SankalpBhatnagar-FractalType
Coming soon.
Comments Off on SankalpBhatnagar-FractalType
This project was inspired by my recent experiences with learning and teaching origami. I had a 3 week residency at the Children’s museum where I taught people of all ages how to make paper sculptures from simple animal to more complex modular and tessellating patterns. I because really interested in the way people approached the folding, they were either eager to learn and confident in the ability to mold the paper into their desired form, or extremely skeptical that the result was going to work out. I still can’t see patterns beyon da certain complexity…I had no idea this: 
becomes this
:
I began thinking about how this mapping from 2D to 3D on a piece of paper occurs. There has a been a lot of research about projecting line drawings onto different planes to see when we see a 3D object.

At first, I thought that an autostereogram would help demonstrate the potential for a 2D object to become 3D, but then I realized it was a bit limiting since it cannot really be realized and compared as rapidly as other 3D viewing techniques. So I decided to go with stereovision. There is a Stereo library fro Processing that is fun to play with, but in the end it seemed like it would be easiest to write my own version.
The first program allows you to draw lines, or trails with the mouse and then create a stereo version of the image. It then shifts in place to pop out or pop in, generating a flip-book of sorts of the image you created.
The second program allows you to draw points on the canvas and then watch as lines randomly form between them to see what kind of 3D objects you can make with a given point range.
Here is a video illustrating what they can do (watch with red/green glasses if you can!)
The longer term goal is to combine this with origami crease finding algorithms such as Robert Lang’s treemaker: http://www.langorigami.com/science/computational/treemaker/treemaker.php#
and see if this could be a tool for designing 3D origami forms that seem like they would be impossible.
I’ve always been a big fan of abstract art, letting the stories twirl in my head around the shapes or along the brushstrokes. In this project, I ask, can robots walk through the space of emotional expression to achieve the same effect? The human mind is wonderful at making abstract connections, creating narrative and attributions of intent.
My clay was the Gamebot robot, a three-axis head and screen. Eventually intended to play boardgames with us on a touchscreen surface in the Gates Cafe, the project is led by my advisor Reid Simmons. In the first video below, I show a handcrafted robot expression.
Gamebot: “My Heart Hurts”
[vimeo=http://vimeo.com/37718056]
Traditionally the software used with this robot, which I had never worked before, has been developed and used for the Robo-Receptionist in Newell-Simon Hall. The Robo-Receptionist has a screen but no head motors, which required some adaptation of the code, as the mapping from ‘simulation’ to ‘robot’ sometimes produced motion that was abrupt, too fast, too slow, or not communicating the desired state/emotion.
Another reason to rework the code was to create more variable-based expressive states, in which amplitude and timing are controllable characteristics. The previous software mostly uses a categorical approach to emotions, by which I mean, emotional and expressive robot behaviors are scripted and discrete. The video below shows four possible states of waiting: happy, pensive, sad, mad. The is an example of an emotion model with categorical states.
Gamebot: Waiting State Machine
[vimeo=http://vimeo.com/37718158]
In contrast to this state machine, I show the robot running through continuously varying range of mood valence (this sample is face only, but will be used in conjunction with motion in the following step). Rather than use a state machine for emotion representation, I borrow a function called mood from the Robo-Receptionist to explore the space between happy and sad. By representing the continuous variable, I can next use shifting sequentials and generative algorithms to explore the space of expression.
Gamebot: Gradient of Happy to Sad
[vimeo=http://vimeo.com/37718557]
Next, I scripted a branching and looping function to combine mood state with emotion, in the hope that the unplanned creations would evoke stories in us, as we imbue the robot with intent. Throughout evolution, we have used our ability to “read” people and make snap decisions to safely and happily navigate the world. This same unconscious behavior occurs when we see a robot face or robot in motion.
The code: define parameters to constrain the lips to transitions between smile – neutral – frown or stay the same, while the head motion explores the space of an outer and inner square.
The story: the next step is the interpretation, each generation will be unique. I share my stories for the three videos below, but I invite any of you to craft your own. Watch for the lips and head motion!
In I, I see a tale of beauty and intimacy. The camera angles interplay with expression.
Generative Gamebot I: Beauty & Intimacy
[vimeo=http://vimeo.com/37718644]
In II, I see a robot interrupted by an unwanted video camera. The desire to look presentable conflicts with with her frustration at the imposition. Benign bickering likely to follow.
Generative Gamebot II: A Camera, Really?!
[vimeo=http://vimeo.com/37718902]
In III, the robot seems to be gazing into the mirror and thinking, “It’s hard to hide my unhappiness.” It practices smiling, occasionally despairing at the farse and letting it fade again.
Generated Gamebot III: Hard to Hide
[vimeo=http://vimeo.com/37719220]
The Big Ideas:
Excited to get a simple model up and running! Thoughts about more complex algorithms I could use to explore this space (especially motion) would be awesome!
The objective of this project is form generation via a Braitenberg vehicles simulation.
A Braitenberg vehicle is a concept developed by the neuroanatomist Valentino Braitenberg in his book “Vehicles, Experiments in Synthetic Psychology” (full reference: Braitenberg, Valentino. Vehicles, Experiments in Synthetic Psychology. MIT Press, Boston. 1984). Braitenberg’s objective was to illustrate that intelligent behavior can emerge from simple sensorimotor interaction between an agent and its environment without representation of the environment or any kind of inference.
What excites me about this concept is how simple behaviors on the micro-level can result to the emergence of more complex behaviors on the macro-level.
—————————————————————————————————————————————
Reas, Tissue Software, 2002






—————————————————————————————————————————————
There have been attempts in the field of dance performances to bring together explicitly movement with geometry. Two examples are described below:

Slat Dance, Oscar Schlemmer, Bauhaus, 1926
William Forsythe, imagines virtual lines and shapes in space that could be bent, tossed, or distorted. By moving from a point to a line to a plane to a volume, geometric space can be visualized as composed of points that were vastly interconnected. These points are all contained within the dancer’s body; an infinite number of movements and positions are produced by a series of “foldings” and “unfoldings”. Dancers can perceive relationships between any of the points on the curves and any other parts of their bodies. What makes it into a performance is the dancer illustrating the presence of these imagined relationships by moving.

Improvisation Technologies – Dance Geometry, OpenEnded Group, 1999
>> The computational tool
A Braitenberg vehicle is an agent that can autonomously move around. It has primitive sensors reacting to a predefined stimulus and wheels (each driven by its own motor) that function as actuators. In its simplest form, the sensor is directly connected to an effector, so that a sensed signal immediately produces a movement of the wheel. Depending on how sensors and wheels are connected, the vehicle exhibits different behaviors.

In the diagram below we can observe some of the resulting behaviors according to how the sensors and actuators are connected.

source: http://www.it.bton.ac.uk/Research/CIG/Believable%20Agents/
>> the environment
In the current project the environment selected to provide stimuli for the vehicles is a 3d stage where a number of spotlights are placed interactively by the user. The light patterns and colors can vary to actuate varying behaviors.
The vehicles can move in 3d space reacting to the light stimuli. The vehicles will be regarded as constituting the vertices of lines or the control points of surfaces which are going to get transformed and distorted over time. The intention is to constraint the freedom of movement of the vehicles by placing springs at selected points. The libraries of Toxiclibs, Verlet Physics and Peasycam are being used.


This project is an effort to simulate a battle between two armies. I had planned to simulate an army which comprised of the infantry, cavalry, archers and catapults. I eventually ended by doing a battle simulation with just the infantry. My idea for driven by one of my looking outwards – “Node Garden”, where a set of curves would twirl in space to create nodes. Based on the feedback I got, I focused on simulating the behavior of the infantry.
Initial Designs
Bow-Tie Problem
I decided to move the infantry to its nearest enemy. This resulted in biased results, where the infantry turned to the fastest enemy.

Revised Concept

Simulation
Simulation

At this point I was inspired to generate a hanging mobile that would dance to the music.



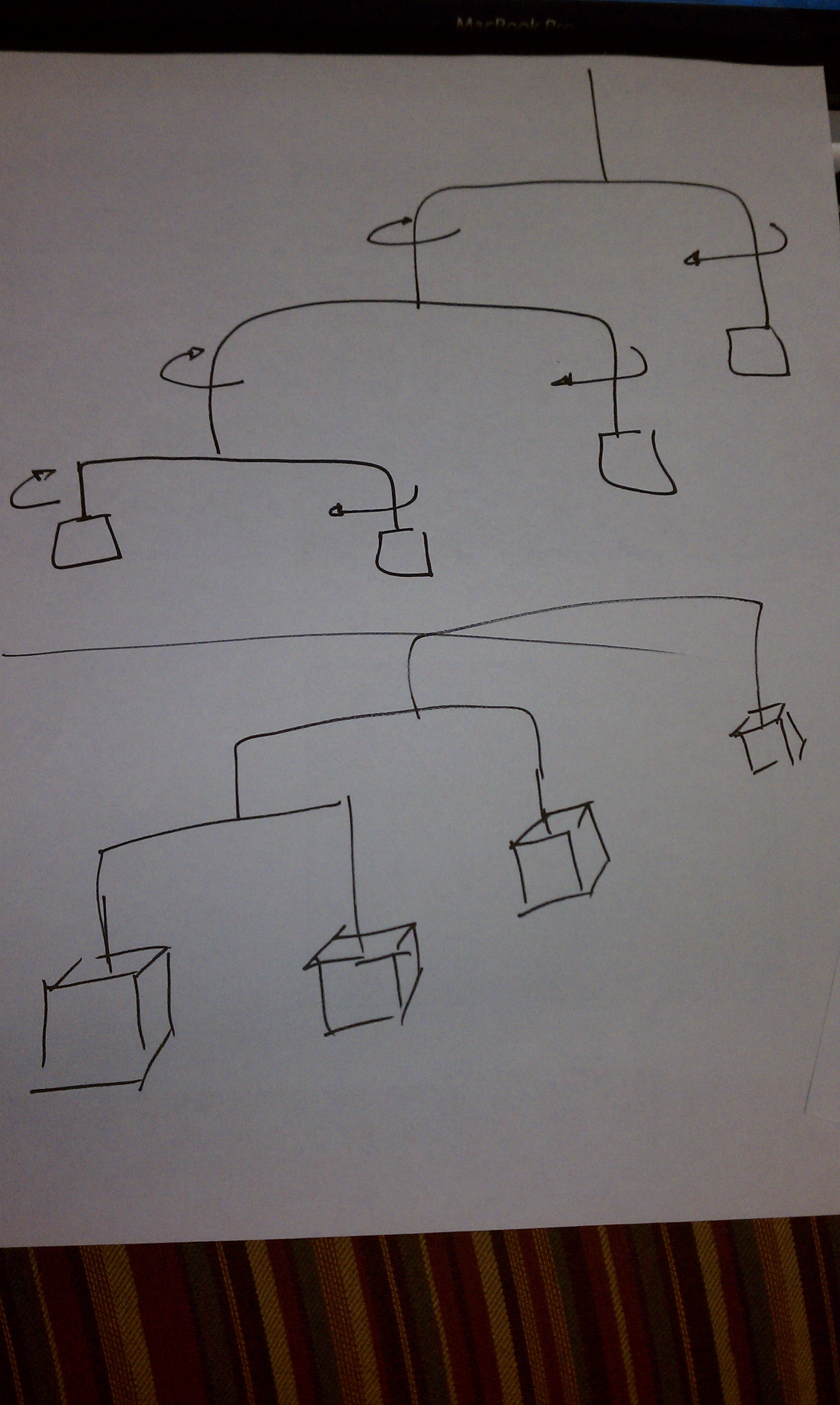

[youtube=http://www.youtube.com/watch?v=WOpIPqEFJcg]

I’m not entirely sure where the idea for this project came from. I was exploring several ideas for using flocking algorithms when I suddenly thought of evolving solutions to the egg drop problem using genetic algorithms.
[vimeo=http://vimeo.com/37727843]
I recall performing this “experiment” more than once during my childhood, but I don’t think I ever constructed a container that would preserve an egg from a one story fall. There was something very appealing about revisiting this problem in graduate school and finally conquering it.
[vimeo=http://vimeo.com/37725342]
I began this project working with toxiclibs. It’s springs and mesh structures seemed like good tools for constructing an egg drop simulation. It’s lack of collision detection, however, made it difficult to coordinate the interactions of the egg with the other objects in the simulation. On to Box2D…
Box2D made it pretty easy to detect when the egg had collided with the ground. Determining whether or not the egg had broken was simply a matter of looking at its acceleration, and if that was above some threshold (determined experimentally), it broke.
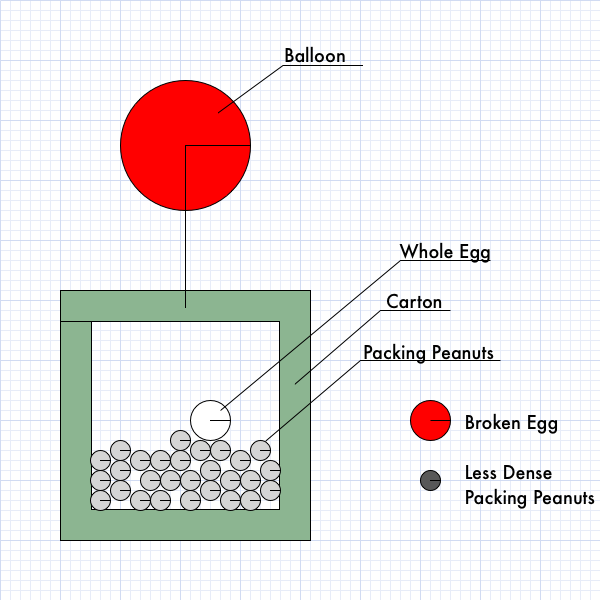
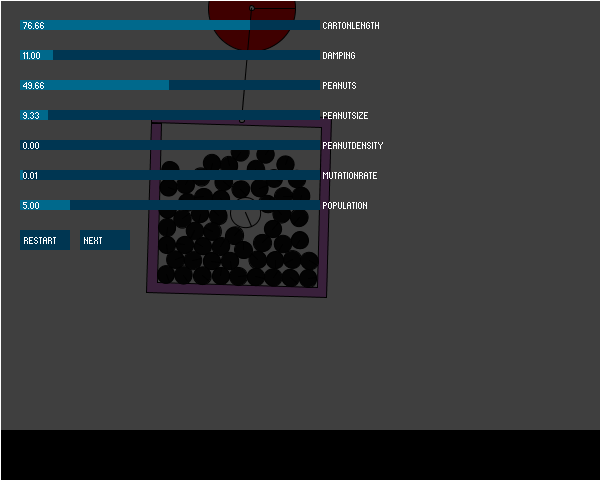
What interventions can you make to preserve an egg during a fall? The two obvious solutions are 1) make the egg fall slower so it lands softly and 2) pack it in bubble wrap to absorb the force. These were two common solutions I recalled from my childhood. I used a balloon in the simulation to slow the contraption’s fall, and packing peanuts inside to absorb the impact when it hits the ground. This gave me several parameters which I could vary to breed different solutions: bouancy of the balloons to slow the fall; density of the packing peanuts to absorb shock; packing density of peanuts in the box. Additionally, I varied the box size and the peanut size both of which affect the number of peanuts that will fit in the box.
I also varied the color of the container, just to make it slightly more obvious that these were different contraptions.
My baseline for evaluating a contraption’s fitness was how much force beyond the minimum required to break the egg was applied to the egg on impact. A contraption that allowed the egg to be smashed to pieces was less fit then one that barely cracked it. To avoid evolving solutions that were merely gigantic balloons attached to the box, or nothing more than an egg encased in bubble wrap, I associated a cost with each of the contraption’s parameters. Rather than fixing these parameters in the application, I made them modifiable through sliders in the user interface so that I could experiment with different costs.
My initial idea for this project was to simulate a line or a crowd, by implementing a combination of flocking / steering algorithms. I planned to set some ground rules and test how the crowd behaves when interesting extreme characters enter the crowd and behave completely differently. Will the crowd learn to adapt? Will it submit to the new character?
After playing around with ToxicLibs to generate the queue, I thought about an idea that interested me more, so I only got as far as modeling one of the queues:
William Paley was a priest, who lived back in the 19th century. He coined one of the famous argument in favor of god’s existance and the belief that everything we see is designed for a purpose (by god, of course). As a rhetoric measure, he used to talk about a watch, and how complicated and synchronized need all its parts be for it to function well. In a similar fashion, are all other things we see around us on earth and beyond.
I wanted to use this lab assignment to play with evolution and see if I can create a set of rules that will generate a meaningful image out of a pool of randomly generated images. Following Daniel Shiffman’s book explanation about genetic algorithms, I designed a program that tries to generate a well-known image from a pool of randomly generated images. The only “cheat” here is that the target image was actually used to calculate the fitness of the images throughout the runtime of the program. Even with that small “cheat”, this is not an easy task! There are so many parameters that can be used to fine-tune the algorithm:
1. Pool size – how many images?
2. Mating pool size – How many images are in the mating pool. This parameter is especially important for a round where there are some images with little representation. If the mating pool is small, they will be eliminated and vice versa.
3. Mutation rate – is a double sided knife, as I have learned. Too much mutations, and you never get to a relatively stable optimum. Too little mutation, and you get nowhere.
4. Fitness function – This is the hardest part of the algorithm. To come up with criteria that measures what is “better” than another. As explained above, for this lab I knew what is my target, so I could calculate the fitness much easier. I used color distance for that: For each pixel in the image, I compared the three colors with the other image. The closer you are, the more fitness you have, and bigger your chances to mate for the next round.
5. Last,but not least – performance. These algorithms are time consuming and cpu consuming. When trying an image of 200×200, the computer reacted really slowly. I ended up with an optimum of 100px square images for the input assignment.
Following is a short movie that shows one run of the algorithm. The image is never drawn right. There are always fuzzy colors and in general it looks “alive”.
The End.
Not a Prayer
I started this project with the idea of generating a group of creatures that would worship the mouse as their creator. The sound I knew was going to be critical. I discovered a pack of phoneme-like sounds from batchku at the free sound project. I used the Ess library for processing to string these together into an excited murmur. It didn’t sound much like praying but I liked the aesthetic. In order to create the visuals I took a cue from Karsten Schmidt’s wonderful project “Nokia Friends.” I put the creatures together as a series of springs using the toxiclibs physics library.
Here are some of my early character tests:


Getting the characters together took a lot of tweaking. I wanted as much variation in the forms as possible but I also wanted the bodies to be structurally sound. I found that the shapes had a tendency to invert, sending the springs into a wild twirling motion. This was sort of a fun accident but I wanted to minimize it as much as possible.
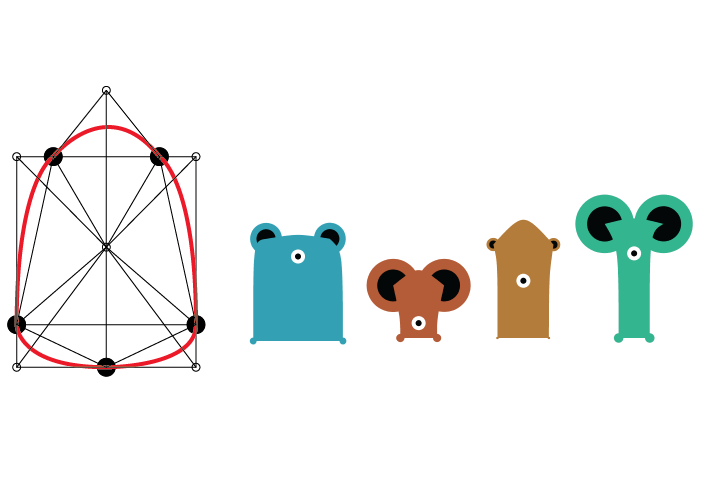
Here is the structural design of my creature along with some finished characters:


At this point I focused on the behavior of the creatures. I used attraction forces from toxiclibs to keep the creatures moving nervously around the screen. I also added some interactivity. If the user places the mouse over the eye of a creature it leaps into the air and lets out an excited gasp. Clicking the mouse applies an upward force to all of the creatures so that you can see them leap or float around the screen.
Here is a screen capture of me playing with the project:
[youtube http://www.youtube.com/watch?v=sMfVkc9OhU0&w=480&h=360]