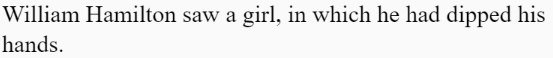// COOKIE
// points for the cookie
var x1, x2, x3, x4, x5, x6, x7, x8, x9;
// TAKEOUT BOX
//variables for box points
var tx1,ty1,tx2,ty1,tx3,ty3,tx4,ty4,tx5,ty5,tx6,ty6,tx7,ty7;
//visible flap vertex points
var fx, fy;
//variablesfor handle points
var hx1, hy1, hx2, hy2, hx3, hy3, hx4, hy4;
//RiTA stuff
var rg;
var name, lengthChance, typeChance; // variables for generated restaurant name
var myFont; // custom font
var luckyNums = []; // array of lucky numbers
var prediction = ''; // fortune cookie fortune/prediction
var phoneNumber = ''; // phone number
function preload() {
myFont = loadFont('andale-mono.otf');
chineseFont = loadFont('chinese.ttf')
}
function setup() {
createCanvas(500, 680);
background(239, 50, 40); // red color
background(240);
noLoop();
// assign values to lengthChance and typeChance
lengthChance = random(0,100);
typeChance = random(0,100);
// generate restaurant name
name = generateRestaurantName();
// display restaurant name text
displayRestaurantName();
// generate phone number
generatePhoneNumber();
drawPhoneNumber();
// draw slip of paper
drawPaper();
// generate lucky numbers
generateLuckyNumbers();
drawLuckyNumbers();
// display the fortune
drawFortune();
// generate and draw box
generateBox();
drawBox();
// generate cookie
generateCookie();
// draw the cookie
drawCookie();
prediction = generateFortune();
// button to download json file
createJSONFile();
}
function mousePressed() { // generate new cookie, restaurant name, and fortune on mouse press
setup();
}
function generateRestaurantName() { // returns string of generated Restaurant name
name = "";
// Places 11
var places = ["Beijing", "Peking", "Szechuan", "Shanghai", "Hunan", "Canton", "Hong Kong", "Taipei", "China", "Taiwan", "Formosa"]
// Adjectives 14
var adj = ["Lucky", "Golden", "Gourmet", "Imperial", "Oriental", "Grand", "Mandarin", "Supreme", "Royal", "East", "Old", "Happy", "Hot", "Chinese"]
// Nouns 18
var noun = ["Cat", "Moon", "Sun", "Dragon", "Star", "Roll", "Panda", "Bamboo", "Chef", "King", "Empire", "Empress", "Emperor", "Phoenix", "Lion", "Tiger", "Jade", "Pearl"]
// Food 7
var food = ["Seafood", "Noodle", "Dim Sum", "Hot Pot", "Rice", "Ramen", "Hibachi"]
// Last words 13
var last = ["Palace", "Garden", "Cafe", "Bistro", "Kitchen", "Restaurant", "Buffet", "House", "Wok", "Bowl", "Grill", "Cuisine", "Express"];
// Generate some random names
if (lengthChance >= 0 && lengthChance <= 25) { // two word length
if (typeChance >= 0 && typeChance <= 17) {
name += places [floor(random(11))] + " ";
name += noun [floor(random(18))];
}
else if (typeChance > 17 && typeChance <= 34) {
name += adj [floor(random(14))] + " ";
name += noun [floor(random(18))];
}
else if (typeChance > 34 && typeChance <= 51) {
name += food [floor(random(7))] + " ";
name += last [floor(random(13))];
}
else if (typeChance > 51 && typeChance <= 68) {
name += adj [floor(random(14))] + " ";
name += last [floor(random(13))];
}
else if (typeChance > 68 && typeChance <= 85) {
name += adj [floor(random(14))] + " ";
name += food [floor(random(7))];
}
else if (typeChance > 85) {
name += places [floor(random(11))] + " ";
name += last [floor(random(13))];
}
}
else if (lengthChance > 25 && lengthChance <= 50) { // three word length
if (typeChance >= 0) {
name += places [floor(random(11))] + " ";
name += noun [floor(random(18))] + " ";
name += last [floor(random(13))];
}
else if (typeChance > 17 && typeChance <= 34) {
name += adj [floor(random(14))] + " ";
name += noun [floor(random(18))] + " ";
name += last [floor(random(13))];
}
else if (typeChance > 34 && typeChance <= 51) {
name += adj [floor(random(14))] + " ";
name += places [floor(random(11))] + " ";
name += noun [floor(random(18))];
}
else if (typeChance > 51 && typeChance <= 68) {
name += adj [floor(random(14))] + " ";
name += noun [floor(random(18))] + " ";
name += food [floor(random(7))];
}
else if (typeChance > 68 && typeChance <= 85) {
name += places [floor(random(11))] + " ";
name += food [floor(random(7))] + " ";
name += last [floor(random(13))];
}
else if (typeChance > 85 ) {
name += adj [floor(random(11))] + " ";
name += food [floor(random(7))] + " ";
name += last [floor(random(13))];
}
}
else if (lengthChance > 50 && lengthChance <= 75 ) { // four word length
if (typeChance >= 0 && typeChance <= 20) {
name += places [floor(random(11))] + " ";
name += adj [floor(random(14))] + " ";
name += noun [floor(random(18))] + " ";
name += last [floor(random(13))];
}
else if (typeChance > 20 && typeChance <= 40) {
name += places [floor(random(11))] + " ";
name += adj [floor(random(14))] + " ";
name += food [floor(random(7))] + " ";
name += last [floor(random(13))];
}
else if (typeChance > 40 && typeChance <= 60) {
name += adj [floor(random(14))] + " ";
name += noun [floor(random(18))] + " ";
name += food [floor(random(7))] + " ";
name += last [floor(random(13))];
}
else if (typeChance > 60 && typeChance <= 80) {
name += places [floor(random(11))] + " ";
name += noun [floor(random(18))] + " ";
name += food [floor(random(7))] + " ";
name += last [floor(random(13))];
}
else if (typeChance > 80) {
name += adj [floor(random(14))] + " ";
name += food [floor(random(7))] + " ";
name += places [floor(random(11))] + " ";
name += last [floor(random(13))];
}
}
else if (lengthChance > 75) { // five word length
if (typeChance >= 0 && typeChance <= 40) {
name += places [floor(random(11))] + " ";
name += adj [floor(random(14))] + " ";
name += noun [floor(random(18))] + " ";
name += food [floor(random(7))] + " ";
name += last [floor(random(13))];
}
else if (typeChance > 40 && typeChance <= 60) {
name += adj [floor(random(14))] + " ";
name += food [floor(random(7))] + " ";
name += noun [floor(random(18))] + " ";
name += places [floor(random(7))] + " ";
name += last [floor(random(13))];
}
else if (typeChance > 60) {
name += adj [floor(random(14))] + " ";
name += noun [floor(random(18))] + " ";
name += places [floor(random(11))] + " ";
name += food [floor(random(7))] + " ";
name += last [floor(random(13))];
}
}
return name;
}
function displayRestaurantName() {
textAlign(LEFT);
textFont(myFont);
fill(0);
textSize(12);
noStroke();
text(name, 40, 50);
}
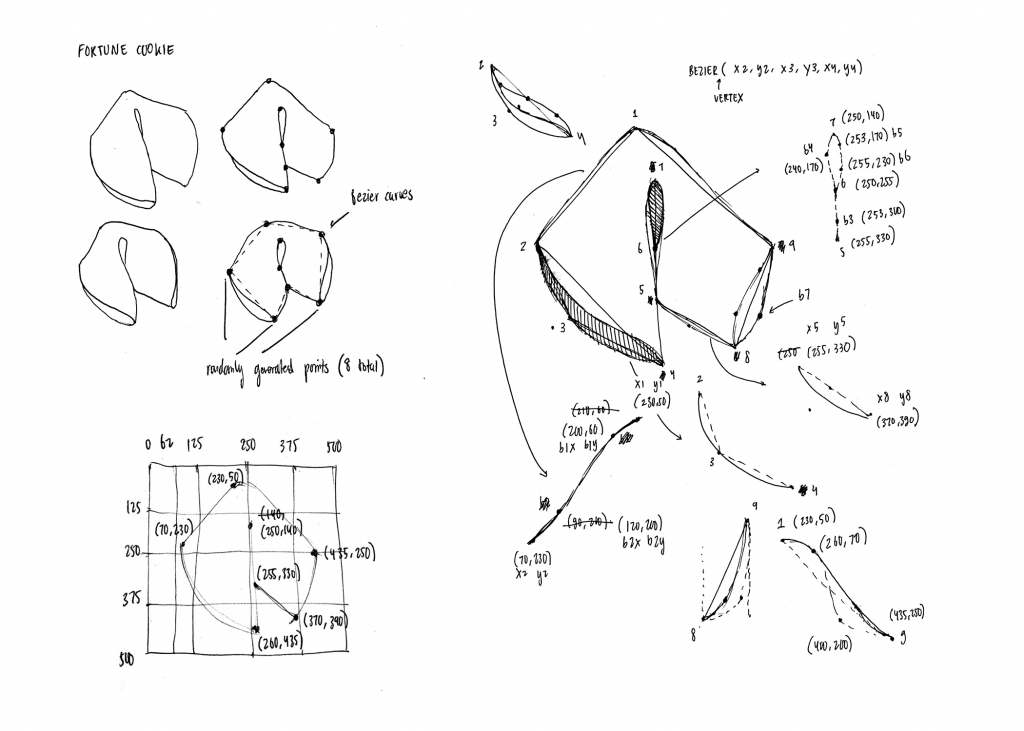
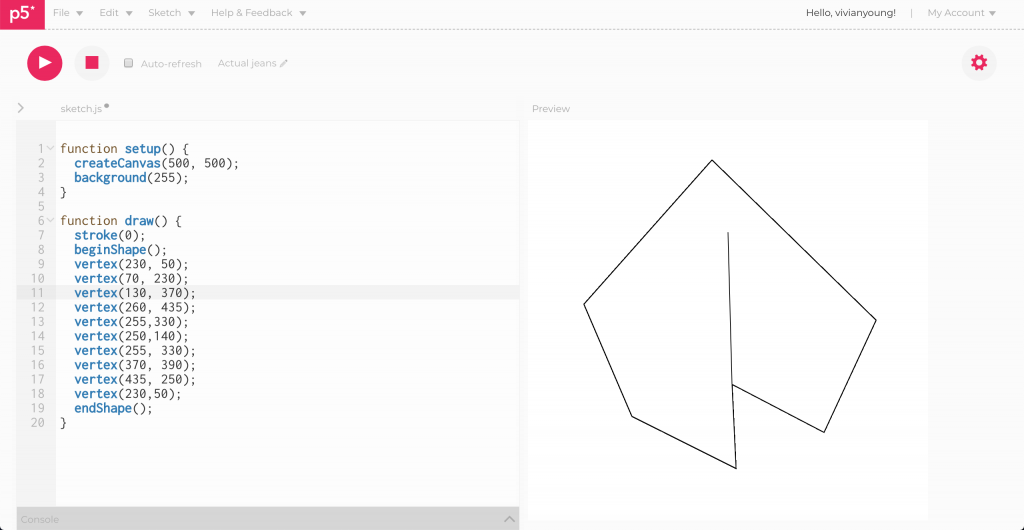
function generateCookie() { // generate points for the cookie
// generate random points for fortune cookie
x1 = width/2 - random(15,25);
y1 = random(50,80);
x2 = random(60, 78);
y2 = random(225, 245);
x3 = x2 - random(10,15);
y3 = random(360, 380);
x4 = 260;
y4 = random(420,440);
x5 = 255;
y5 = random(300,350);
x6 = 252;
y6 = y5 - 65;
x7 = 250;
y7 = random(140,160);
x8 = random(380, 390);
y8 = random(390, 420);
x9 = x8 + random(20,35);
y9 = y2 - 20;
// bezier vertices
b1x = x1 - random(90,130);
b1y = y1 + random(8,13);
b2x = x2 + random(40,50);
b2y = y2 - random(40,60);
b3x = x5 + random(5, 8);
b3y = (y5 - y6) * 0.9 + y6
b4x = x6 - random(25,35);
b4y = random(155,170);
b5x = x7 + random(15,20);
b5y = y7 + random(20,30);
b6x = x6 + random(5,15);
b6y = y6 - random(25,40);
}
function drawCookie() {
push();
translate(80,280);
scale(0.35);
stroke(0);
// fill(247, 237, 185); // beige color
fill(255);
strokeWeight(4);
// left half of cookie
beginShape();
vertex(x1, y1);
bezierVertex(b1x, b1y, b2x, b2y, x2, y2);
vertex(x2, y2);
bezierVertex(x2,y2,x3,y3,x4,y4);
vertex(x4, y4);
vertex(x5, y5);
bezierVertex(x5, y5, b3x, b3y, x6,y6);
endShape();
// right half of cookie
beginShape();
vertex(x5,y5);
bezierVertex(x5,y5,(x5+x8)/2 - 10,(y5+y8)/2 + 10,x8,y8);
vertex(x8, y8);
bezierVertex(x8,y8, (x9-x8)*1.4+x8, (y8 - y9) * 0.9 + y9 ,x9,y9);
vertex(x9, y9);
bezierVertex(x9-80, y9 -50, x1 + 90, y1 + 20, x1, y1);
vertex(x1, y1);
endShape();
// inner crease
beginShape();
fill(0);
vertex(x6,y6);
bezierVertex(x6,x6,b4x,b4y,x7,y7);
vertex(x7,y7);
bezierVertex(b5x,b5y,b6x,b6y,x6,y6);
vertex(x6,y6);
endShape();
// left fold of cookie
fill(0);
beginShape();
vertex(x2, y2);
bezierVertex(x2,y2,x3,y3,x4,y4);
vertex(x4, y4);
bezierVertex(x4, y4, x4-20, y4-35, (x2+x4)/2 - 15, (y2+y4)/2 + 15);
bezierVertex((x2+x4)/2 - 15, (y2+y4)/2 + 15, x2 +10, y2 +80, x2, y2);
vertex(x2,y2);
endShape();
// line connecting inner black ellipse and left vertex
strokeWeight(3);
line(x6,y6,x5,y5);
pop();
}
function generatePrediction() {
}
function generateLuckyNumbers() {
for (var i = 0 ; i < 6; i++) {
luckyNums[i] = String(floor(random(0,100)));
}
return luckyNums;
}
function drawLuckyNumbers() {
luckynum1 = luckyNums[0];
luckynum2 = luckyNums[1];
luckynum3 = luckyNums[2];
luckynum4 = luckyNums[3];
luckynum5 = luckyNums[4];
luckynum6 = luckyNums[5];
fill(0);
textSize(12);
textFont(myFont);
noStroke();
textAlign(CENTER);
text("Lucky Numbers: " + luckynum1 + " " + luckynum2 + " " + luckynum3 + " " + luckynum4 + " " + luckynum5 + " " + luckynum6, width/2, 545);
}
function generatePhoneNumber() {
phoneNumber = "(" + String(floor(random(1,10))) + String(floor(random(0,10))) + String(floor(random(0,10))) + ")-" + String(floor(random(0,10))) + String(floor(random(0,10))) + String(floor(random(0,10))) + "-" + String(floor(random(0,10))) + String(floor(random(0,10))) + String(floor(random(0,10))) + String(floor(random(0,10)))
}
function drawPhoneNumber() {
textAlign(LEFT);
textFont(myFont);
fill(0);
textSize(12);
noStroke();
text("Call " + phoneNumber + " to order!", 40, 80);
}
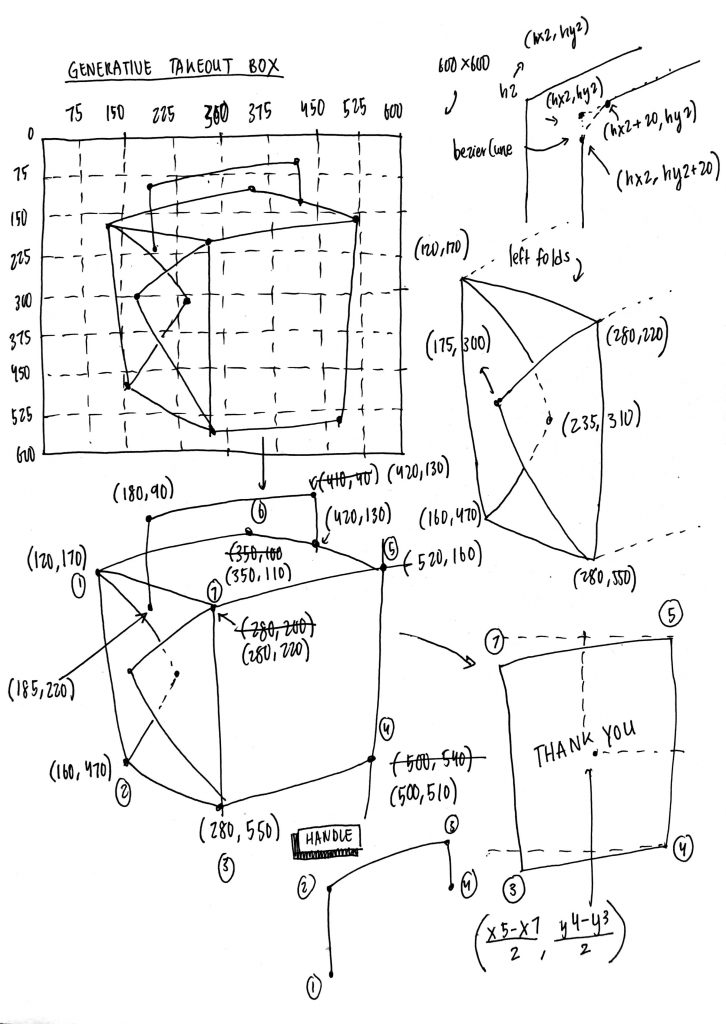
function generateBox() {
// box points
tx1 = random(100,140);
ty1 = random(150,190);
tx2 = random(140,180);
ty2 = random(430,500);
tx3 = random(250,300);
ty3 = ty2 + random(80,100);
tx4 = random(480,510);
ty4 = random(470,500);
tx5 = random(500,530);
ty5 = random(140,180);
tx6 = random(320,360);
ty6 = random(90,120);
tx7 = tx3;
ty7 = ty1 + random(40,60);
//flap points
fx = random((tx1 + 45)-15, (tx1 + 45) + 15);
fy = random((ty1 + 120) - 10, (ty1 + 120) + 10);
//handle points
hx1 = floor((tx1 + tx7) / 2)
hy1 = floor((ty1 + ty7) / 2) + 40;
hx2 = hx1 - random(3,7);
hy2 = hy1 - random(120,160);
hx4 = floor((tx6 + tx5)/2)
hy4 = floor((ty6 + ty5)/2)
hx3 = floor((tx6 + tx5)/2)
hy3 = hy4 - random(70,100);
}
function drawBox() {
push();
scale(0.5);
translate(260,300);
fill(255);
strokeWeight(2.6);
stroke(0);
//left face
beginShape();
vertex(tx1, ty1);
vertex(tx2, ty2);
vertex(tx3, ty3);
vertex(tx7, ty7);
vertex(tx1, ty1);
endShape();
//right face
beginShape();
vertex(tx3,ty3);
vertex(tx4,ty4);
vertex(tx5, ty5);
vertex(tx7, ty7);
vertex(tx3,ty3);
endShape();
//left folds
//back flap
beginShape();
vertex(tx1,ty1);
vertex(235,310);
vertex(tx2, ty2);
vertex(tx1, ty1);
endShape();
//front flap
beginShape();
vertex(tx7,ty7);
vertex(fx,fy);
vertex(tx3, ty3);
vertex(tx3, ty3);
vertex(tx7, ty7);
endShape();
//top face
beginShape();
vertex(tx5,ty5);
vertex(tx6,ty6);
vertex(tx1,ty1);
vertex(tx7,ty7);
vertex(tx5,ty5);
endShape();
//handle
//left vertical
strokeWeight(3);
// line(hx1,hy1,hx2,hy2);
beginShape();
noFill();
vertex(hx1, hy1);
vertex(hx2,hy2+20);
bezierVertex(hx2, hy2+20, hx2, hy2, hx2+20, hy2)
vertex(hx2+20, hy2)
vertex(hx3 - 20,hy3)
bezierVertex(hx3-20, hy3, hx3, hy3, hx3, hy3+20)
vertex(hx3, hy3+20)
vertex(hx4, hy4)
endShape();
//top horizontal
// line(hx2,hy2,hx3,hy3);
drawMessages();
pop();
}
function drawMessages() {
var messages = ["ENJOY", "THANK YOU"];
var i1 = floor(random(2));
var i2 = floor(random(2));
var m1 = messages[i1];
var m2 = messages[i2];
textFont(chineseFont);
noStroke();
fill(0);
textAlign(CENTER);
textSize(25);
x1 = floor((tx5-tx7)/2 + random(200,270));
y1 = floor((ty4-ty3)/2) + random(250,300);
x2 = x1 + random(60,90);
x2 = constrain(x2, tx1, tx4);
y2 = y1 + random(90,140);
y2 = constrain(y2, ty7, ty4);
r1 = random(HALF_PI/10,HALF_PI/6)
r2 = random(-HALF_PI/10, HALF_PI/10)
push();
rotate(r1);
text(m1, x1, y1);
pop();
push();
rotate(r2);
text(m2, x2, y2);
pop();
}
function drawPaper() {
rectMode(CENTER)
stroke(0);
fill(210);
rect(width/2, 525, 480, 90);
}
function generateFortune() {
rg = new RiGrammar();
//baseline for fortune cookie fortunes
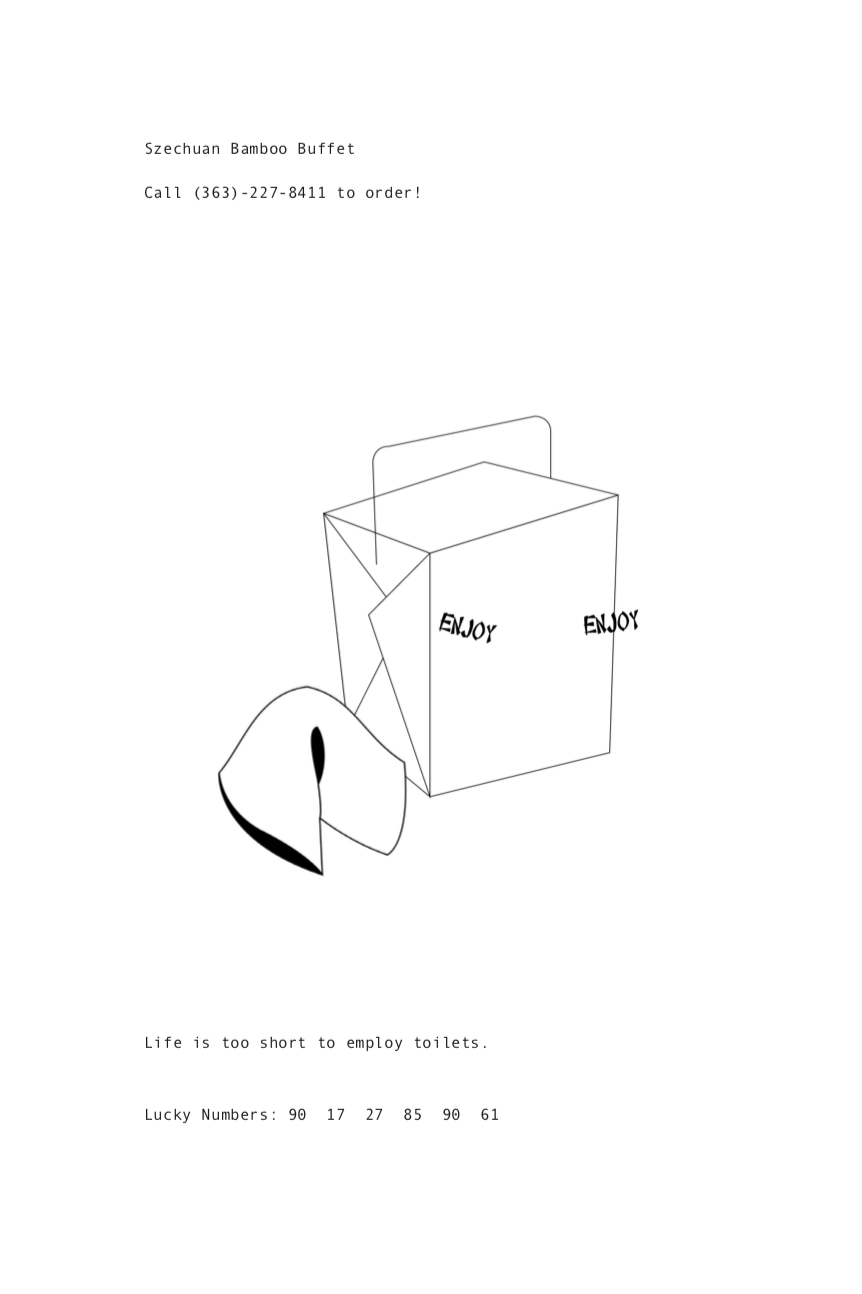
rg.addRule('<start>', 'Whoever <V-Singular-Present> a <N-Singular> will never be <V-Past> \nby a <N-Singular>.', 1);
rg.addRule('<start>', 'Life is too short to <V-Plural-Present> <N-Plural>.', 1);
rg.addRule('<start>', 'Your greatest strength is that you are <Adjective>.', 1);
rg.addRule('<start>', 'Your future seems <Adverb> <Adjective>.', 1);
rg.addRule('<start>', 'Alas, life is but a <Adjective> <N-Singular>.', 1);
rg.addRule('<start>', 'Your <N-Singular> shines on another.', 1);
rg.addRule('<start>', 'You will overcome <Adjective> <N-Plural>.', 1);
rg.addRule('<start>', 'It is not necessary to <V-Plural-Present> others your <N-Singular>; \nit will be obvious.', 1);
rg.addRule('<start>', 'Sometimes you just need to <V-Plural-Present> the <N-Singular>.', 1);
rg.addRule('<start>', 'See if you can <V-Plural-Present> anything from the <N-Plural>.', 1);
rg.addRule('<start>', 'Make the <N-Singular> <V-Plural-Present> for you, not the other way around.', 1);
rg.addRule('<start>', 'In the eyes of <N-Plural>, everything is <Adjective>.', 1);
rg.addRule('<start>', 'People in your surroundings will be more <Adjective> than usual.', 1);
rg.addRule('<start>', 'You will be successful at <V-ing> <N-Plural>.', 1);
rg.addRule('<start>', 'Whenever possible, keep it <Adjective>.', 1);
// rg.addRule('<start>', '', 1);
var args1 = {
tense: RiTa.PRESENT_TENSE,
number: RiTa.SINGULAR,
person: RiTa.THIRD_PERSON
};
var args2 = {
tense: RiTa.PRESENT_TENSE,
number: RiTa.PLURAL,
person: RiTa.THIRD_PERSON
};
var args3 = {
tense: RiTa.PAST_TENSE,
number: RiTa.SINGULAR,
person: RiTa.THIRD_PERSON
};
//nouns
rg.addRule('<N-Singular>', RiTa.randomWord("nn"));
rg.addRule('<N-Plural>', RiTa.randomWord('nns'))
//verbs
var v = RiTa.randomWord('vb');
rg.addRule('<V-Singular-Present>', RiTa.conjugate(v, args1));
rg.addRule('<V-Plural-Present>', RiTa.conjugate(v, args2));
rg.addRule('<V-Past>', RiTa.conjugate(v, args3));
rg.addRule('<V-ing>', RiTa.randomWord('vbg'));
//adjective
rg.addRule('<Adjective>', RiTa.randomWord('jj'));
//adverb
rg.addRule('<Adverb>', RiTa.randomWord('rb'));
//preposition
// rg.addRule('<Preposition>', RiTa.randomWord('in'));
result = rg.expand();
return result;
}
function drawFortune() {
fill(0);
textSize(12);
textFont(myFont);
noStroke();
textAlign(CENTER);
text(prediction, width/2, 515);
}
function createJSONFile() {
// Create a JSON Object, fill it with the restaurants.
var myJsonObject = {};
myJsonObject.restaurantName = name;
myJsonObject.phoneNumber = phoneNumber;
myJsonObject.prediction = prediction;
myJsonObject.luckyNumbers = luckyNums;
// Make a button. When you press it, it will save the JSON file
createButton('save')
.position(width/2-20, height-50)
.mousePressed(function() {
saveJSON(myJsonObject, 'data.json');
});
} |