Datascraping Assignment
For this project I have scraped some data about New York Times articles that are in some way related to various words related to entertainment or leisure activities including: “Board Game”, “Game”, “Computer Game”, “Gambling”, “Sport”, “Fun”, “Arcade”, “Competition”, “Amusement”, “Entertainment”, “Movie”, “Drinking”, “Beach”, “Reading”, and “Music”. For each of these words I scraped 1000 records each. I learned how to write a programmatic data scraper (At least the beginners version using Temboo) and had to think about what data I could get from the internet. I started out thinking about trying to get a list of data such as statistics about stuttering or a list of the names of every board game in existence. I then realized that if I wanted such as list, I would either have to find a list file that someone else out in the wild had compiled or compile my own list to be used as input terms for a public API. Either way such a list was not to be found by data scraping, so I had to revise my approach. I decided to scrape data about entertainment activities to try to find a data set that would shed some light upon how the media, specifically the New York Times, represents and perceives different forms of entertainment.
Here is a link to the code that I used to scrape the data: https://github.com/Bryce-Summers/IACD-Datascraping
Amazingly Rough Sketch:
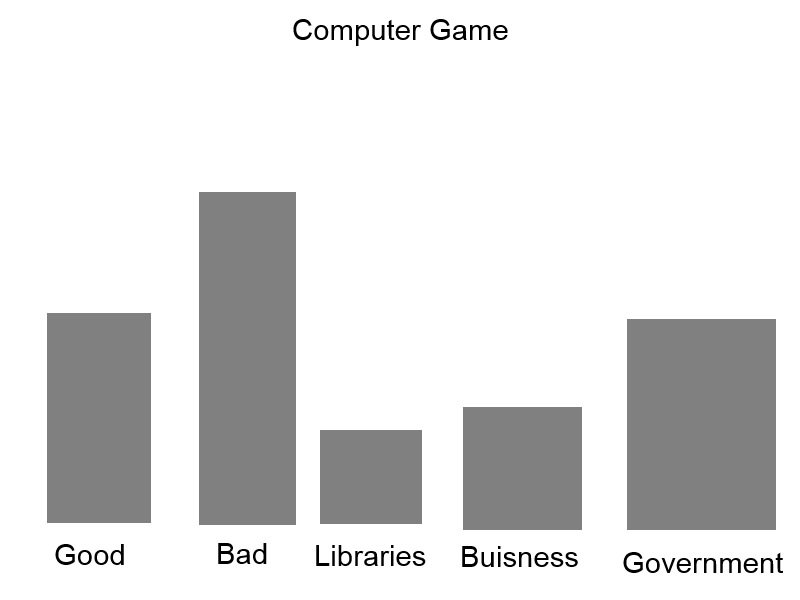
In the future Information visualization project, I will attempt to display relationships between the data I received, which may or may not relate to the terms the I was looking for.
Here is some of the data that I have collected:
https://github.com/Bryce-Summers/IACD-Datascraping/tree/master/Sample%20of%20Data
I have decide to provide a link to the files instead of embedding the text into this webpage, because the JSON files are so verbose that they crash this blog post.