An openFrameworks application that highlights unique passages in each day’s readings.
The application interface consists of a slider along the top that controls a range of dates. Books that were read during the selected time range are then displayed in the center of the screen with markers on the timeline corresponding to the start and end dates of that book.
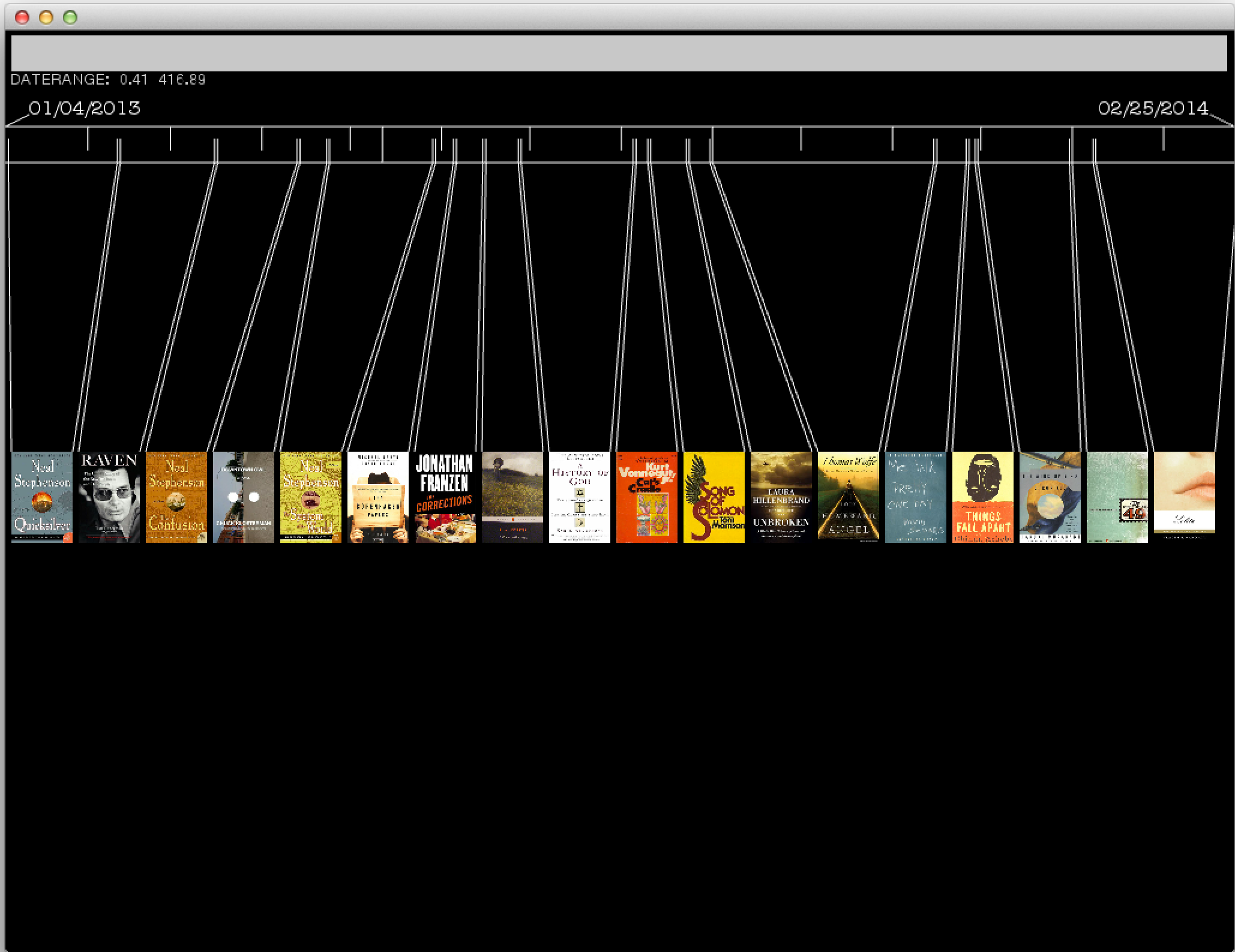
[Wide Range Photo]
Moving the mouse along the timeline will then select a day an individual day. If any reading occurred on that day, the text that was read is analyzed against the entirety of the book. The sentence containing the most unique phrase in a given day’s reading is then displayed.
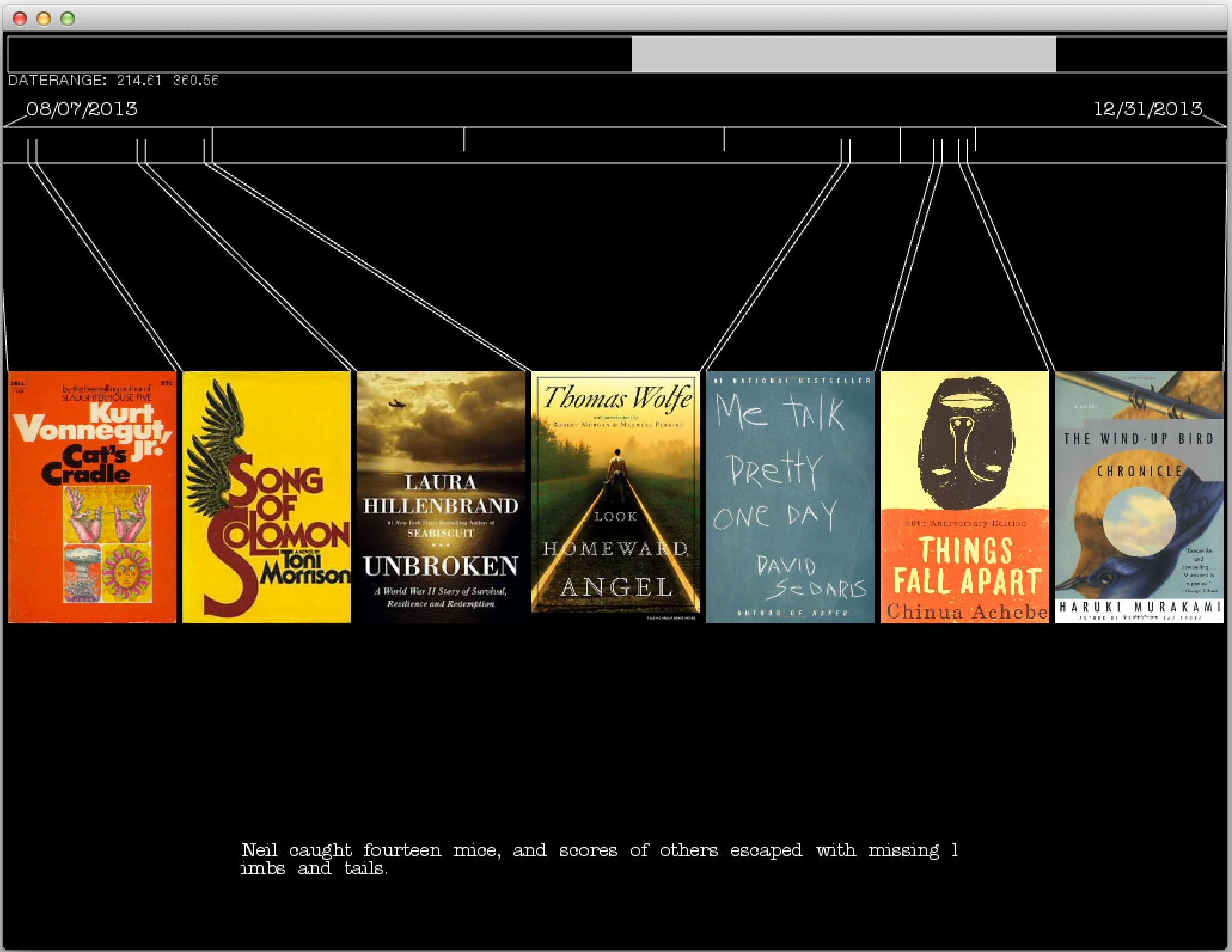
[Detailed tf-idf Photo]
The application is built with openFrameworks. The text analysis is done using Beautiful Soup and the Natural Language Toolkit in Python. Currently, data tracking the books and pages read over time are manually recorded in a CSV file.
The first version of the application (seen below) performed similar frequency analyses with several more information sources (fitness trackers, financial data, etc.). However, the interface was poorly developed. Trying to throw more data into a single common interface, simply muddied the execution. Focusing only on the text analysis resulted in a much cleaner project.
