I worked with the collection of Japanese woodblock prints on Ukiyo-e. I scraped images from individual galleries listed on this website- the Museum of Fine Arts, British Museum, and the Edo Tokyo Museum, to name a few. The generic code to get metadata (including image urls) for images from any Museum gallery, in a common format, can be found here. The metadata includes dates (for a subset of images), titles and the artist (for a subset of images).
I used ofx-TSNE to get an idea of what the image set is like. Here is a sample grid using around 4000 images from the British Museum. The top has a lot of portraits. The bottom right has landscapes and nature scenes. There are clear sections with geishas, kabuki actors. The TSNE files can be found here.
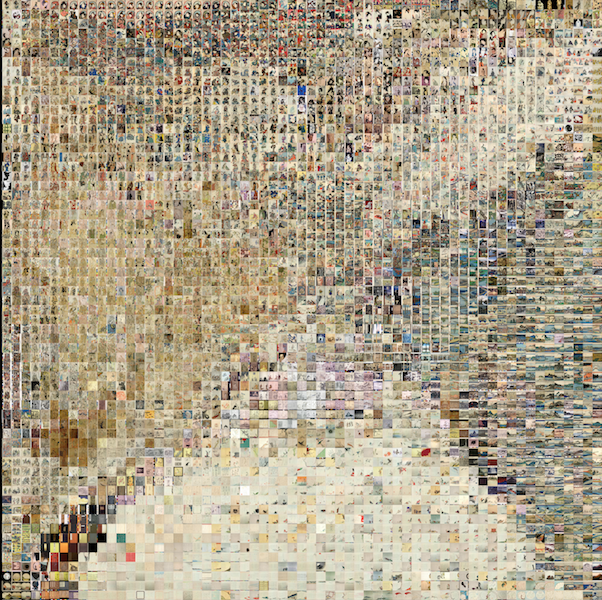
Some of the galleries have tags defined on a ‘more details’ page. I also used clarifai to get nouns in a random sample of images. Items like ‘water’, ‘building’ were accurately detected, especially with the high quality images from the Edo Tokyo museum, but didn’t work well with detecting the presence of people. So I ignored nouns like ‘person’, ‘no person’.
My goal with these images was to generate mystical text. I was inspired by the fake text at the start of the movie ‘Le Samourai’ – ‘There is no greater solitude than that of the samurai unless it is that of the tiger in the jungle… Perhaps…’ I decided to generate a story based on these images.
Golan pointed me to some interesting tools that helped me understand the realm of generative text – neural storyteller, Char-RNN. Also this fantastic article by Ross Goodwin.
I used Torch-RNN and trained it with a set of Japanese texts. I first found all possible English texts about Japan / Japanese topics on Gutenberg. I narrowed them down based on dominant terms from the metadata in the image set – mountain, geisha, woman, kabuki, land, water, etc.
The end result was to pull out an image at random, get the defining noun, and trigger a story with it, using the trained Torch-RNN tool. So an image about a ‘sight to behold’ would have text captioned like this –
“the sight of the attack of the common possession in the most courtiers, and the province of the room which respect the sword on the family”
Lessons learnt – The accuracy and the quality of the text could be improved very easily. 1) I need to use a larger dataset, and with a larger RNN-size, which requires GPU and lots of memory and time. 2) I need to curate the training text more, removing poetry, glossaries, etc. 3) I need to find a coherent set of text. Different authors over 200 years had different writing styles, and when translated to English it was even more dissimilar.