var diameter = 600,
padding = 1.5, // separation between same-color nodes
clusterPadding = 4, // separation between different-color nodes
maxRadius = diameter/7;
numWords = 150;
var svg = d3.select(“.chart”).append(“svg”)
.attr(“width”, diameter)
.attr(“height”, diameter);
var n = numWords, // total number of nodes
m = 31; // number of distinct clusters
words = [];
occurences = [];
pos = [];
rowArr = [];
var clusterNames = [”, ‘FW’, ‘DET’, ‘WH’, ‘VBZ’, ‘VB+PPO’, “‘”, ‘CNJ’, ‘PRO’, ‘*’, ‘,’, ‘TO’, ‘NUM’, ‘NP’, ‘:’, ‘UH’, ‘ADV’, ‘VBG+TO’, ‘VD’, ‘VG’, ‘VBN+TO’, ‘VN’, ‘N’, ‘P’, ‘EX’, ‘V’, ‘ADJ’, ‘VB+TO’, ‘(‘, null, ‘MOD’];
var CSV = d3.csv(“http://golancourses.net/2014/wp-content/uploads/2014/02/words1.csv”, function(d) {
words.push(d.lyric),
occurences.push(+d.occurence);
pos.push(d.pos);
}, function(error, rows) {
console.log(words.length);
console.log(occurences.length);
var clusters = new Array(m);
var nodes = d3.range(numWords).map(function(element,index,array) {
var clusterInd = clusterNames.indexOf(pos[index]),
r = maxRadius*occurences[index]/occurences[0],
d = {
cluster: clusterNames.indexOf(pos[index]),
radius: r,
lyric: words[index],
occurence: occurences[index],
pos: pos[index]
};
if (!clusters[clusterInd] || r > clusters[clusterInd].radius) clusters[clusterInd] = d;
return d;
});
var tip = d3.tip()
.attr(‘class’, ‘d3-tip’)
.offset([-10, 0])
.html(function(d) {
return “” + d.lyric + ““;
})
// Use the pack layout to initialize node positions.
d3.layout.pack()
.sort(null)
.size([diameter, diameter])
.children(function(d) { return d.values; })
.value(function(d) { return d.radius * d.radius; })
.nodes({values: d3.nest()
.key(function(d) { return d.cluster; })
.entries(nodes)});
var force = d3.layout.force()
.nodes(nodes)
.size([diameter, diameter])
.gravity(.03)
.charge(0)
.on(“tick”, tick)
.start();
/*var svg = d3.select(“.chart”).append(“svg”)
.attr(“width”, diameter)
.attr(“height”, diameter);*/
svg.call(tip);
var coordinates = [0,0];
var circle = svg.selectAll(“circle”)
.data(nodes)
.enter().append(“circle”)
.style(“fill”, function(d){
if (d.pos == “”)
return “yellowgreen”;
else if (d.pos == “FW”)
return “turqoise”;
else if (d.pos == “DET”)
return “slateblue”;
else if (d.pos == “WH”)
return “royalblue”;
else if (d.pos == “VBZ”)
return “firebrick”;
else if (d.pos == “VB+PPO”)
return “purple”;
else if (d.pos == “‘”)
return “darkred”;
else if (d.pos == “CNJ”)
return “gold”;
else if (d.pos == “PRO”)
return “indigo”;
else if (d.pos == “*”)
return “lawngreen”;
else if (d.pos == “,”)
return “magenta”;
else if (d.pos == “TO”)
return “moccasin”;
else if (d.pos == “NUM”)
return “navy”;
else if (d.pos == “NP”)
return “peru”;
else if (d.pos == “:”)
return “plum”;
else if (d.pos == “UH”)
return “powderblue”;
else if (d.pos == “ADV”)
return “tan”;
else if (d.pos == “VBG+TO”)
return “tomato”;
else if (d.pos == “VD”)
return “crimson”;
else if (d.pos == “VG”)
return “darkgreen”;
else if (d.pos == “VBN+TO”)
return “dimgray”;
else if (d.pos == “VN”)
return “lightblue”;
else if (d.pos == “N”)
return “brown”;
else if (d.pos == “P”)
return “forestgreen”;
else if (d.pos == “EX”)
return “lightseagreen”;
else if (d.pos == “V”)
return “mediumorchid”;
else if (d.pos == “ADJ”)
return “aqua”;
else if (d.pos == “VB+TO”)
return “indianred”;
else if (d.pos == “(“)
return “lightslategray”;
else if (d.pos == null)
return “salmon”;
else
return “thistle”;
})
.on(‘mouseover’, function(d){
tip.show(d);
d3.select(this)
.style(“stroke”,”#000″).style(“stroke-width”,3);
})
.on(‘mouseout’, function(){
tip.hide();
d3.select(this)
.style(“stroke”,”#000″).style(“stroke-width”,0);
});
circle.call(force.drag);
circle.transition()
.duration(250)
.delay(function(d, i) { return i * 5; })
.attrTween(“r”, function(d) {
var i = d3.interpolate(0, d.radius);
return function(t) { return d.radius = i(t); };
});
function tick(e) {
circle
.each(cluster(10 * e.alpha * e.alpha))
.each(collide(.1))
.attr(“cx”, function(d) { return d.x; })
.attr(“cy”, function(d) { return d.y; });
}
// Move d to be adjacent to the cluster node.
function cluster(alpha) {
return function(d) {
var cluster = clusters[d.cluster];
if (cluster === d) return;
var x = d.x – cluster.x,
y = d.y – cluster.y,
l = Math.sqrt(x * x + y * y),
r = d.radius + cluster.radius;
if (l != r) {
l = (l – r) / l * alpha;
d.x -= x *= l;
d.y -= y *= l;
cluster.x += x;
cluster.y += y;
}
};
}
// Resolves collisions between d and all other circles.
function collide(alpha) {
var quadtree = d3.geom.quadtree(nodes);
return function(d) {
var r = d.radius + maxRadius + Math.max(padding, clusterPadding),
nx1 = d.x – r,
nx2 = d.x + r,
ny1 = d.y – r,
ny2 = d.y + r;
quadtree.visit(function(quad, x1, y1, x2, y2) {
if (quad.point) {
if (quad.point !== d) {
var x = d.x – quad.point.x,
y = d.y – quad.point.y,
l = Math.sqrt(x * x + y * y),
r = d.radius + quad.point.radius + (d.cluster === quad.point.cluster ? padding : clusterPadding);
if (l < r) { l = (l - r) / l * alpha; d.x -= x *= l; d.y -= y *= l; quad.point.x += x; quad.point.y += y; } } } return x1 > nx2 || x2 < nx1 || y1 > ny2 || y2 < ny1;
});
};
}
});
[/d3-source]
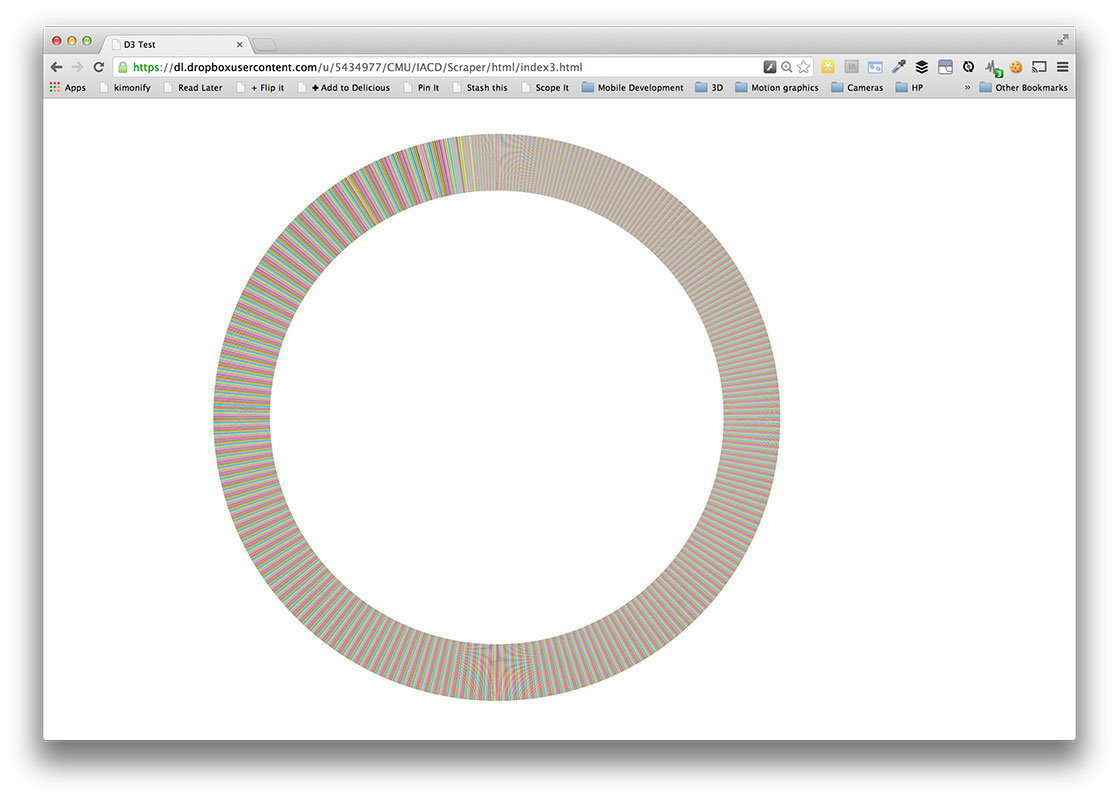
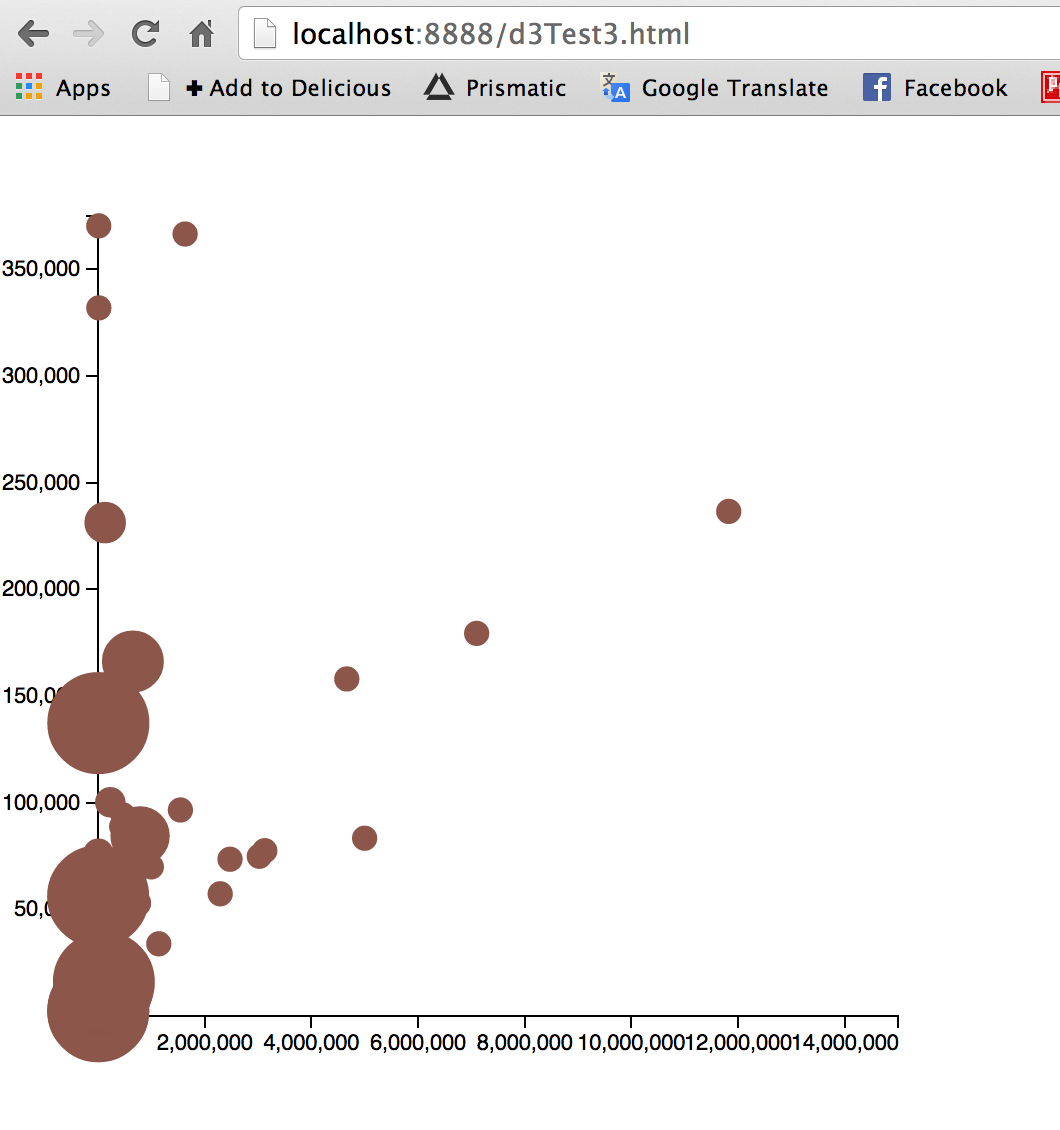
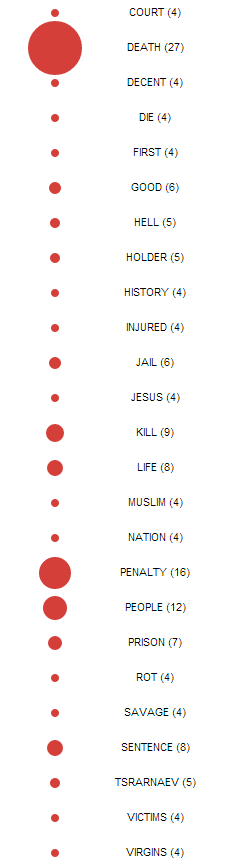
The above is a d3 visualization of the 150 most prevalent lyrics in popular music since 2006. The lyrics are clustered by the part of speech to which the word belongs. The data collection incorporated a number of APIs and processing techniques in order to make it into the visualization. First, the Billboard music chart website was scraped for artists and titles of the top songs per year since 2006 using an API formed by Kimono . Second, the Lyric Wiki API was used in conjunction with Beautiful Soup to extract lyrics for these songs in a Python script. Next, the data was parsed and processed using some disgusting regular expressions and the Natural Language Toolkit with the Brown University Standard Corpus of Present-Day American English to separate the words and assign parts of speech to each word. Finally, I managed to get that data input to the Cluster Force Layout IV by Mike Bostock. I also incorporated d3-tip to show the actual lyrics in the data.
At the moment, the visualization is basically a less informative histogram with some bits to explore. One of its only redeeming qualities is the ability to toss the information about the screen. The only interesting feature of the data shown is the large concentration of word usage with little variation. The data needs to be reorganized to show changes over time or differences in genre, or more data should be collected to compare the lyrical data to other modes of language such as normal speech.
Fortunately, this was a tremendous learning experience. Previously, I had done little programming that interfaced with a web application, much less and sort of large scale data scraping, nor had I ever written any sort of Python script. I got a bit more experience with Javascript but any sort of command of that language still eludes me.