Metonymy – Zachary Aman from Zachary Aman on Vimeo.
The goal of Metonymy is to create a user-centered graph exploration tool for Wikipedia. In my mind, Wikipedia is a modern world wonder; there is a vast quantity of information spread throughout Wikipedia, but it can be hard to find interesting articles without prior knowledge of the term you are looking for. The current method of finding new articles within Wikipedia often involves going to a page you know and then hopping around aimlessly, looking for something else that is interesting. This puts everything on a flat level, with no clear sense of hierarchy from the user perspective. In this project I built a Chrome extension that gives users the power of graph exploration, allowing them to use their own key articles as a sort of information triangulation tool.
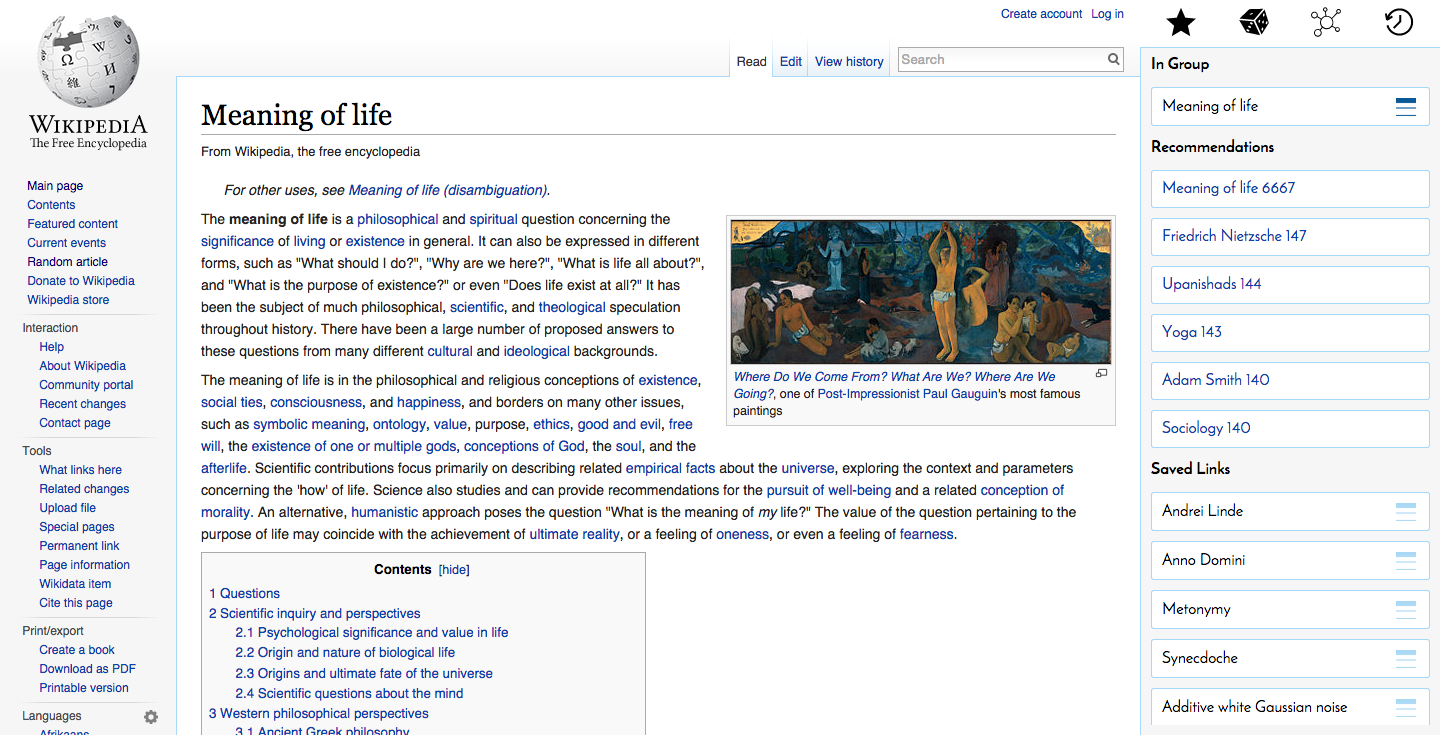
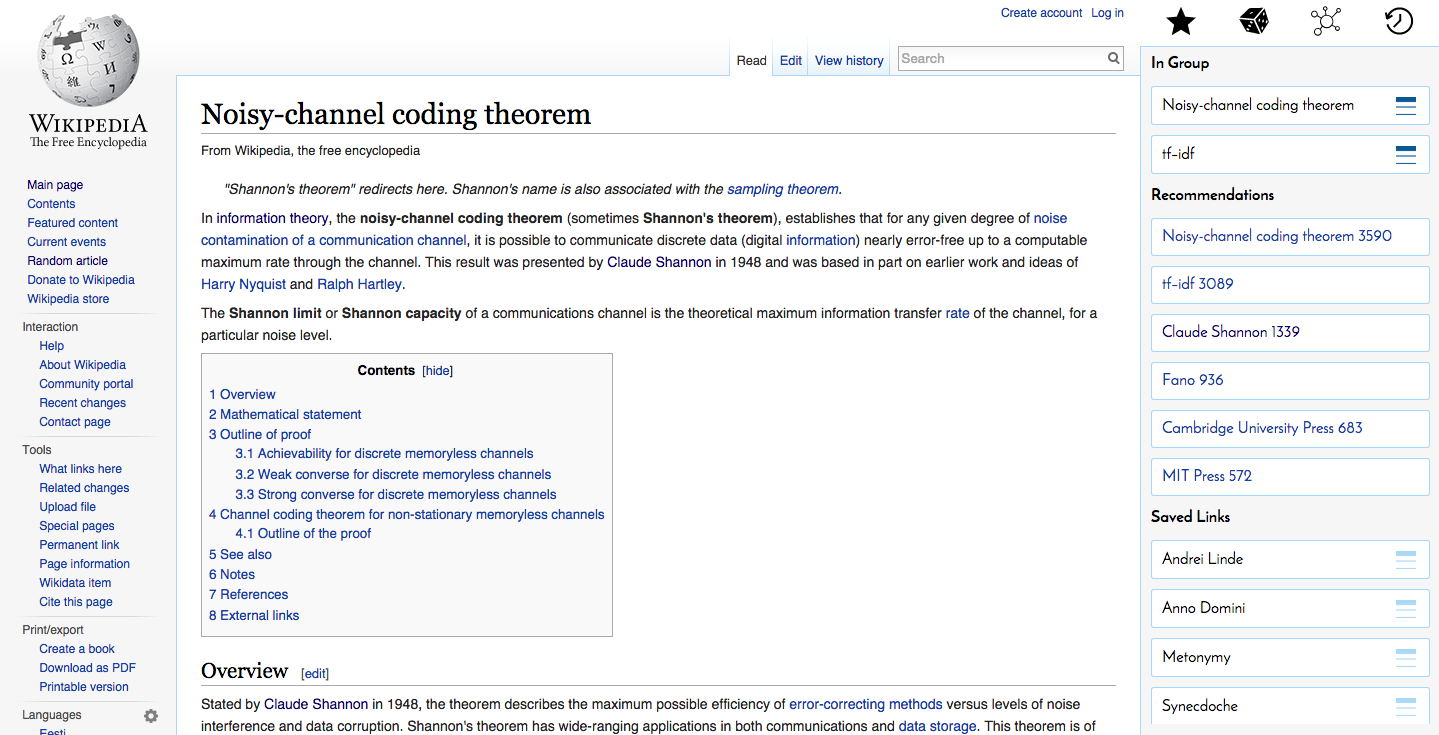
The user can select multiple links from their saved list to use for recommendation generation. If none are selected, it defaults to the current page.
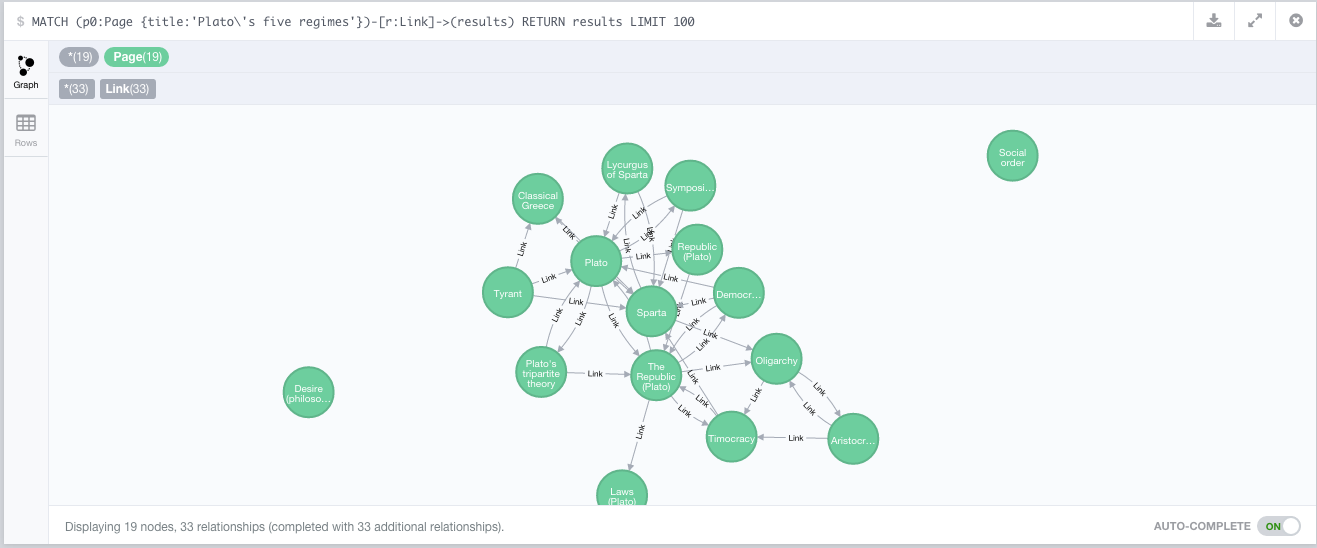
The Neo4j graph database I used to query the connections between articles. Credit to mirkonosato for his Graphipedia project that allowed me to build the database from the Wikipedia XML dump.
The main inspirations for this project were ‘Search, Show Context, Expand on Demand’: Supporting Large Graph Exploration with Degree-of-Interest by Ham and Perer (2009) and Apolo: Making Sense of Large Network Data by Combining Rich User Interaction and Machine Learning by Chau, Kittur, Hong, and Faloutsos (2011). The first paper uses graph analysis (article references as links) to surface relevant legal articles in a range from locally connected to current nodes to articles that are generally interesting. My initial conception of Metonymy was to do something very similar: provide a list of five articles a day that range from local gaps in your knowledge graph to articles that are highly connected and of general interest. The Apolo paper I found inspirational for the way they approach the graph interface; the authors allow users to set “archetypal” articles as a way of defining clusters.
I was pleased by how relevant the recommendations could be and simply being able to keep track of what I have looked at is immensely helpful; if by no other metric, I would call this project a success by the fact that it is something I will actually use. Beyond that, I learned how to build a chrome extension (something I’ve been interested in for a while now) and got to focus on algorithms and architecture, two areas that I think I need the most work in as a programmer. I’ve always been somewhat scared of algorithms — it’s not that I can’t hack something together, but being in a computer science program really puts the fear of scale into you. The recommendation engine certainly isn’t fast, but getting to work on an algorithm with multiple threads and filtering mechanisms was a lot of fun.
The main thing I would like to continue working on is the interface, specifically allowing a way to cluster saved items (probably sharing control with an algorithm). The existing form is serviceable, but not great, though I do want to keep it in a sidebar form which limits how much interactive space you have at a time. Under the hood, the speed could be improved and the code definitely needs refactoring — I now have three different “get recommendations” functions that are all slightly different but mostly the same. The algorithm could also be tweaked endlessly; it works pretty well for a single article but I think it needs to weight articles based on higher connectivity to multiple in-group articles to be more effective for clusters.