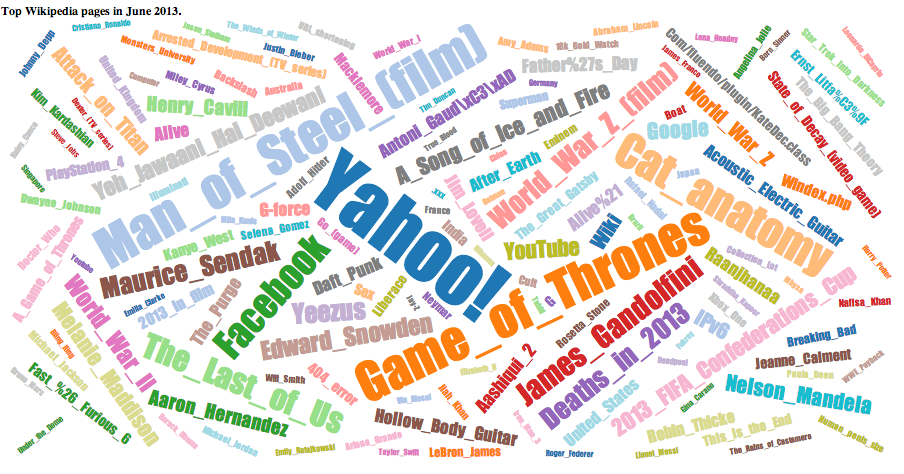
For this I scrapped 70GB of wikipedia page views for all of June 2013. This data is all available on public amazon s3 buckets with the views for every page per hour. I use amazon map reduce to reduce this to only pages with over 100k views and for every day what the views were.
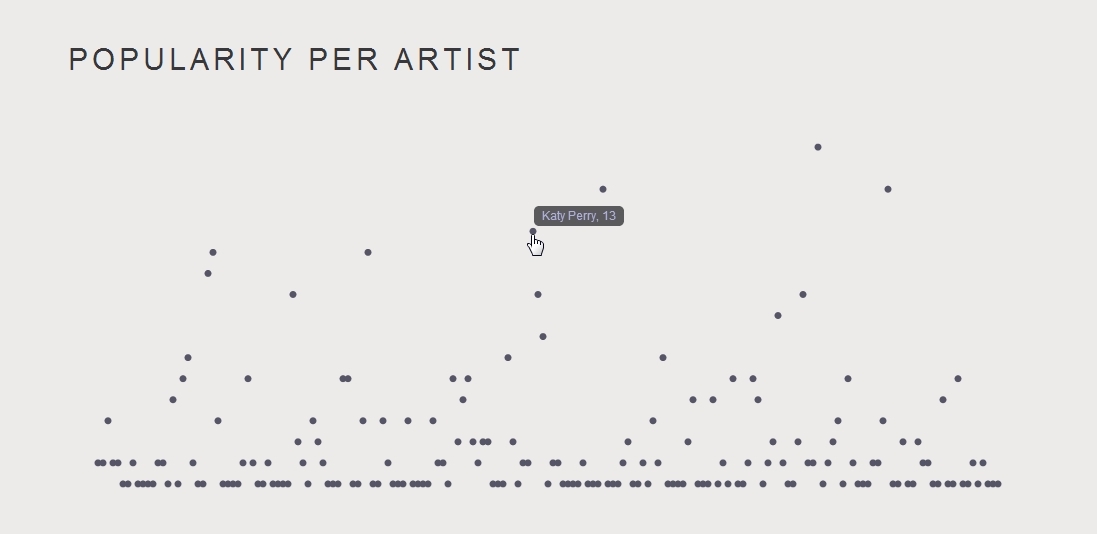
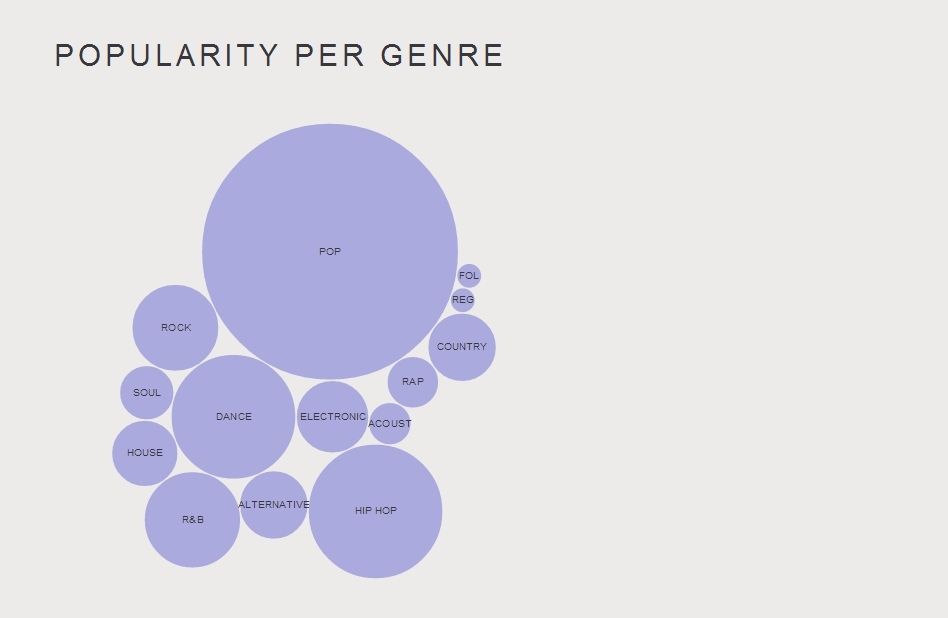
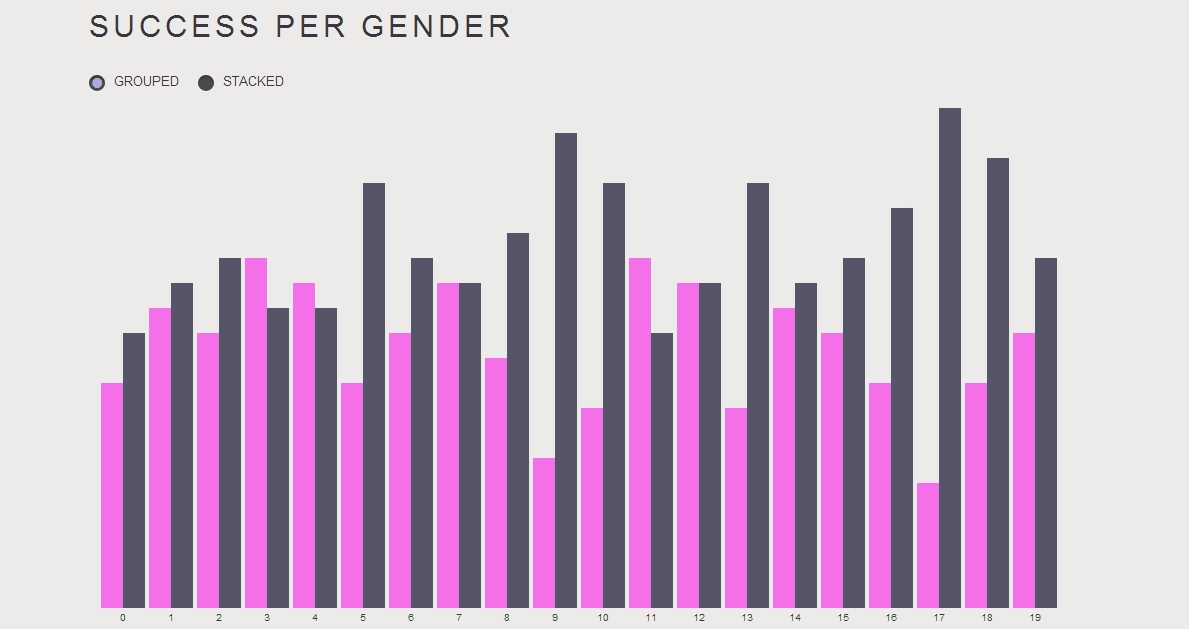
Here all pages over 500k views can be seen and clicking on any one shows a graph of the view over the month.
Some interesting trends were:
Yahoo jumped from about nothing to 450k/day when they announced the purchase of tumblr.
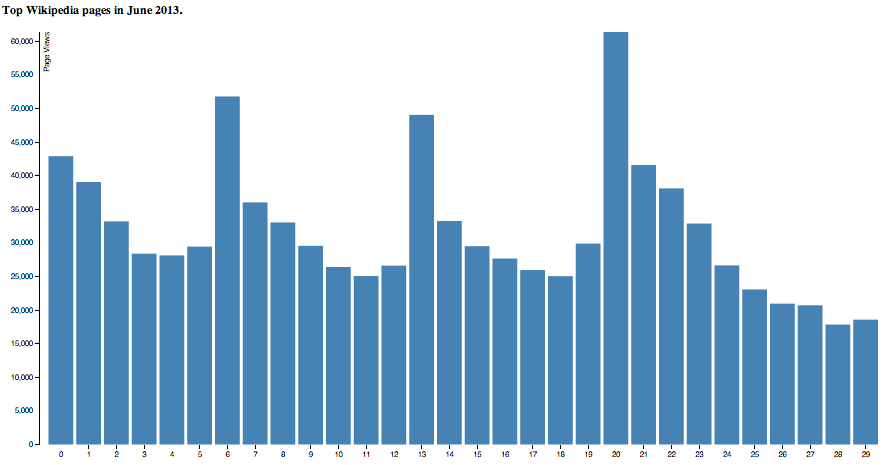
Tv shows peaked every 7 days.
People search for cat anatomt…
Yahoo when they bought tumblr..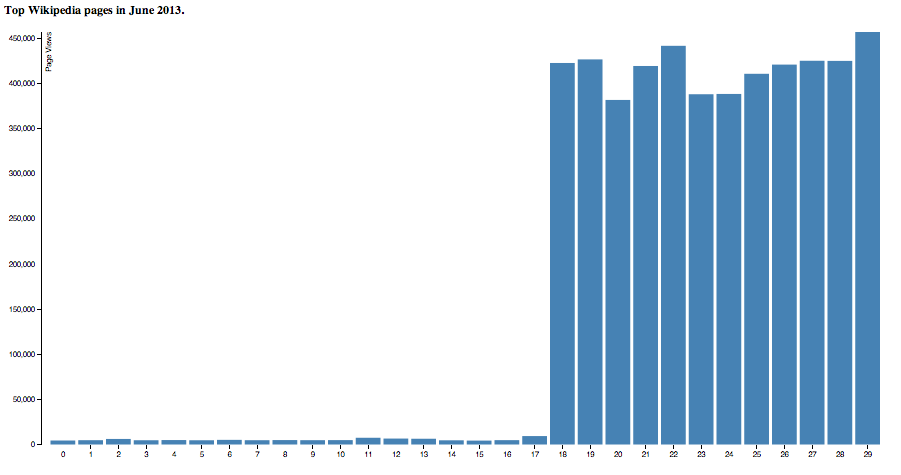
Hannibal TV show
What a mapReduce program looks like..
#!/usr/bin/python
from __future__ import print_function
import fileinput
import sys
import os
badTitles = ["Media","Special","Talk","User","User_talk","Project","Project_talk","File","File_talk","MediaWiki","MediaWiki_talk","Template","Template_talk","Help","Help_talk","Category","Category_talk","Portal","Wikipedia","Wikipedia_talk"]
badExtns = ["jpg", "gif", "png", "JPG", "GIF", "PNG", "txt", "ico"]
badNames = ["404_error/","Main_Page","Hypertext_Transfer_Protocol","Favicon.ico","Search"]
#arr = []
#count = 0
#fullName = 'pagecounts-20130601-000000'#os.environ["map_input_file"]
fullName = os.environ["map_input_file"]
fname = fullName.split('/')
date = fname[-1].split('-')[1]
def process(line):
# global count
L = line.split(" ")
# count += int(L[2])
if not line.startswith("en "):
return
L = [L[1], int(L[2])]
#count += L[1]
#if(L['name'] != "en"):
# return
for i in xrange(len(badTitles)):
if(L[0].startswith(badTitles[i])):
return
if ord(L[0][0])>96 and ord(L[0][0])<123:
return
for j in xrange(len(badExtns)):
if(L[0].endswith(badExtns[j])):
return
for k in xrange(len(badNames)):
if L[0] == badNames[k]:
return
#dateArr = [0]*30
#dateArr[int(date[-2:])]= L[1]
print (L[0]+"\t"+date[-2:]+"\t"+str(L[1]))
return
#print L['title']+"\t"+L['numAccess']
#total = 0
for line in sys.stdin:
line = line.strip()
process(line)
# total += 1
#f = open ("/home/ubuntu/output.txt", 'w')
#arr = sorted(arr, key = lambda x : x[1])
#print ("sorted", total, count, len(arr))
#for z in xrange(len(arr)) :
# string = arr[z][0]+"\t"+str(arr[z][1])+"\n"
# f.write(string)
#print(string, file = "/home/ubuntu/output.txt")
#f.close()
#print ("Written to file.")
#!/usr/bin/python
import sys
last_key = None
running_total = 0
viewsPerDay = [0] * 30
threshold = 100000
for input_line in sys.stdin:
input_line = input_line.strip()
input_line = input_line.split('\t')
#print input_line
if len(input_line) != 3:
break
articleName = input_line[0]
date = int(input_line[1]) # 1 - 30 inclusive
viewsThatDay = int(input_line[2])
if last_key == articleName:
running_total += viewsThatDay
viewsPerDay[date-1] += viewsThatDay
else:
if last_key and running_total > threshold:
print(str(running_total)+'\t'+last_key+'\t'+str(viewsPerDay))
running_total = viewsThatDay
last_key = articleName
viewsPerDay = [0] * 30
viewsPerDay[date-1] += viewsThatDay
if last_key == articleName:
print(str(running_total)+'\t'+articleName+'\t'+str(viewsPerDay))