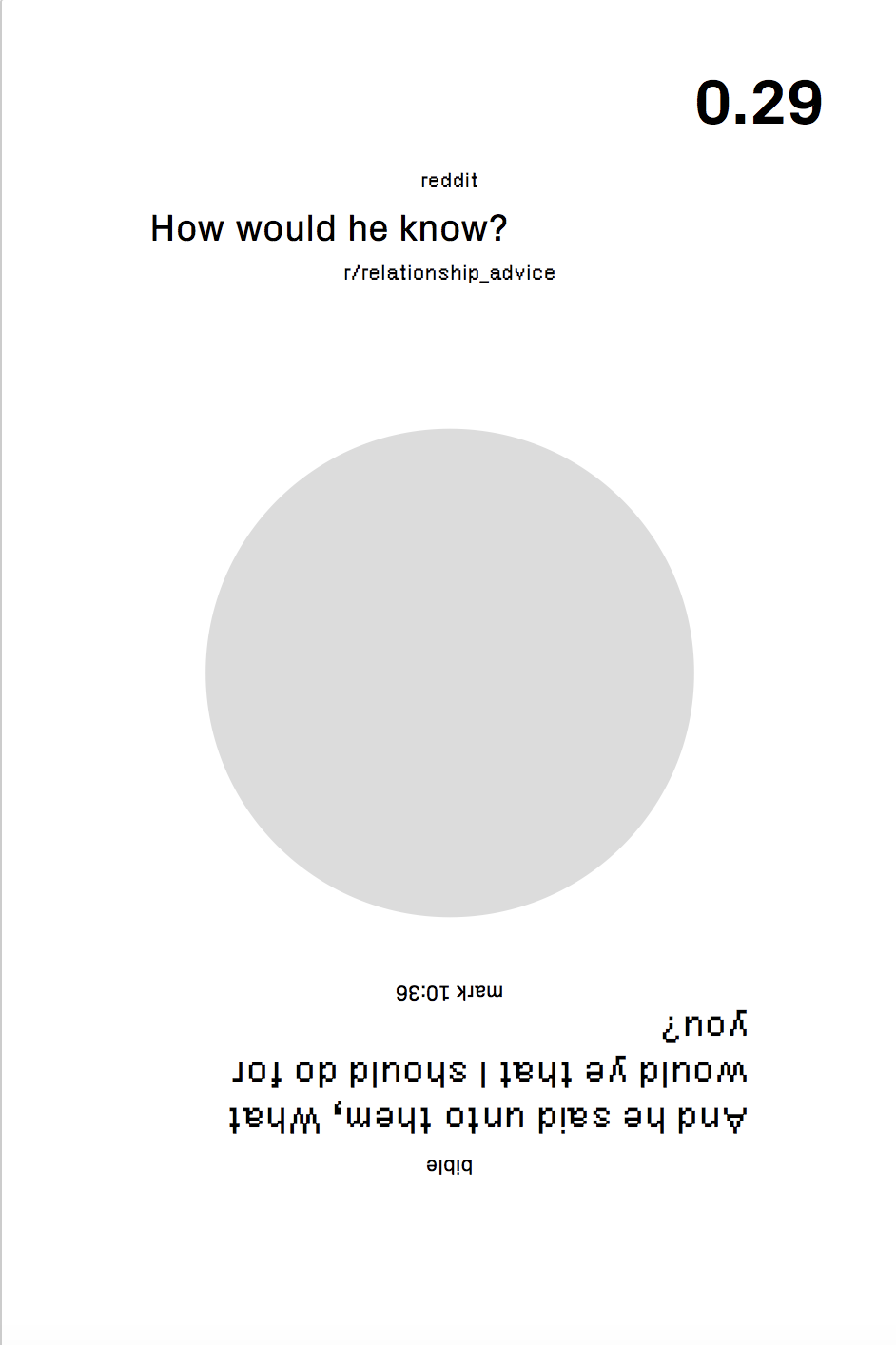


Thoughts
Overall, i really enjoyed making this book. This project was super interesting in that I feel like I really had to apply more programming knowledge than previous projects in order to combine all the parts to get fully usable code. They couldn't only work disparately, they had to able to work all together too. Piping all the parts together was definitely the toughest part. I only wish I had more time to design the book, but i will probably continue working on that onwards.