My project, working titled re:us is a chat app which automatically converts every message sent to a rebus (a series of images clueing the message, like the one below). I’ll do this using some part-of-speech/pronunciation parsing from Rita.js, and images from The Noun Project.
To be or not to be…
Though I think this idea is really fun, and I have ideas for how to do the message-to-rebus transformation, I am having a lot of trouble getting the basic software for a chat app working. I have never really used servers or databases like this before, and feel a bit overwhelmed. I haven’t been able to put the necessary time into the app so far, and might have to use a pass on this assignment, but I hope not! I’d love to see this completed.
At the beginning of this projects I was attempting to ideate concepts for the interactive manufactory prompt; trying to come up with a way to use my genetic code and literal code to create a manufactory piece of art, and after much preliminary research on what people have already been doing in relation to genome art I have decided that it’s too easy to come up with another dumb idea and this is the kind of project that should brew in the back of your mind for awhile…
So I switched gears and started to work on the foundation for a telematic project.
To lay down a basis for my project I should first talk about what sparked my interest in doing this… in recent months, I’ve found myself to be quite frustrated to be quite frustrated with the fact that during video chatting sessions, My father always seems to be looking at himself. It’s clear that his gaze isn’t directed towards me because he only looks at me when I say something that really grabs his attention. Through conducting interviews I found that this seems to be a major pain-point for the population of people who have interacted with him over Skype.
In light of this frustration I wanted to make a video chatting interface specifically meant to communicate with him (or people like him who are blatantly checking themselves out the entire time you are engaging with them…) I decided that it would be fun to go down the path of obstructing his own view of himself during these sessions so that he would be forced to stop looking at himself. Some examples being:
His face gets smaller, and smaller, the longer he stares at himself
His face disappears and re-appears in each of my pupils on his screen so that he will be more inclined to look me in the eye
His phone (fondly referred to as “Lil’ Debbie”) vibrates violently when ever he looks at his own image.
The sound on his end goes completely mute and he hears nothing until he is making eye contact again
And other such fun interactions (always open to suggestions)
So far I am in the process of developing the gaze tracking process locally (through the use of openCV and processing). I hope to have that completely worked out by Friday so that I might begin to establish a way of interfacing and sharing video between himself and I and from there modify the way that the program responds to his obsession with his likeness.
My telematic project is an online cairn where visitors collectively write a poem by adding or modifying lines of prose. Each line has a fixed last word that either rhymes with the previous line’s last word or does not. This app is implemented on glitch.com using JQuery, Socket.io, Sequelize, and possibly Rita.js.
So far I have set up the networking and database interactions as well as the webpage styling, but I am stuck on the details of how to design this idea. A couple variations I have in mind include:
A grid-based cairn. Internally, lines are stored in a 2D grid where one axis represents the depth of rhymes and the depth of non-rhymes. Each visitor would start at with the line at (0,0) and add to their poem by choosing whether the next line should rhyme or not rhyme. When the visitor stumbles across an empty cell in the matrix, the visitor can create a line at that location. The visitor may choose to print the poem generated by the traversal through the matrix.
A cairn with only 10 or so lines. Visitors can write (or rewrite) the text leading up to the last word of a line. Visitors can alternatively toggle the last word of a line. Each visitor may only do one of these two actions.
I think the latter idea is both more interesting and easier to implement, but the more I think about this the more alternatives pop up in my head. Regardless, I will probably advance this project in the second direction.
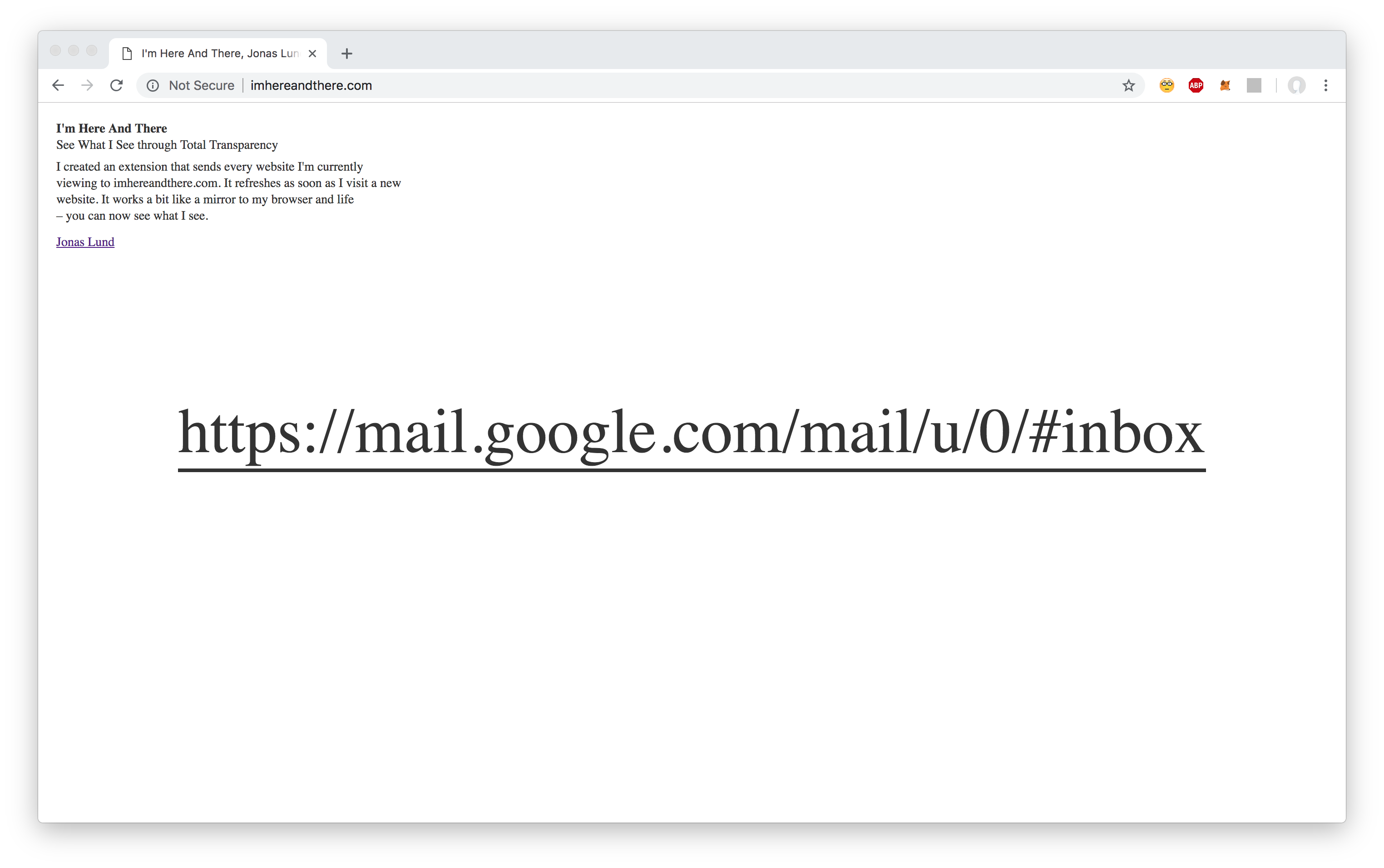
In I’m Here and There, Jonas Lund creates and uses a custom browser extension that reports every website he visits to http://imhereandthere.com/. I chose this as a Looking Outwards for my project because I’m interested in the idea of opting in to a cairn as a participant. There is nothing inherently tying the browser extension to Lund specifically in this project, so I imagined a version of this project where the browser extension was a public software that any user install and therefore opt in to. While this act of opting in is inherent in many of the telematic cairns we viewed in class, I’m interested in exploring this choice in particular.
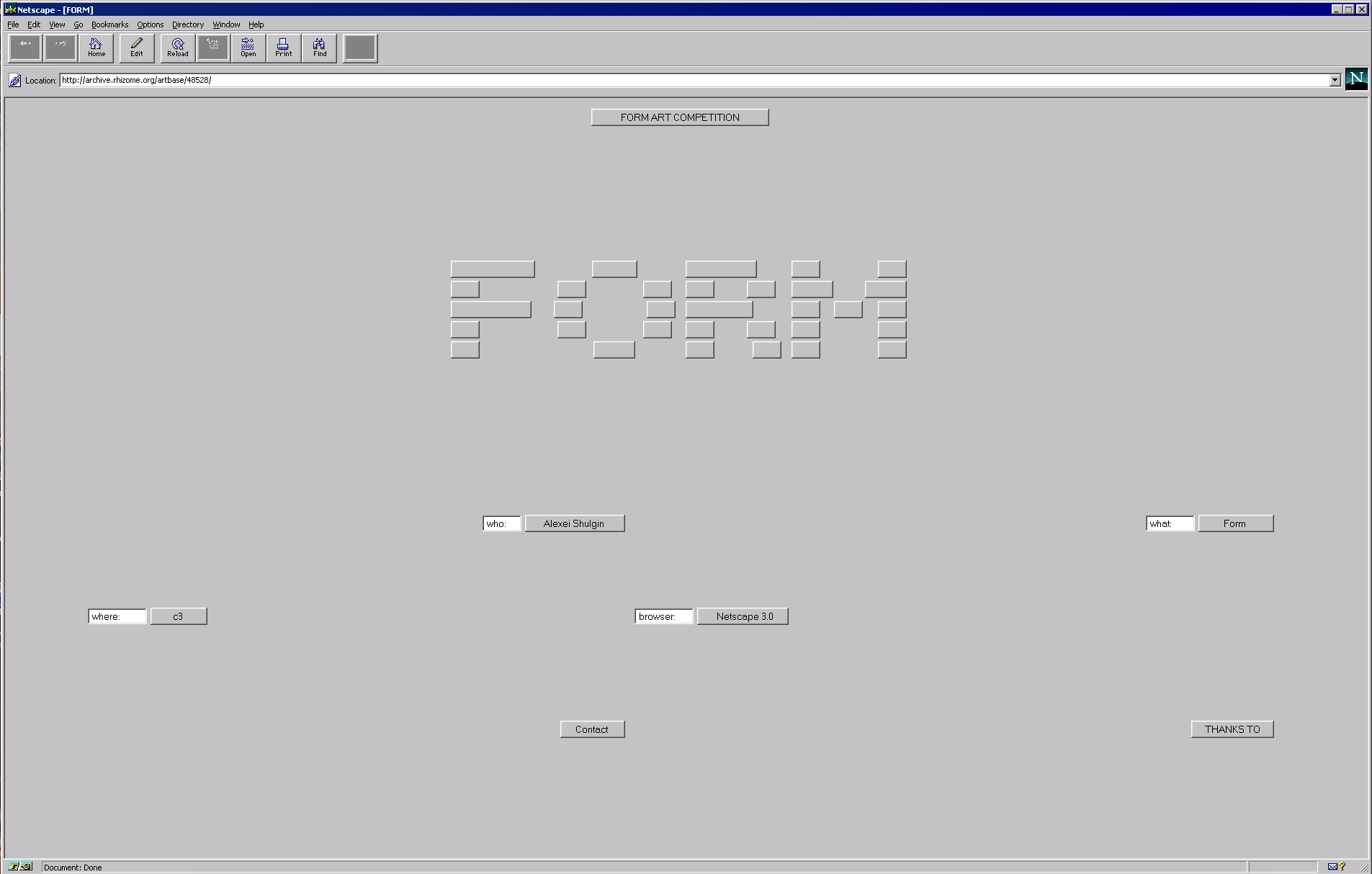
Form Art is Alexei Shulgin’s exploration of mundane HTML buttons and boxes as compositions. With this project also came a short-lived submission-driven competition wherein users were allowed to create their own form art. I chose this work as a Looking Outwards because I was immediately attracted to the abstract, reductive yet nostalgic visuals. I was also inspired by the concept of the button as an artistic element–as an abstract force that pushes you down a certain path. Viewing this work brought up strong memories of interactive texts, such as email, collaborative writing tools and text games. That Shulgin opens his idea and art form to user submissions is particularly important to my reception of Form Art as Internet art.
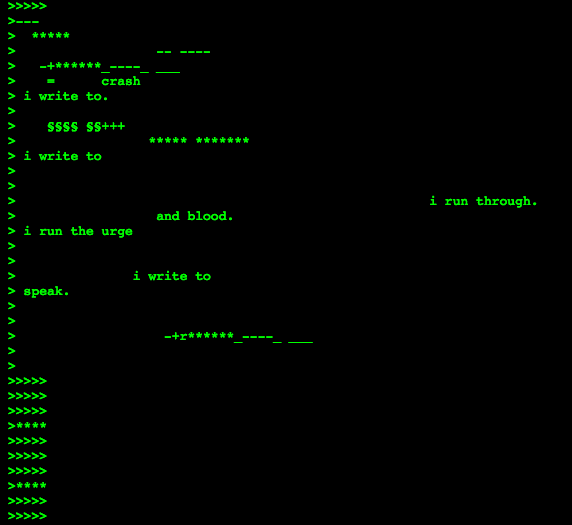
I’m attracted to Mez Breeze’s Mezangelle for the same reasons as Form Art. I enjoy the poetry that arises from the reductiveness of the green terminal text, as well as the palpable undercurrent of programmatic rules that drives it. This work reminds me of the concept of readable code and code poetry. Much like using the HTML button as an artistic unit, I am fascinated by the idea of using functional blocks of text as modular visual elements.
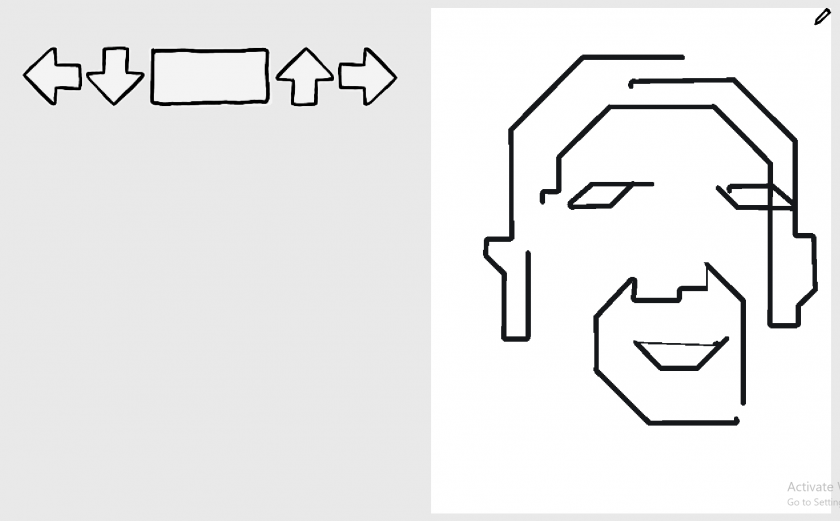
My project for the drawing software assignment is a DDR-inspired drawing game. A cursor moves at a constant rate on a canvas. You must hit D (left), F (down), J (up), K (right) or SPACE (draw/stop) according to the arrow prompts in order to direct the cursor and draw an image. I prototyped this idea in Unity.
drawing-game
My conceptual starting point was agency in drawing. I thought about paint-by-numbers, trace-the-line games–activities that simulate drawing without any of the creativity and decision-making associated with drawing. I also thought about the distinction between art and craft, which is a tension I am very familiar with as someone who is more of a maker than a creator. I was reminded of instruction-based games like Dance Dance Revolution and typing games, which lead to a natural connection to chain codes in vector drawings. After switching back and forth between project ideas that only frustrated me, I settled on my final idea: a DDR-inspired drawing game.
As I developed the prototype, I became excited about unexpected conditions that the DDR system enforced. The importance of timing in rhythm games translated to the importance of proportions and length with contour drawing. The sequential nature of the instruction prompts forces mistakes to stack–one missed draw/stop prompt can invert the drawn lines and the travel lines for the rest of the level. Additionally, I chose to implement diagonal movement as hitting two arrows at the same time. If these two arrows are not hit simultaneously, the cursor will travel in the direction of the last arrow hit instead of the resulting diagonal.
These gameplay conditions that arise from just a rough reimplementation of DDR mechanics are already exciting, so I hope to expand this project either as a personal undertaking or as a capstone in the future. I hope to open this idea to sharing, collaboration and multiplayer play. My primary goal would be to create an interactive level-builder tool in order to allow people to create their own drawing sequences and share them. I also hope to explore paint-fill combo mechanics and utilizing non-Cartesian mappings.
“How will we change the way we think about objects, once we can become one ourselves?” – Simone Rebaudengo
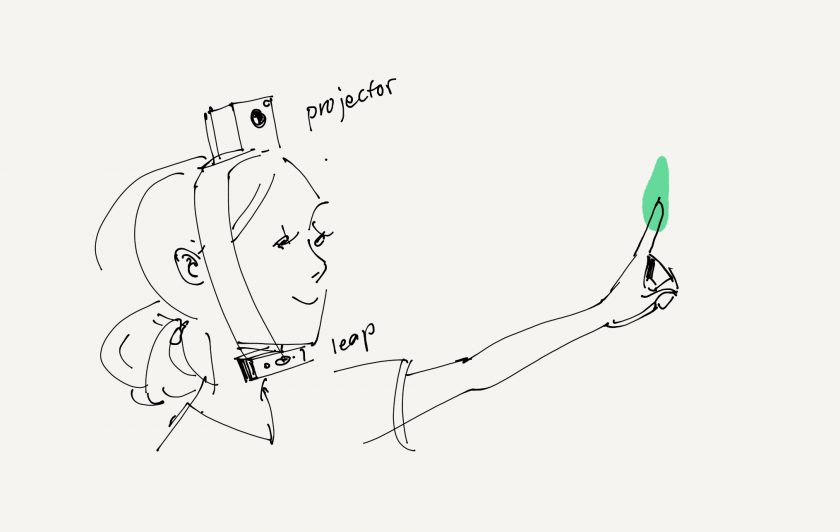
The aim of this project is to leverage a surprisingly available technology, the Wacom tablet, in order to change one’s perspective on drawing. By placing you’re view right at the tip of the pen, mirroring your every tiny hand gesture, scale changes meaning and drawing becomes a lot more visceral.
Part of this is every micro movement of your hand (precision limited by the wacom tablet) becoming magnified to alter the pose of your camera. Furthermore, having such a direct, scaled connection between your hand and your POV allows you to do interesting things with where your looking.
Technical Implementation
I wrote a processing application that uses the tablet library to read the wacom’s data as you draw. From there, it also records the most precise version of your drawing to the canvas as well as sends the pen’s pose data to the VR headset over OSC.
Note: One thing that the wacom cannot send right now is the pen’s rotation, or absolute heading. However, the wacom art pen can enable this capabilities with one line of code.
The VR app interprets the OSC messages and poses a camera accordingly. The Unity app also has a drawing canvas inside as well, and your drawing is mirrored to that canvas through the pen position + pen down signals. This section is still a work in progress, as I only found too late (and after much experimentation) that it’s much easier to smooth the cursors path in screen space and then project it onto the mesh.
The sound was done using granulation of pre recorded audio of pens and pencils writing in Unity3D. This causes some performance issues on Android and I may have to look into scaling this back.
My goal was to train a model to draw like I do (see sketchbook except below)
Input: I drew 1200 friends:
I wrote a quick p5 sketch that stores the data in 3stroke format, which keeps track of the difference in x & y of each point , and weather or not a specific point is the first point in a stroke or not.
I used SketchRNN, and trained my own model off of the drawings I did. This was the first result I got as output, and so far the only one with a distinguishable face
Other models as I’ve adjusted variables in the output:
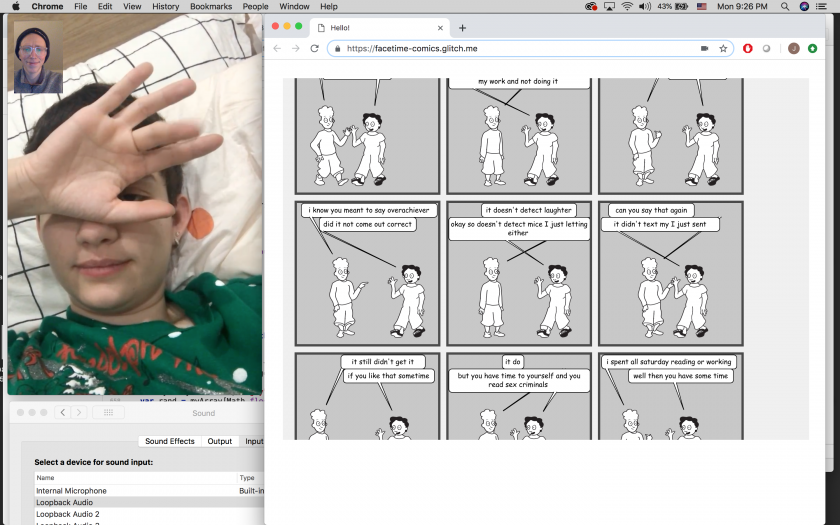
This project seeks to update Microsoft’s Comic Chat for transcribing video chat (Facetime-non specific).
I’ve developed it to generate a comic book that features cartoons based on myself and my girlfriend. (Although, as in the above example, it can just be me in the comic.)
The software lays out characters, sizes them, lays out speech bubbles, and poses the characters dynamically.
The basis for this project looks like this:
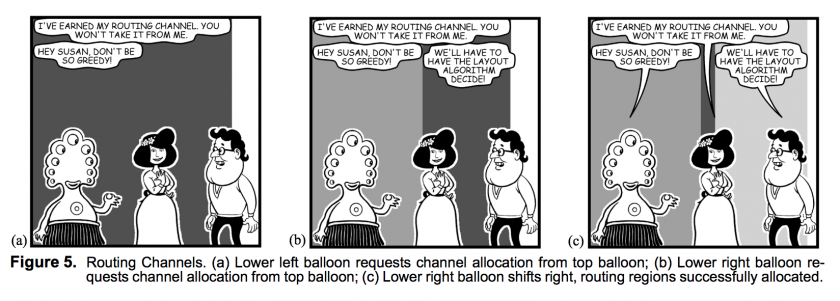
Microsoft deployed this feature for typed web chats in 1996. They also produced a paper documenting that project and how they accomplished some of its technical features, like using routing channels to layout speech bubbles:
Which, I’ve been able to more or less implement myself:
The Microsoft project also tried to attain a semantic understanding of its conversations, and respond accordingly. While it and my program respond to speaker input based on a limited library of words (waving, for example, when someone says “Hi”), a deeper understanding of conversational meaning was something the Microsoft team could not accomplish and that I failed to realize as well. I do think it’s possible today, however, given the availability of wider libraries for programmatically generated language, to respond much more deeply to the spoken words in a conversation.
My character, responding to the spoken word, “love.”
My other inspiration for this work was Scott McCloud’s Understanding Comics, particularly his chapter on “Closure.”
We infer that the attacked happened in the space in between the panels.
McCloud considers the space in between panels, and how we read that space and infer what’s happening, as a unique quality of comics. He calls this “closure.” McCloud says that it’s present in video too, but at 24fps, the space in between “panels” is so little that the inferences we make between them are completely unconscious. Because of this, I think comics are a fitting transcription for video chat, as opposed to straight recording, because by limiting the frames shown, they open up the memory of the conversation to new interpretations.
In evaluating my project, I wanted to implement a lot more. I wanted, for example, to base the emotions expressed by my characters on realtime face analysis or a deeper understanding of the meaning of the text. I also didn’t get to variable panel dimensions, and this is a small sign, for me, that I didn’t get past just recreating Microsoft’s project. It assumes an Internet-comic aesthetic right now, and I wish it had more refinement, and maybe more specificity to my style; there’s a little Bitmoji in the feeling of the character sheet above, and I don’t know how I feel about that.
so. I didn’t end up liking any of my iterations or branches well enough to own up to them. I took a pass when my other deadlines came up but I had a lot of fun during this process!
^ the above inspired by some MIT Media Lab work, including but not limited to —
Some technical decisions made and remade:
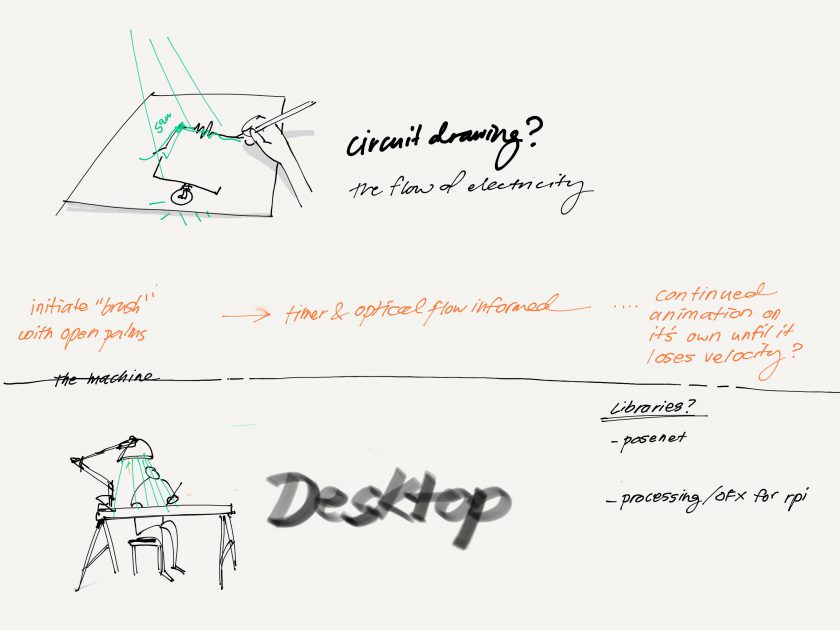
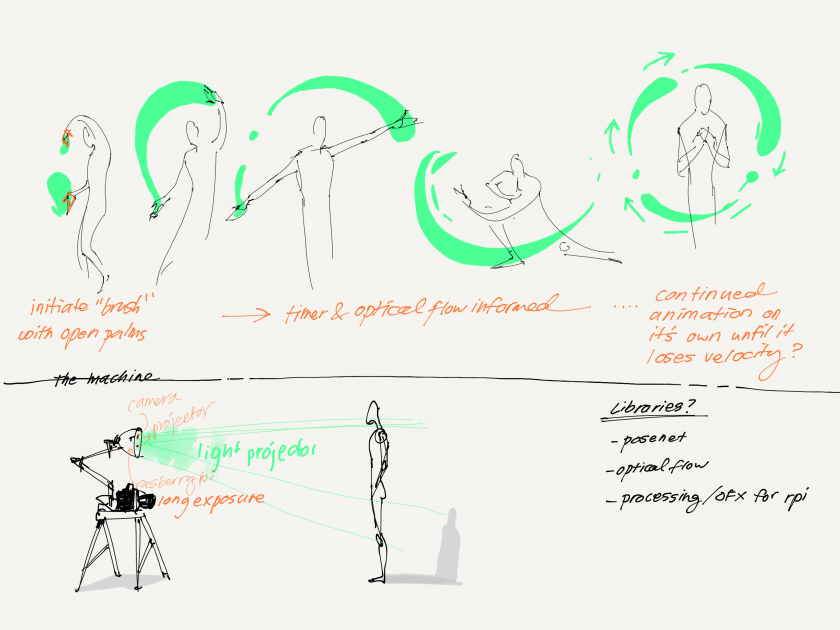
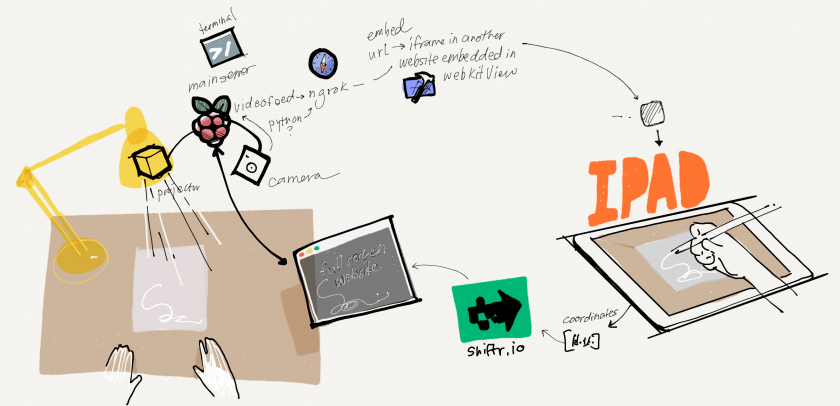
welp. I really liked the self-contained nature of a CV aided projector as my ‘machine’ for drawing so I gathered all 20+ parts —
when your cords are too short.
printed somethings, lost a lot of screws…and decided my first prototype was technically a little jank. I wanted to try and be more robust so I got started looking for better libraries (WEBrtc) and platforms. I ended up flashing the Android Things Operating System (instead of raspbian) onto the Pi. This OS is one that Google has made specially for IoT projects with integration and control through a mobile android—
and then along the way I found a company that has already executed on the projection table lamp for productivity purposes —
I had to really stop and think about what I hoped to achieve with this project because somewhere out in the world there was already a more robust system/product being produced. The idea wasn’t particularly novel even if I believed I could make some really good micro interactions and UX flows, so I wasn’t contributing to a collective imagination either. So what was left? The performance? But then I’d be relying on the artist’s drawing skills to provide merit to the performance, not my actual piece.
Worry about the hardware after the software interactions are MVP, UNLESS! Unless the hardware is specially made for a particular software purpose (i.e. PiXY Cam with firmware and optimized HSB detection on device)
ex: So. 60 Lumens didn’t mean anything to me before purchasing all the parts for this project, but I learned that the big boy projector used in the Miller for exhibitions is 1500+ lumens. My tiny laser projector does very poorly in the optimal OpenCV lighting settings, so I might have misspent a lot of effort trying to make everything a cohesive self-contained machine…haha.
ex: PixyCam is hardware optimized for HSB object detection!
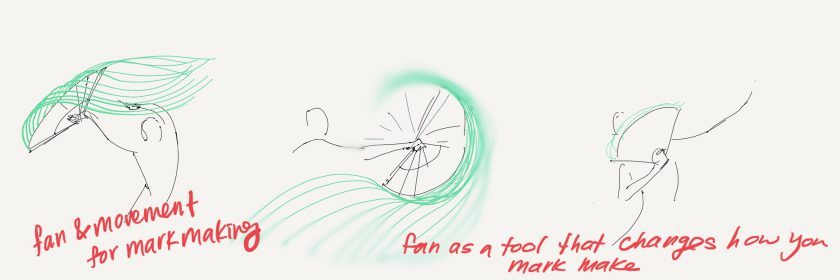
ex: So back to the fan brush idea testing some HSB detection and getting around to implementing a threshold based region growing algorithm for getting the exact shape…
Some romancing with math and geometry again
Gray showed me some of his research papers from his undergrad! Wow, such inspiration! I was bouncing out ideas for the body as a harmonographer or cycloid machine, and he suggested prototyping formulaic mutations, parameters, and animation in GeoGebra and life has been gucci ever since.
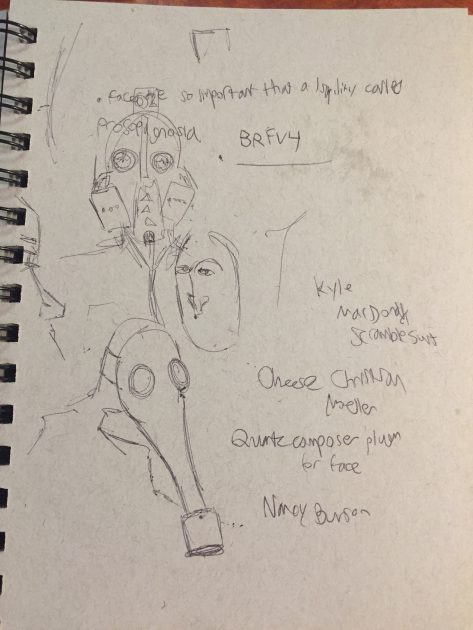
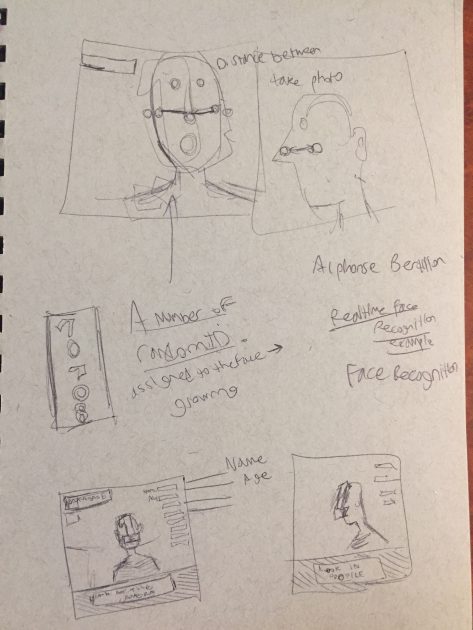
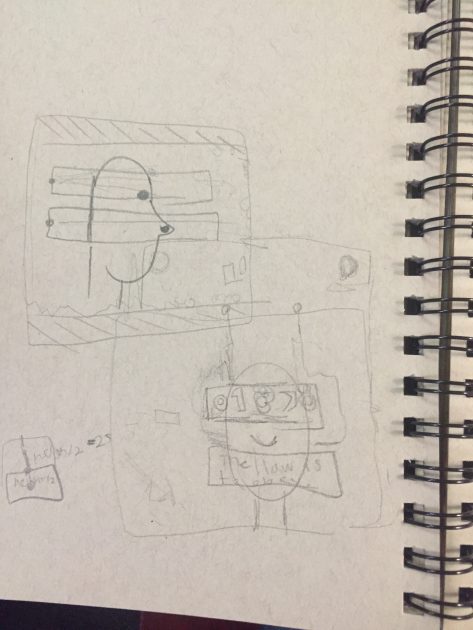
This is called Bertillon’s Dungeon. It’s designed to be a small interactive piece about surveillance and facial recognition. I was thinking about glut and the importance to business of sourcing faces as often as possible. I was thinking of mugshots and how they were used to profile criminals by their inventor, Bertillon until DNA testing outmoded them. Yet, we still use mugshots as a shorthand for being in the system. Though this was a small project, simple in nature, I reason that it could be expanded to be a smaller part of a larger story about facial recognition software. I also think it was important in my performance to try and hide my face when the pictures started getting taken, but to be sort of dazed and confused before the realization. I wanted to be someone who understood the motive behind the taking of the pictures (most likely to be used in court for incrimination), but still was conditioned to respect authority (even if they are trying to log into something they shouldn’t be).
Sound wasn’t done in the p5.js sketch. It was done for the documentation in logic. I would want to improve this by having the sound play in the browser.
I started by thinking about a gasmask in which obvious breathing was needed to stay alive- a melding between human and machine. This eventually became a number emblazoned on the head, which eventually became the assigning of an ID. I was initially thinking of also having real time facial recognition (or approximations) but this was going to take too much time. The idea of a multi roll of cameras came from watching Dan Schiffman’s Muybridge tutorial and thinking about an interesting transition.