The “Flappy Noise”
Note: Click on an image to see its hi-res version. I did all my visualizations in OpenFrameworks (which is definitely not the best), so scaled down images in this post are unreadable.
Uncommented Code: Here
Tweet-able Description:
The Flappy Noise: An investigation into the creation of a data-driven bot to rule the skies in FlapMMO (the Flappy Bird MMO).
Inspiration
What to do for my data visualization project? Hmmm I guess something with video games seems like the obvious answer. But what with video games? The examining the sales, ratings or similarities of video games still seems a bit bland. So it must be gameplay data then.
With the rise of “Data-Driven Design” in video games, gameplay data is now hidden under lock & key. So even though all these games have tons of gameplay data is sent back to the company, I can’t get that data without backward engineering the game or hacking into somewhere that I shouldn’t be.
That really left two options. A) I make my own game so I have control over everything and I can put data hooks in myself as I wish. B) I find some set of gameplay data that has been made public.
As I sat there pondering my options, Joel made my decision for me by sending me this great visualization of data from the FlapMMO (Flappy Bird MMO). Connor Sauve does a great job of weaving his data analysis/visualization into a narrative. And most important of all, he made his data open source.
<beginRant>
Oh and just as a note: I am not the biggest fan of Flappy Bird and as someone who wants to be in the game industry it is painful to see that despite game developers efforts to create meaningful and engaging experiences, that people just want a mindless game with unrewarding repetitive action (this is at least 10x worse than Call of Duty in my books). Not to mention the fact that it is just a copy of the Helicopter game that has been around since 2004 (Read here). Oh and I love how every 24 minutes a new Flappy Bird clone is posted on the App Store (Read here).
</endRant>
The Curious Incident of the Bird in the App-Store
The “Flappy Noise” is my idea that their is a specific tap frequency or tap pattern that will cause the player to go the furtherest in the game. So that was my original hypothesis and from there I wanted to see if it had any possibility of truth behind it.
The Pursuit of the Elusive “Flappy Noise”
Step 1: Tap Frequency vs. Distance Traveled
X-Axis: Tap Frequency (total frames traveled / number taps)
Y-Axis: Distance Traveled (total frames traveled)

From this graph (because of the vertical line) we can see there is a definitely an average tap frequency which the players who go the furthest maintain.
Step 2: Time vs Number of Taps (per Flap – for 1st 20 flaps)
X-Axis: Time (in frames)
Y-Axis: Number of players who tapped at the frame for that flap (in number of players)
Color : Percentage of deaths that occurred after this flap vs. total number of deaths (red – most deaths occurred after this flap, green – most player survived to flap again)
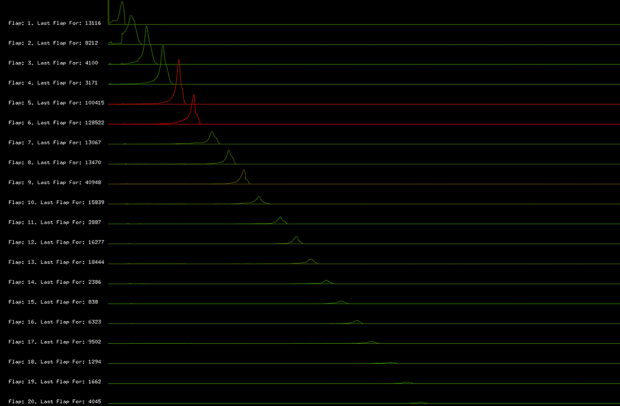
Here we see that there is a reoccurring shape of when players tap, which again suggested that the “Flappy Noise” maybe exist.

Here I layered the first 20 flaps. Not sure how meaningful it is, but its interesting to see them side by side.
Step 2.5: Time vs Number of Taps (per Flap) [Change in meaning of Colors]
X-Axis: Time (in frames)
Y-Axis: Number of players who tapped at the frame for that flap (in number of players)
Color : Percentage of deaths that occurred after this flap vs. total number for this flap (red – most deathly flap, green – easiest flap)
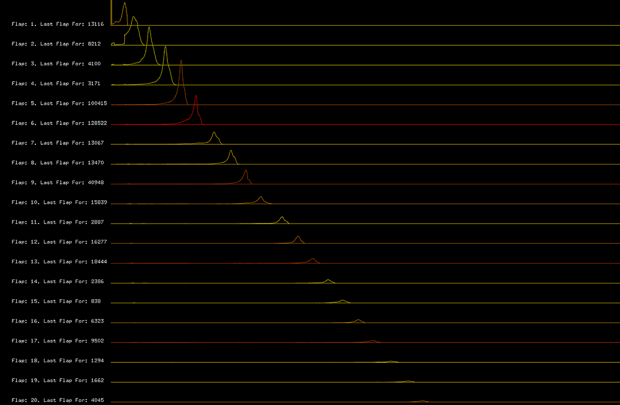
We see that there is an interesting pattern regarding when players die. We can see that every 3-4 flaps a large majority of the alive players die by running into a pipe.
Step 3: Top Players – Time vs Number of Taps (per Flap – for 1st 60 flaps)
Restriction: For this run the player must have survived at least 40 flaps
X-Axis: Time (in frames)
Y-Axis: Number of players who tapped at the frame for that flap (in number of players)
Color : Percentage of deaths that occurred after this flap vs. total number of deaths (red – most deaths occurred after this flap, green – most player survived to flap again)
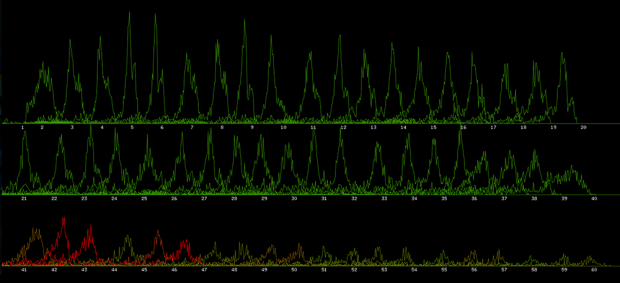
Here we see that the top players a decent amount of variance regarding when they tap per flap, which could suggest different tapping methods/times. This is partially reaffirmed by the fact that after the majority of players who survived the first 40 flaps die by flap 48, that we still see a large amount of variance in tapping in flaps 48-60. So possibly there are numerous “Flappy Noise”s or it could be one “Flappy Noise” but players just started at different times.
Step 4: Top Players – Tap Frequency vs Number of Taps (per Flap – for 1st 60 flaps)
Restriction: For this run the player must have survived at least 40 flaps
X-Axis: Number of frames since last tap (in frames) [shown for each flap]
Y-Axis: Number of players who waited that long since their previous tap to tap again (in number of players)
Color : Percentage of deaths that occurred after this flap vs. total number of deaths (red – most deaths occurred after this flap, green – most player survived to flap again)
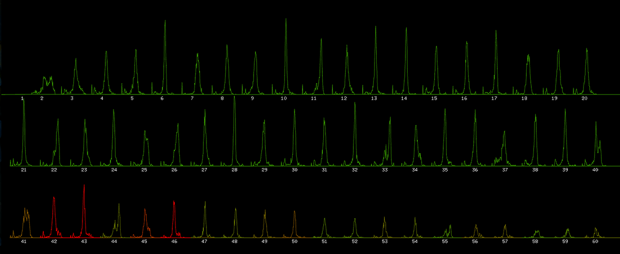
This is where “The Flappy Noise” begins to seem like it could truly exist. The majority of top players wait the same number of frames between taps. We can see that at the front end of each flap there is a spike of players who waited a small number of frames to tap again. This could be players who either practice a fast tapping approach or could be “rescue taps” that players have to make to survive from running into a pipe.
Step 4.5: Top Players – Tap Frequency vs Number of Taps (per Flap) [Combined]
Restriction: For this run the player must have survived at least 40 flaps
X-Axis: Number of frames since last tap (in frames) [all flaps layer onto of each other]
Y-Axis: Number of players who waited that long since their previous tap to tap again (in number of players)
Color : Percentage of deaths that occurred after this flap vs. total number of deaths (red – most deaths occurred after this flap, green – most player survived to flap again)
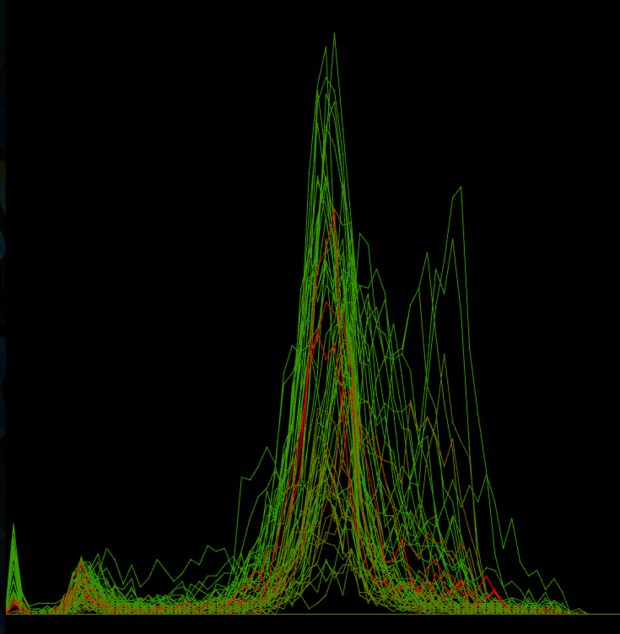
Here we see that while there certainly is some variance in tap frequency per flap, there is a definite a common frequency that players keep throughout their run. This common tap frequency is every 38 frames (the game runs at 60 fps). Could this be the “Flappy Noise”?
Testing the “Flappy Noise”: No Birds Injured in the Process
Now that I may have found the “Flappy Noise”, it is time to test if it actually works. Humans are not that reliable to tap every 38 frames (especially one who can’t play a musical instrument). So I went to Processing and used the Java Robot Class to allow me to fake keyboard presses. FlapMMO runs at 60fps as did my Processing sketch.
Of course I couldn’t have an ugly processing sketch, so I added the Flappy Bird sprite with movement and a bird wing flapping noise. Now when the processing sketch goes to input a keystroke every 38 frames we see the “cute” flappy bird jump and hear its wings flap.

I had somehow not realized until this point that FlapMMO has different servers and each server has a different variant of the Flappy Bird course (and that the course per server changes occasionally to prevent anyone from cheating, since its an MMO). Luckily Sauve mentioned in his write up that the majority of the data was collected on Server 6, so I ensured that I was on server 6 for all testing. [I did test everything that I will mention below on other servers to just see, but they were epic fails to say the least]
Static 38 Frames Jump-Rate
Most Flaps Achieved: 8
Max Pipes Cleared: 1
The results of the testing with a static 38 frames jump-rate were not the best. I couldn’t get past the second pipe. It would never jump in quick enough succession to go over the pipe.
Top Player Average Frame Per Flap
Most Flaps Achieved: 6
Max Pipes Cleared: 0
So after the disheartening results with the static 38 frames between jump theory, I decided to reconsider the idea that the “Flappy Noise” could be a pattern. I decided to work with the top players data (those who had made it 40 flaps). For each flap (2-60) I took the average interval between the previous flap and that flap and stored it in an array. Next I found the average first frame that top player flap on. Finally I used these two items to create an array of frame numbers on which I should flap.
Top Three Flap Record Runs
Most Flaps Achieved: 5
Max Pipes Cleared: 0
Well the whole involved top player average didn’t work and neither did the static frames, I wonder if I screwed something up somewhere. I know what to do! I will take the best run and just use its frame array to dictate when to jump. That will take out any chance of me screwing something up. …… So I tried that and it didn’t work, it was worse than the top player average. Maybe that run was done on a different server, so I tried it with second and third best runs and got the same results.
Combo Move: Static 38 Frames Jump-Rate + Top Player Average Frame Per Flap
Most Flaps Achieved: 13
Max Pipes Cleared: 2
I was beginning to lose faith, so I began just trying things with the hope that I would land on something that worked. And it sort of worked … well not really, but I got past the second pipe. The method that achieved this was: that the standard frame-wait between flaps would be 38 frames, but 1/3 of the time the frame-wait would be the average frame-wait for the top players for that flap and 1/22 of the time the frame-wait would be 45 frames (to cause it to drop in time).
Breaking News: Flappy Bird following “Flappy Noise” crashes through Plane Windshield
Conclusion:
For the FlapMMO a “Flappy Noise” does not exist. FlapMMO has too many inconsistencies to allow for a “Flappy Noise” to exist; FlapMMO’s multiple servers with unique pipe layouts, the fact that the pipe layout even changes for a specific server if you stay on it long enough and the inconsistency of the frame rate of the Processing sketch and the frame rate of FlapMMO (often depending on the number of player).
For a version of Flappy Bird for Processing or even on other platforms (as long as the above problems do not exist), I certainly believe the “Flappy Noise” exists. But what is the fun in that? What would have been great about the “Flappy Noise” existing for FlapMMO is that others see you dominate them in near real-time, and that the leader for a specific server in FlapMMO gets a flappy bird that wears a crown.
Note: Creating a standard bot for FlapMMO was definitely possible when it first came out and still may be possible (though lots of the security weaknesses have been fixed since then). What I was trying to create was a data-driven bot that moved according to player gameplay data, and NOT by just reading in the current state of the game.




















{kind=link}