I chose to collect alchemical texts from a rather unorganized and outdated-looking website simply titled “The Alchemy Website”. This website hosts several hundred alchemical texts (manuscripts, poetry, etc.) but lacks a proper database/API with which to fetch any of the data… Plus, the links to the texts sprawl across pages, with some links taking you to tables of contents filled with more links, with each page sometimes having a different layout. Some links were even broken.
There’s some very interesting and hard to find stuff in plain text on this website, so it would be a shame if it was lost, so I wrote a very hacked-together text scraper that’s supposed to retrieve raw alchemy texts from the site. It works fairly well (there could be a lot of improvements, though) and I was able to gather a good 2MB of decent text.
I’m not sure what I want to do with this data (it’s a very strange set of data) but as a small proof of concept to show that this data isn’t completely useless, I threw together a Twitter bot that periodically tweets random words of wisdom from the data:
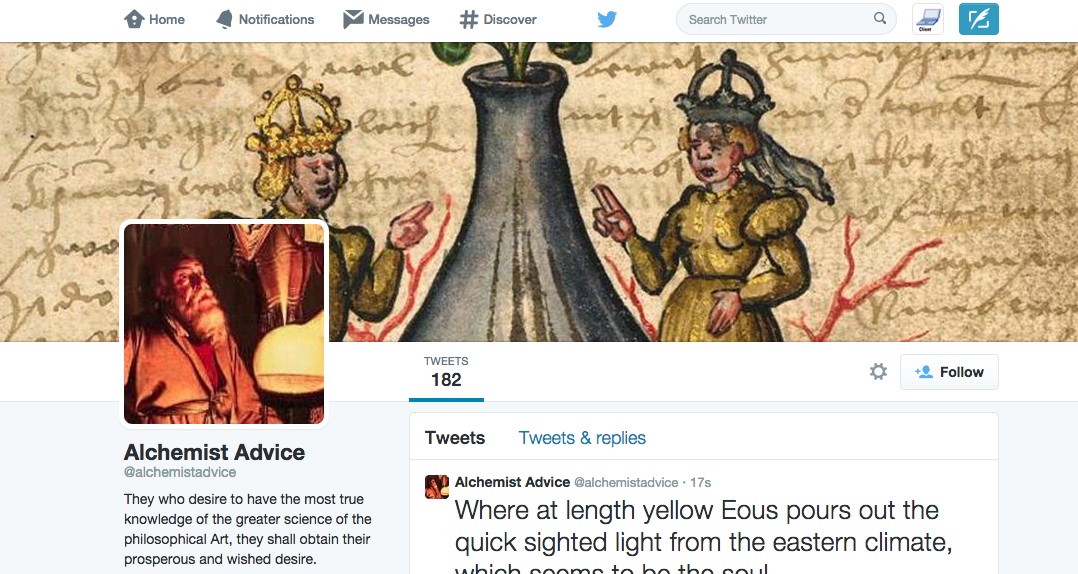
(ok so this data is like pretty useless…not sure if i should continue with it or find something else to use)
Here’s the very hacky could-be-better scraper:
from bs4 import BeautifulSoup
import re
import requests
TAG_RE = re.compile(r'< [^>]+>')
def remove_tags(text):
return TAG_RE.sub('', text)
def parsePage(pageName):
print "downloading text from " + pageName
currentPage = 'http://www.alchemywebsite.com/' + pageName
pageRequest = requests.get(currentPage)
pageData = pageRequest.text
pageData = pageData.split('
')[1]
pageData = pageData.split('
')[0]
pageDataSoup = BeautifulSoup(pageData)
pageLinks = soup.find_all('a')
if(len(pageLinks) > 0):
for p in pageLinks:
#parsePage(pageName)
print p
else:
pageData = remove_tags(pageData)
pageData = pageData.replace(" ","")
pageData = pageData.encode('ascii',errors='ignore')
pageData = pageData.replace('\n',' ').replace('\r',' ')
text_file = open("texts/" + pageName + ".txt", "w")
text_file.write(pageData)
text_file.close()
#assert(False)
r = requests.get("http://www.alchemywebsite.com/texts_16th.html")
data = r.text
soup = BeautifulSoup(data)
#links = soup.find_all('a')
#for i in range(60,124+1):
# print i
# print links[i].get('href')
#assert(False)
links = soup.find_all('a')
for i in range(60,124+1):
pageName = links[i].get('href')
parsePage(pageName)
And here’s the code for the Twitter bot:
import com.temboo.core.*;
import com.temboo.Library.Twitter.Tweets.*;
import java.io.File;
import java.io.FilenameFilter;
TembooSession session = new TembooSession("devbegolag", "myFirstApp", "85399646c0df42d5a5624b9222f86d1a");
void setup() {
while(true) {
String result = "";
while(result.length() < 100 || result.length() > 140) {
File f = new File("/Users/zachrispoli/desktop/alchemistadvice/texts/");
String[] files = f.list(new FilenameFilter() {
public boolean accept(File dir, String name) {
return name.toLowerCase().endsWith(".txt");
}
});
int textIndex = int(random(files.length));
String fileToReadFilename = files[textIndex];
println("Reading from: " + fileToReadFilename);
String lines[] = loadStrings("/Users/zachrispoli/desktop/alchemistadvice/texts/"+fileToReadFilename);
String line = lines[0];
//println(line);
String sentences[] = line.split("\\.");
int sentenceIndex = int(random(sentences.length));
result = sentences[sentenceIndex] + ".";
println(result);
}
runStatusesUpdateChoreo(result);
delay(30000);
}
}
void runStatusesUpdateChoreo(String tweet) {
StatusesUpdate statusesUpdateChoreo = new StatusesUpdate(session);
statusesUpdateChoreo.setAccessToken("xxxxx");
statusesUpdateChoreo.setAccessTokenSecret("xxxxx");
statusesUpdateChoreo.setConsumerSecret("xxxxx");
statusesUpdateChoreo.setStatusUpdate(tweet);
statusesUpdateChoreo.setConsumerKey("xxxxx");
StatusesUpdateResultSet statusesUpdateResults = statusesUpdateChoreo.run();
//println(statusesUpdateResults.getResponse());
}