
“More Like This, Please”
Today’s presentation focuses on the use of deep convolutional neural networks in generating imagery.
Vera Molnar, born 1924 and still working at age 98, is a living Hungarian-French artist who was one of the first ten people to make art with a computer. In 1968, Vera Molnar started working with a computer at the experimental psychology lab in Sorbonne, where she created her first plotter drawings, applying what she had been exploring in earlier years without using a machine.

She wrote: “Thanks to its many possibilities of combination the computer helps to systematically research the visual realm, helps the painter to free herself from cultural ′readymades′ and find combinations in forms never seen before, neither in nature nor at a museum: It helps to create inconceivable images. The computer helps, but it does not ′do′, does not ′design′ or ′invent′ anything. To avoid another misunderstanding I wish to underline something else: The fact that something is new and has not been seen before is no guarantee in any manner for its aesthetic quality.”
(Watch from 15:10-17:00)
In the above video, recorded in 2017, Molnár describes her interest in using the computer to create designs that could “surprise” her. Consider this generative 1974 plotter artwork by Molnár, below. How did she create this artwork? We might suppose there was something like an iterative repetition to create the main grid; another iterative loop to create the interior squares for each unit in the grid; and some randomness that determined whether or not to draw these interior squares, and if so, some additional randomness to govern the extent to which the positions of their vertices would be randomized. We suppose that she specified some variables that controlled the amount of randomness, the dimensions of the grid, the various probabilities of a square being omitted, etc.

Molnar’s process is a great illustration of how generative computer artworks were created during their first half-century. The artist writes a program that renders a form. This form is mathematically governed, or parameterized, by variables — specified by the artist. Change the values of these variables, and the form changes. She might link these variables to randomness, as Molnar does, or perhaps to gestural inputs, or perhaps link them to a stream of data, so that the form visualizes that data. She has created an artwork (software) that makes artworks (prints). If she wants “More like this, please”, she just runs the software again.
Just as with ‘traditional’ generative art (e.g. Vera Molnár), artists using machine learning (ML) develop programs that generate an infinite variety of forms, and these forms are still characterized (or parameterized) by variables. What’s interesting about the use of ML in the arts, is:
- That the values of these variables are no longer specified by the artist. Instead, the variables are now deduced indirectly from the training data that the artist provides. As Kyle McDonald has pointed out: machine learning is programming with examples, not instructions. Give the computer lots of examples, and ML algorithms figure out the rules by which a computer can generate “more like this, please”.
- The use of ML typically means that the artists’ new variables control perceptually higher-order properties. (The parameter space, or number of possible variables, may also be significantly larger.) The artist’s job becomes (in part) one of selecting, curating, or creating training sets.
The world’s foremost computational poet is probably Allison Parrish. Here is an astoundingly good lecture of hers from 2015; let’s watch a few minutes starting from 1:30-6:00, where she discusses how she creates programs to explore literature — making robot probes to bring back surprises from unknown poetic territories:
So, to find surprise, artists program machines with examples. Here’s Helena Sarin’s Leaves (2018). Sarin has trained a Generative Adversarial Network on images of leaves: specifically, photos of a few thousand leaves that she collected in her back yard.

GANs operate by establishing a battle between two different neural networks, a generator and a discriminator. As with feedback between counterfeiters and authorities, Sarin’s generator attempts to synthesize a leaf-like image; the discriminator then attempts to determine whether or not it is a real image of a leaf. Using evaluative feedback from the discriminator, the generator improves its fakes—eventually creating such good leaves that the discriminator can’t tell real from fake.
A master of this form is Berlin-based Sofia Crespo, an artist using GANs to generate biological imagery. One of her main focal points is the way organic life uses artificial mechanisms to simulate itself and evolve. Placing great effort into creating custom datasets of biological imagery, she has produced a remarkable body of organic images using GANs.

Another artist working this way is Chrystal Y. Ding. Below is her project, Performance II: Skin on Repeat, in which she has trained a GAN on a large collection of images of herself. Ding writes that she is “interested in fluctuations in identity and embodiment” and that she “uses machine learning to explore the impact of trauma and future technology on identity.”

Note that it’s also possible to generate music with GANs. For example, here is Relentless Doppelganger by DADABOTS (CJ Carr and Zack Zukowski)—an infinite live stream of generated death metal:
Here’s artist-researcher Janelle Shane’s GANcats (2019):

Janelle Shane’s project makes clear that when training sets are too small, the synthesized results can show biases that reveal the limits to the data on which it was trained. For example, above are results from a network that synthesizes ‘realistic’ cats. But many of the cat images in Shane’s training dataset were from memes. And some cat images contain people… but not enough examples from which to realistically synthesize a person. Janelle Shane points out that cats, in particular, are also highly variable. When the training sets are too small to capture that variability, other misinterpretations show up as well.
Incidentally, Janelle Shane is particularly well-known for her humorous 2017 project in which she trained a neural network to generate the names and colors of new paints. (What’s your favorite?)

An interesting response to GAN face synthesis is https://thisfootdoesnotexist.com/, by the Brooklyn artist collective, MSCHF. By texting a provided telephone number (currently not working), visitors to the site receive text messages containing images of synthetic feet produced by a GAN:
Here is a highly edited excerpt from the terrific essay which accompanies their project:
Foot pics are hot hot hot, and you love to see ‘em! At their base level they are pictures of feet as a prominent visual element. Feet are, by general scientific consensus, the most common non-sexual-body-part fetish. Produced as a niche fetishistic commodity, feet pics have all the perceived transgressive elements of more traditionally recognized pornography, but without relying on specific pornographic or explicit content. And therein lies their potential.
Foot pics are CHAMELEONIC BI-MODAL CONTENT. Because foot pics can operate in two discrete modes of content consumption simultaneously (i.e. they can be memes and nudes simultaneously, in the same public sphere), their perception depends entirely upon the viewer and the context in which the image appears. Thus the foot pic is both highly valuable and almost worthless at the same time – and this creates a highly intriguing supply & demand dynamic when creators/consumers fall on different ends of this valuation scale.
The foot pic specifically confounds the famous Supreme Court working definition of pornography – “[You] Know It When You See It.” Because the foot pic may be devoid of any mainstream pornographic signifiers it is both low barrier to entry and significantly safer to distribute. The production of the picture may, depending entirely upon the person to whom the foot belongs, be essentially valueless in the mind of the producer – and yet the resulting image strongly valued by the right consumer.
Style Transfer, Pix2Pix, & Related Methods

(Image: Alex Mordvintsev, 2019)
You may already be aware of “neural style transfer”, developed by a Dutch computing lab in 2015. Neural style transfer is an optimization technique used to take two images—a content image and a style reference image (such as an artwork by a famous painter)—and blend them together so the output image looks like the content image, but “painted” in the style of the style reference image. It is like saying, “I want more like (the details of) this, please, but resembling (the overall structure of) that.”
![]()
This is implemented by optimizing the output image to match the content statistics of the content image and the style statistics of the style reference image.

Various new media artists are now using style transfer code, and they’re not using it to make more Starry Night clones. Here’s a project by artist Anne Spalter, who has processed a photo of a highway with Style Transfer from a charcoal drawing:

Some particularly stunning work has been made by French new-media artist Lulu Ixix, who uses custom textures for style-transferred video artworks. She was originally a special effects designer:
Below is a video, Entangled II by artist Scott Eaton, that uses style transfer. (What was the “style” texture? What was it transferred onto?)
More lovely work in the realm of style transfer is done by Dr. Nettrice R. Gaskins, a digital artist and professor of new-media art at Lesley University. Her recent works use a combination of traditional generative techniques and neural algorithms to explore what she terms “techno-vernacular creativity”.

Style transfer has also been used by artists in the context of interactive installations. Memo Akten’s Learning to See (2017) uses style transfer techniques to reinterpret imagery on a table from an overhead webcam:

A related interactive project is the whimsical Fingerplay (2018) by Mario Klingemann, which uses a model trained on images of portrait paintings:
Fingerplay (Take 1) pic.twitter.com/oyys84Al0e
— Mario Klingemann 🇺🇦 (@quasimondo) April 7, 2018

Conceptually related to style transfer is the Pix2Pix algorithm by Isola et al. In this way of working, the artist working with neural networks does not specify the rules; instead, she specifies pairs of inputs and outputs, and allows the network to learn the rules that characterize the transformation — whatever those rules may be. For example, a network might study the relationship between:
- color and grayscale versions of an image
- sharp and blurry versions of an image
- day and night versions of a scene
- satellite-photos and cartographic maps of terrain
- labeled versions and unlabeled versions of a photo
And then—remarkably—these networks can run these rules backwards: They can realistically colorize black-and-white images, or produce sharp, high-resolution images from low-resolution ones. Where they need to invent information to do this, they do so using inferences derived from thousands or millions of real examples.
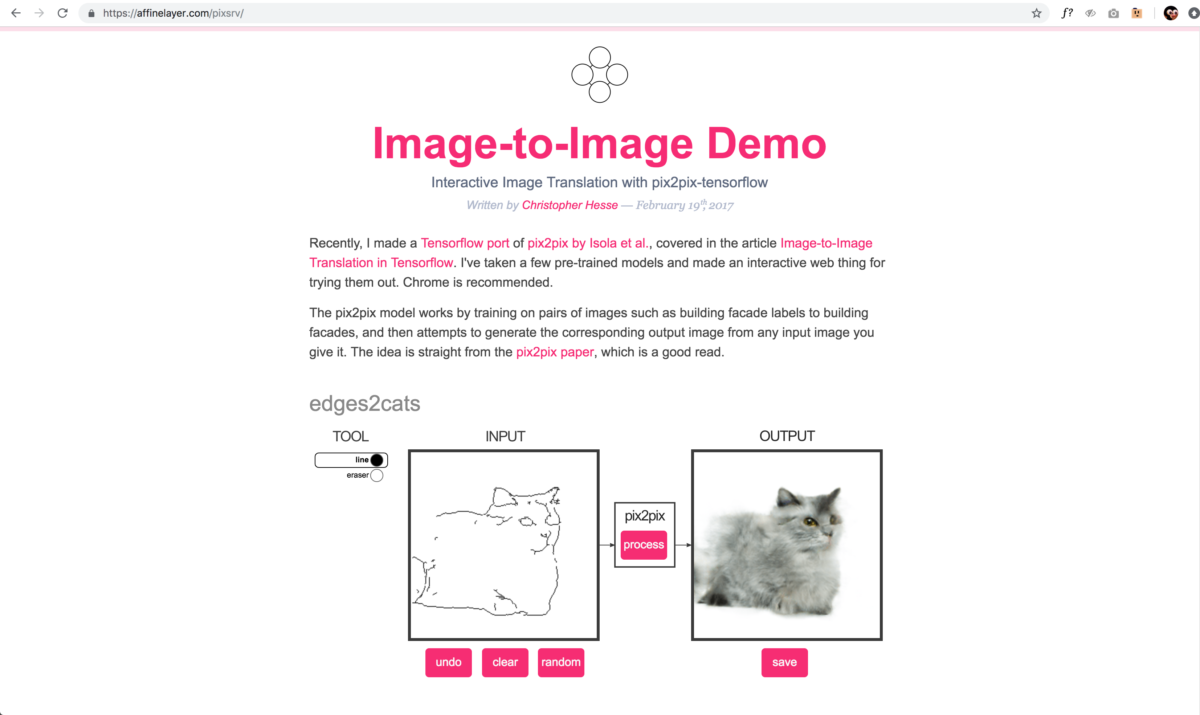
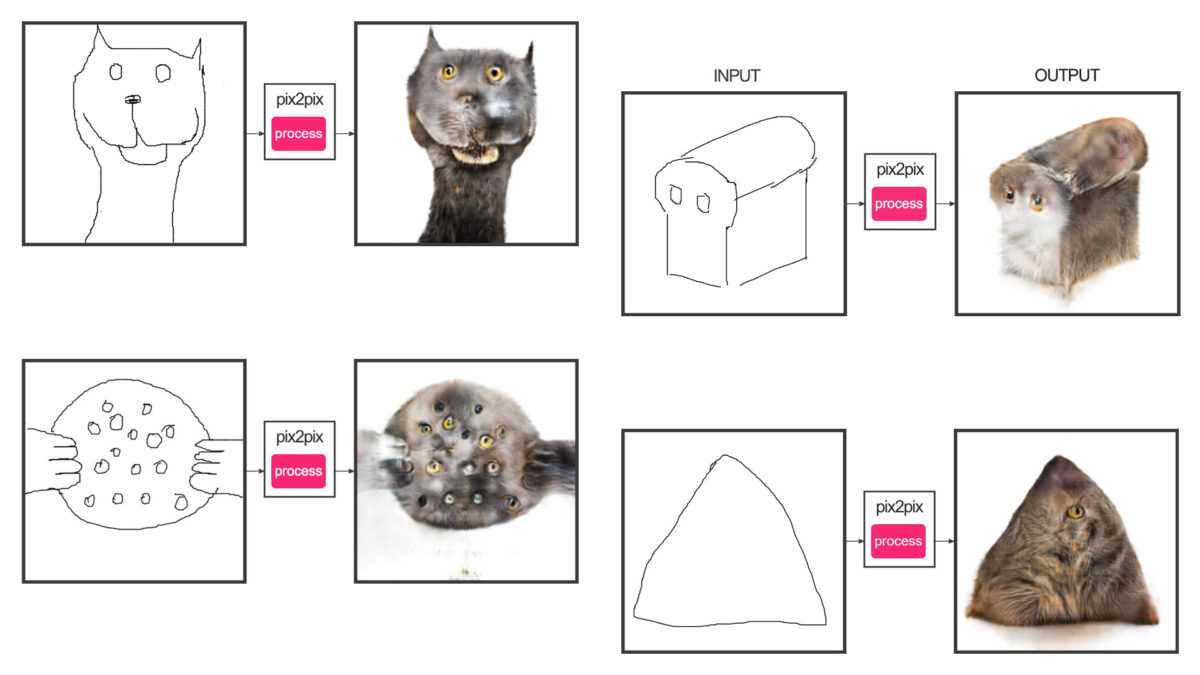
I’d like to present you a good example of this, and something fun you can experiment with yourself at home. This is a program called Edges2Cats by Christopher Hesse, which we will be using in our exercises. In this project, Hesse took a large number of images of cats. He ran these through an edge-detector, which is a very standard image processing operation, to produce images of their outlines. He trained a network to understand the relationship between these image pairs. And then he created an interaction where you can run this relationship backwards.

It’s important to pointing out that evil twin of Edges2Cats is a project like the one above, which is aimed at occluded or disguised face recognition. These researchers have trained their network on pairs of images: your face, and your face with a disguise — in the hope of running that network backwards. See someone with a mask, and guess who it is…
Newer variations of style transfer, such as CycleGAN, allow a network to be trained with unpaired photographs, such as a collection of horse images, and a collection of zebra images.