Nir Rachmel | Final Project
This visualization, of temporal rhythms in public bus occupancy levels, examines 27 million data points from the Pittsburgh transit network — the activities of every bus in Pittsburgh, captured every eight seconds, for two months.
The bus stops here
Overview
Pittsburgh busses have a device installed that monitors each bus and records parameters such as speed, direction, location and passenger occupancy. A record entry is created every 500 feet or less, resulting in a tremendous amount of data. The data set that I hold, has the information collected from these busses over two months, for all bus routes, resulting in some 27 million entries. For my project, I was curious to see if I can visualize temporal rhythms in the bus occupancy levels: Is there a trend in the time and location where the busses are full and how can I visualize it in a compelling way which will be both intriguing, interactive and insightful.
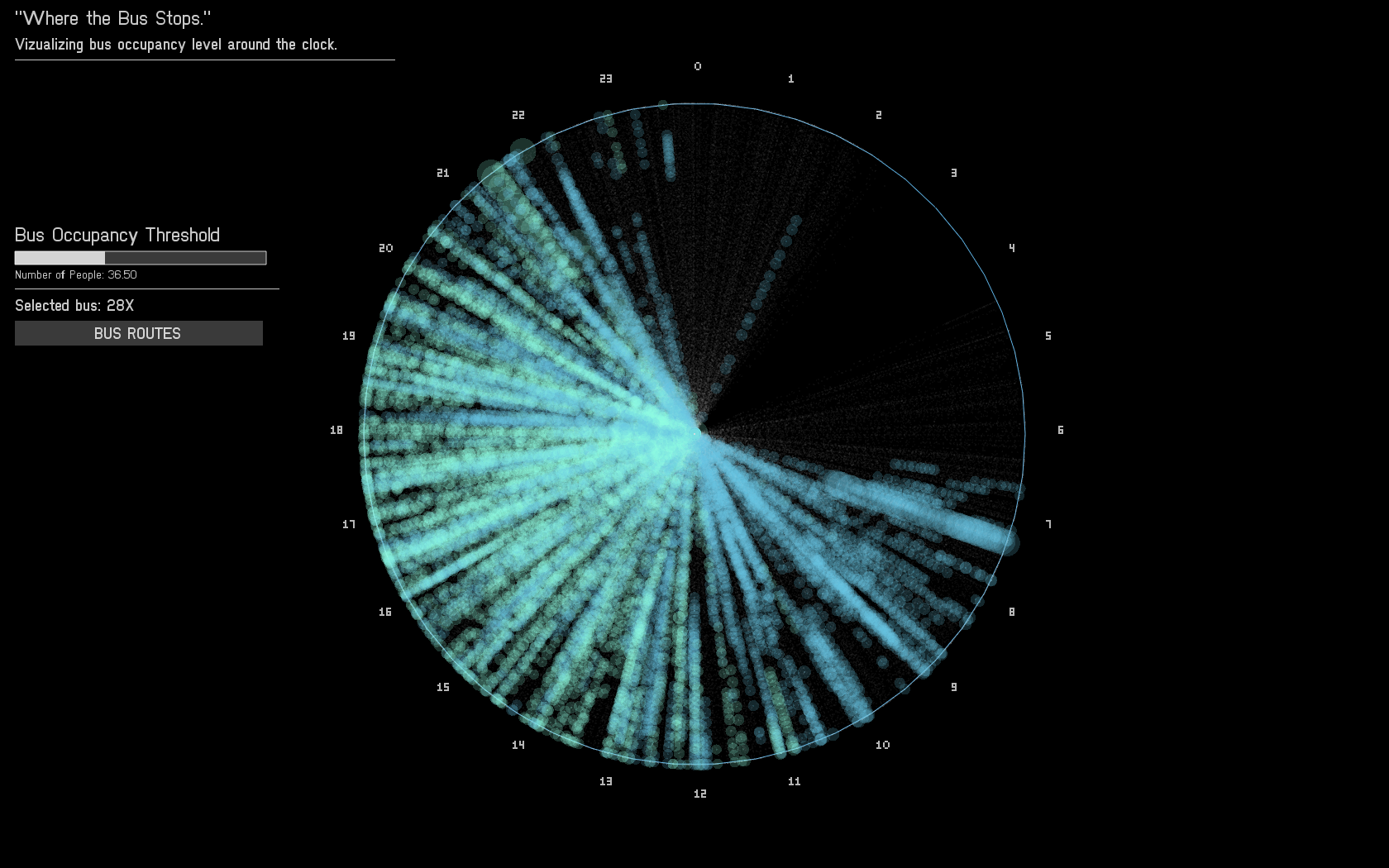
What did I make?
I decided to focus on several popular Pittsburgh bus routes that the CMU community uses on a regular and heavy basis: The 61’s, 71’s and 28x (to the airport). I extracted from the database all the entries that belong to these routes and used them to form my own customized database. Just to get a sense of the magnitude of the data, the 61C has more than 700,000 entries alone.
The data was plotted in the following manner:
Each bus trip was plotted along the radius of a circle, from the center to the circumference. The angle relative to 12 o’clock is computed according to the time when a trip started. All 24 hours are covered in this diagram.
Each stop was represented as a circle whose area correlates with the number of people on the bus at that stop. To avoid clutter (remember, 700k trips!), I added a threshold of people requires to have a circle drawn. If the number of people is below the threshold, only a dot is printed. This allowed more significant patterns to be seen rather than just a clutter of overlapping circles.
Each bus route has different flavors. The more straightforward ones are inbound and outbound, but there are also five others which I have no data explaining their nature (but are also less significant). Each of these flavors was colored differently so the viewer can distinguish if patterns differ between these flavors.
In terms of interaction, the user can look at the different bus routes and alternate between them. In addition, for each chosen route, the user can adjust the threshold to see the impact of low vs. high threshold on the clarity of the data visualized in front of him.
Project’s value
During the exhibition I have witnessed two common responses to my work. First, was “… How did you get your hands on this data?…”, second was “.. This is pretty cool!”. For me, my mission was accomplished. My work has transformed a boring and inaccessible database sitting on a server at CMU to something available to the public in a way people can understand and see. The interactive portion of my application alongside my choice of popular lines encouraged visitors to explore and see the busses they use everyday in a way they have never seen before.
On another note, busses are part of the public transportation system. I am a strong believer in mass transit as a system the reduces pollution and traffic and acts as a social tool that allows all people to exercise their freedom to move, to work and to reach any service they require to lead a good and healthy life. I enjoyed working on something I care about and has a meaning to society rather than just be fun, cool or aesthetic.
Process
I made up my mind to do a data visualization project for my final piece and spent a significant amount of time until I came across the Port Authority database of buses. I was looking for a database large enough to challenge me and fit the scope of a final project, to hold the potential to answer intriguing questions and to be interesting to the general public.
It took me time to get hold of the data for technical reasons, but I knew beforehand, qualitatively, what kind of information is in the database. I was curious about bus occupancy, given the very unpleasant experience of standing at the bus stop and having been skipped by a passing bus more than once. I wanted to see if I could find patterns in bus occupancy and learn where and when does it occur.
I developed sketches of the data visualization I would like to make:

At first, i thought about visualizing the data in a linear way. Once I learned how big the database is, I dropped this idea.

Next, with the advice of my professor, I developed the circular visualization which I actually used for my project.
I used open frameworks, and started playing with randomly generated data to test my infrastructure and see what would be the best way to visualize this dataset:
I then switched to using the real data and experimented with color and shape sizes. I realized that color should be used sparingly and only when it serves a purpose, following are some of my experiments:



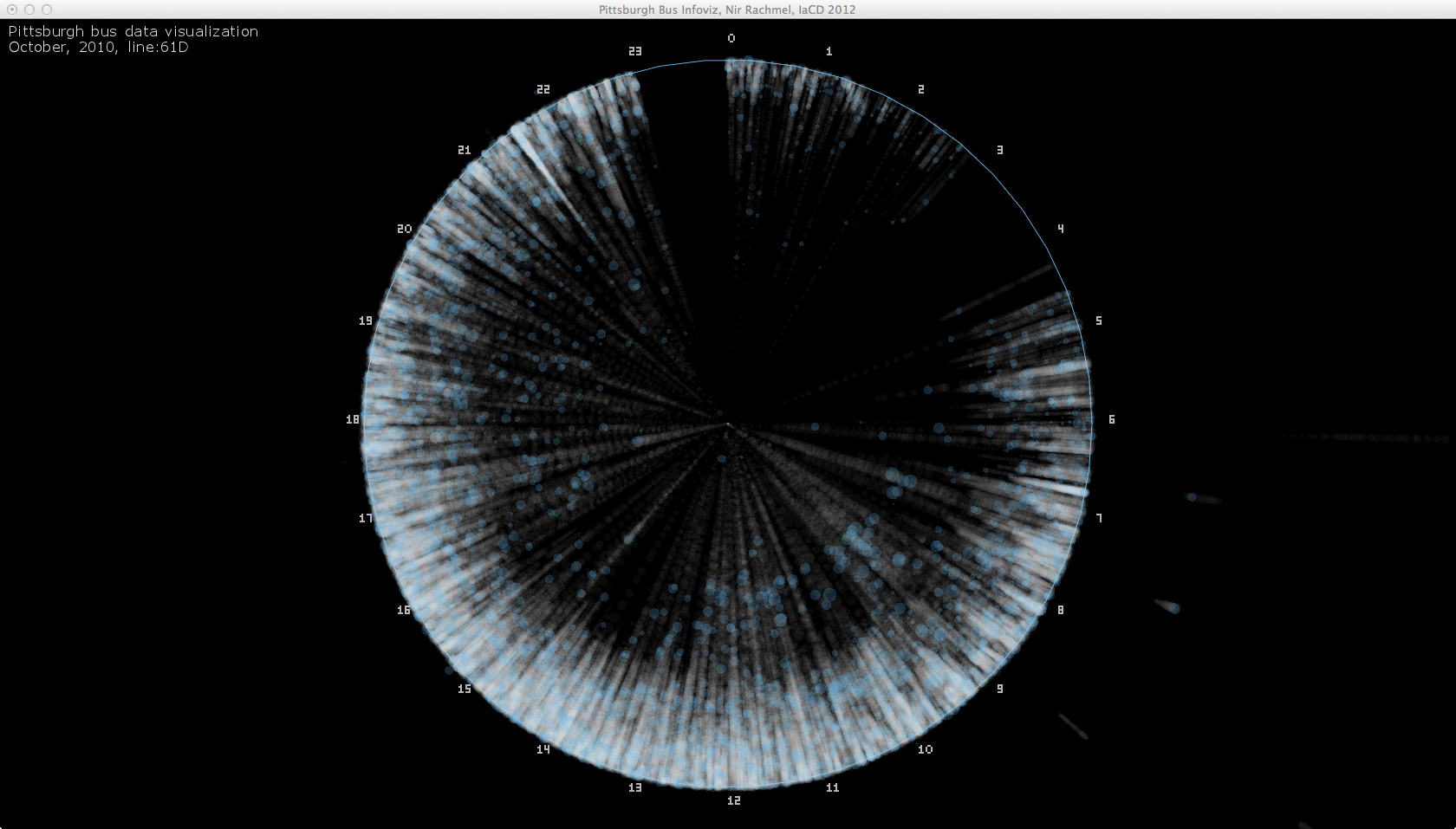

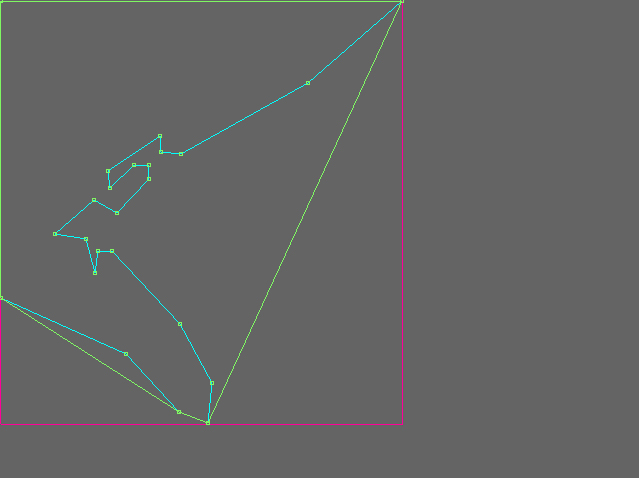
At this point I realized something is wrong. Looking at these visualizations, it seems as if the busses get full near the end of their trip, while I know that most of these busses get full somewhere in the middle of their trip.
Carefully examining the data and my code, I made some changes, and then this beautiful accident happened:

Finally, addressing these issues I came up with a reliable and working system that I can trust and experiment with.
In the following image you can see only the busiest stop colored and all the rest of the stops rendered but grayed, which still looks cluttered:
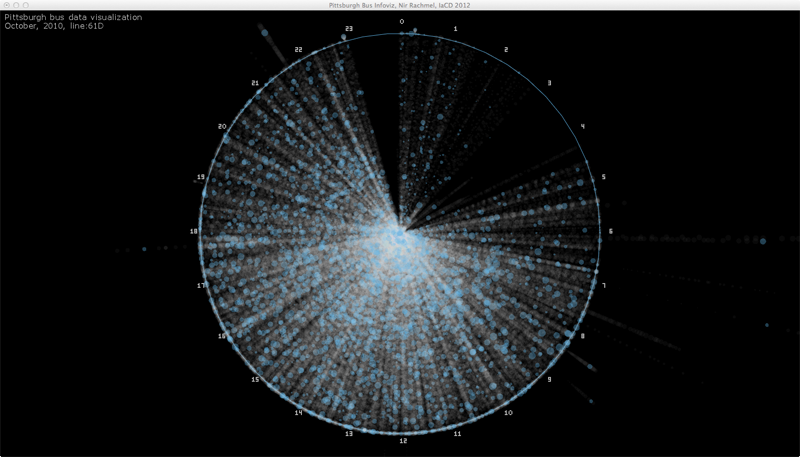
The following image shows only stops where the bus had more than 50 people on it in a blue circle. Every other stop is represented by a single, white pixel:

After playing with the rendering threshold, I realized that each bus route has a different volume of passengers. I also found that playing with this parameter can be fun and engaging for users. My final step towards completing this project was to add a slider so the users can control the threshold dynamically and a drop-down list to select which bus route to observe.
Before the final video, just a reminder of where we started from, and how the data “looks” like:
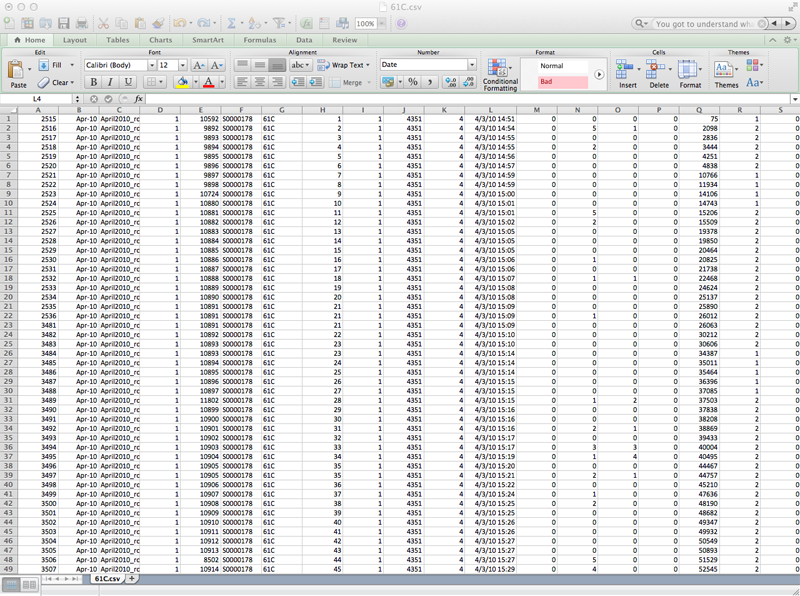


















































{kind=link}