Finding emilyisms in my online interactions.
This post is long overdue, and exemplifies the time-honored MHCI mantra of “done is better than perfect.”
I downloaded my entire Facebook and Google Hangouts history, hoping to find examples of “emilyisms.” By that, I mean key words or phrases that I repeat commonly enough for someone to associate them with me.
Once I isolated the text itself, I read it into NLTK, and used it to find n-grams of words, for combinations 2-7 words long. Then, I put the data into a bubble cloud using D3, hoping to visually find phrases which identify my speech. Here is the result: (you can see the full version here)
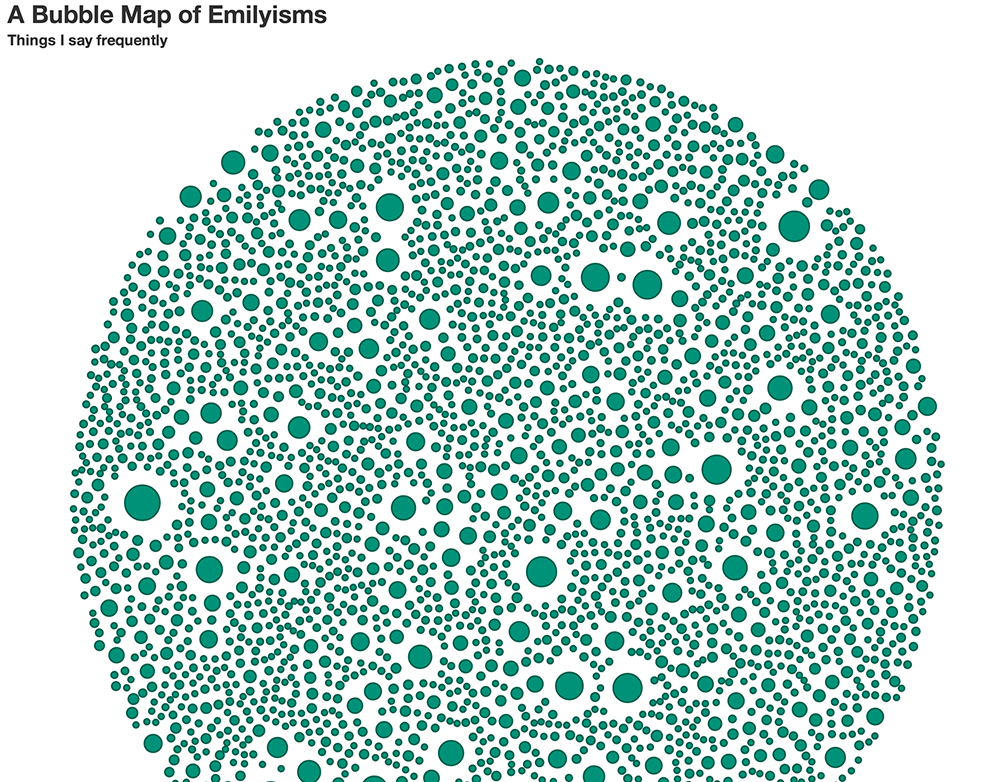
My original intent was for phrases with fewer words to be lighter colors, and phrases with more words to be darker. This way, I hoped to easily point out phrases which were uniquely mine. Many of the larger circles represent two-word combinations that I use frequently, but are not particularly Emily-like.

I mean, of course I say “and I” a lot
Through exploring data in the visualization, I did find some interesting patterns. For example, during my in-class critique, it was pointed out that I say “can you” twice as often as I say “I can.” That realization actually helped me shape the rest of my semester here, as silly as it sounds.
There are some definite emilyisms mixed in, but they are not highlighted:



The last picture represents a feature / quirk of NLTK: it knows to analyze conjunctions as two separate words. This may have affected my emilyism search.
Once I figure out coffeescript, I hope to highlight the phrases with fewer words, so the majority of the bubbles will be light green, and the ones with more words will be darker.