
Contents
- Excavating AI: Biases in the Machine
- Training AI Systems Has a Human Cost
- Is this authorship? Billion-Scale Image Models and Plagiarism
1. Excavating AI: Biases in the Machine
There are lots of ways that some horrific biases and stereotypes are routinely incorporated into the labeling of image datasets. When those datasets are used to train models used to analyze (i.e. label) or synthesize (ie. generate) new images, it can cause grievous failures like this one, and worse:
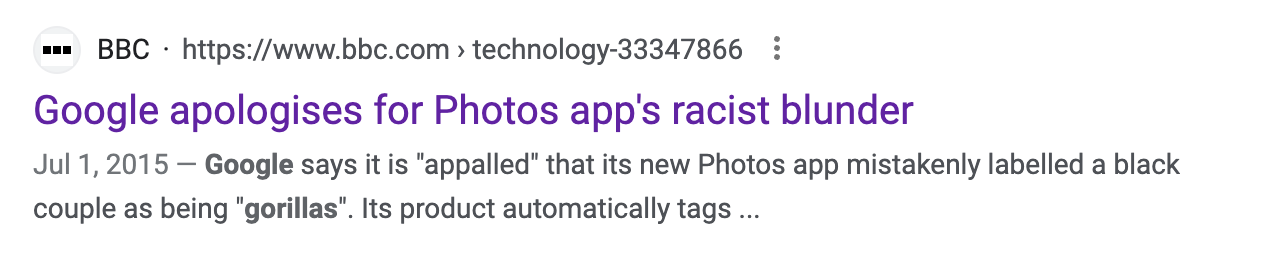
Artists Trevor Paglen and Kate Crawford have been studying biases in the labeling of image datasets used in AI. In their landmark project Excavating AI: The Politics of Images in Machine Learning Training Sets, they write:
For the last two years, we have been studying the underlying logic of how images are used to train AI systems to “see” the world. We have looked at hundreds of collections of images used in artificial intelligence. Methodologically, we could call this project an archeology of datasets.
One of the most significant training sets in the history of AI so far is ImageNet. First presented as a research poster in 2009, the idea behind ImageNet was to “map out the entire world of objects.” Over several years of development, ImageNet grew enormous: the development team scraped a collection of many millions of images from the internet, using an army of online workers. When it was finished, ImageNet consisted of over 14 million labeled images organized into more than 20,000 categories. For a decade, it has been the colossus of object recognition for machine learning and a powerfully important benchmark for the field.
[…] Other people are labeled by their careers or hobbies: there are Boy Scouts, cheerleaders, cognitive neuroscientists, hairdressers, intelligence analysts, mythologists, retailers, retirees, and so on. As we go further into the depths of ImageNet’s Person categories, the classifications of humans within it take a sharp and dark turn. There are categories for Bad Person, Call Girl, Drug Addict, Closet Queen, Convict, Crazy, Failure, Flop, Fucker, Hypocrite, Jezebel, Kleptomaniac, Loser, Melancholic, Nonperson, Pervert, Prima Donna, Schizophrenic, Second-Rater, Spinster, Streetwalker, Stud, Tosser, Unskilled Person, Wanton, Waverer, and Wimp. There are many racist slurs and misogynistic terms.
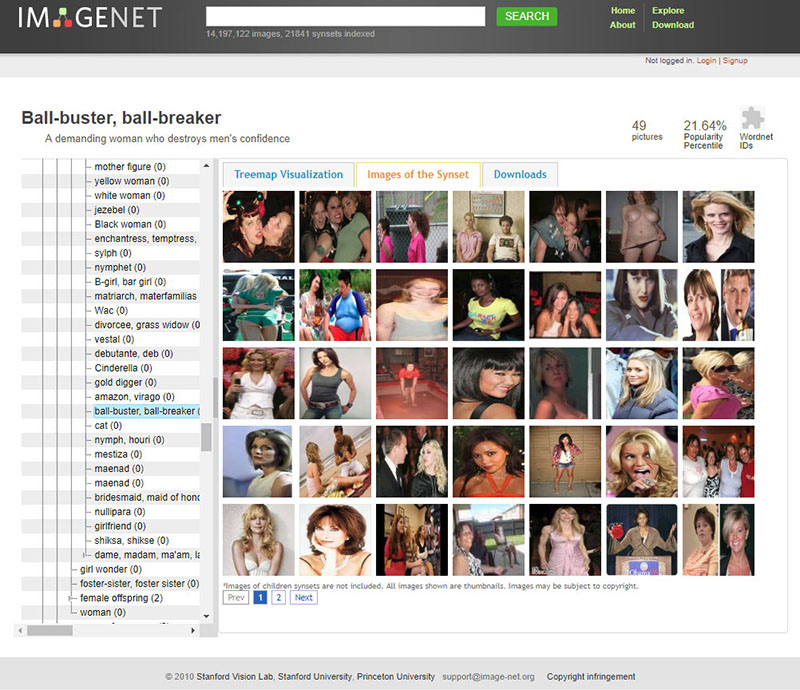
Imagenet has thousands of categories for everyday nouns, like “pizza” and “frog”. But Paglen and Crawford also demonstrate that there is a category (for example) for “ball-buster”, which is used to label images of women. Here is their screenshot from the ImageNet browser:
We can experiment with this ourselves. This browser-based project allows a visitor to explore a small (12M) subset of the LAION-5B dataset, a 5-billion-image dataset that was used to train Midjourney and Stable Diffusion. Here are the results for searching for images labeled “thing” and “nurse”:
2. Training AI Systems Has a Human Cost

[Content Warning] In its quest to make ChatGPT less toxic, OpenAI used outsourced Kenyan laborers earning less than $2 per hour, a TIME investigation has found. Facebook had already shown it was possible to build AIs that could detect toxic language like hate speech to help remove it from their platforms. The premise was simple: feed an AI with labeled examples of violence, hate speech, and sexual abuse, and that tool could learn to detect those forms of toxicity in the wild. That detector would be built into ChatGPT to check whether it was echoing the toxicity of its training data. To get those labels, OpenAI sent tens of thousands of snippets of text to an outsourcing firm in Kenya. Much of that text appeared to have been pulled from the darkest recesses of the internet. Some of it described situations in graphic detail like child sexual abuse, bestiality, murder, suicide, torture, self harm, and incest. One worker tasked with labeling text for OpenAI told TIME he suffered from recurring visions after reading a graphic description of a man having sex with a dog in the presence of a young child. “That was torture,” he said. “You will read a number of statements like that all through the week. By the time it gets to Friday, you are disturbed from thinking through that picture.”
For more information on this kind of harm to information workers, see the incredible Verge article, The Trauma Floor: The secret lives of Facebook moderators in America (2019), which discusses the lives of content moderators who are paid to filter violence, pornography, and worse from social media sites.
3. Is this authorship? Billion-Scale Image Models and Plagiarism

For many of us (visual artists), synthesizing images with AI tools like Midjourney can be “fun”—an enjoyable pastime or experiment. But: do you feel like (A) “you” are (B) “making” (C) “art“?

A MidJourney user won a state fair art prize for their AI-generated image (NYTimes). [PDF]

The large models used in MidJourney, Stable Diffusion, and Dall-E, etc. are trained on billions of images, vacuumed up from the Internet. When this happens, images by actual artists, both living and dead, gets blended into the training data. It becomes possible to generate images that appear stylistically close to the work of those artists, as demonstrated by this site.


Here you can verify that LAION-5B has ingested the work of some well known (living) artists: