“3D portraits drawn by a light-painting industrial robotic arm.”
My partner Jeff Crossman and I are working on getting a industrial robotic arm to paint a 3D, digital scan of a person or object, in full color. The project makes use of a kinect to get the scanned image of a person, and uses Processing to output the points and their associated pixel color. From there we use the plugins Grasshopper and HAL in Rhino, to generate the point cloud and subsequently the robot code. The plugins also allow us to control the robot’s built-in ability to send digital and analog signals, which we use pulse a Blinkm led at the end of the arm at precisely the right time, drawing the point cloud.
This project is an exploration into an American Sign Language (ASL) translation using 3D cameras.
An automated ASL translation system would allow deaf individuals to communicate with non-signers in their natural language. Continuing improvements in language modeling and 3D sensing technologies make such system a tantalizing possibility. This project is an exploration of the feasibility of using existing 3D cameras to detect and translate ASL.
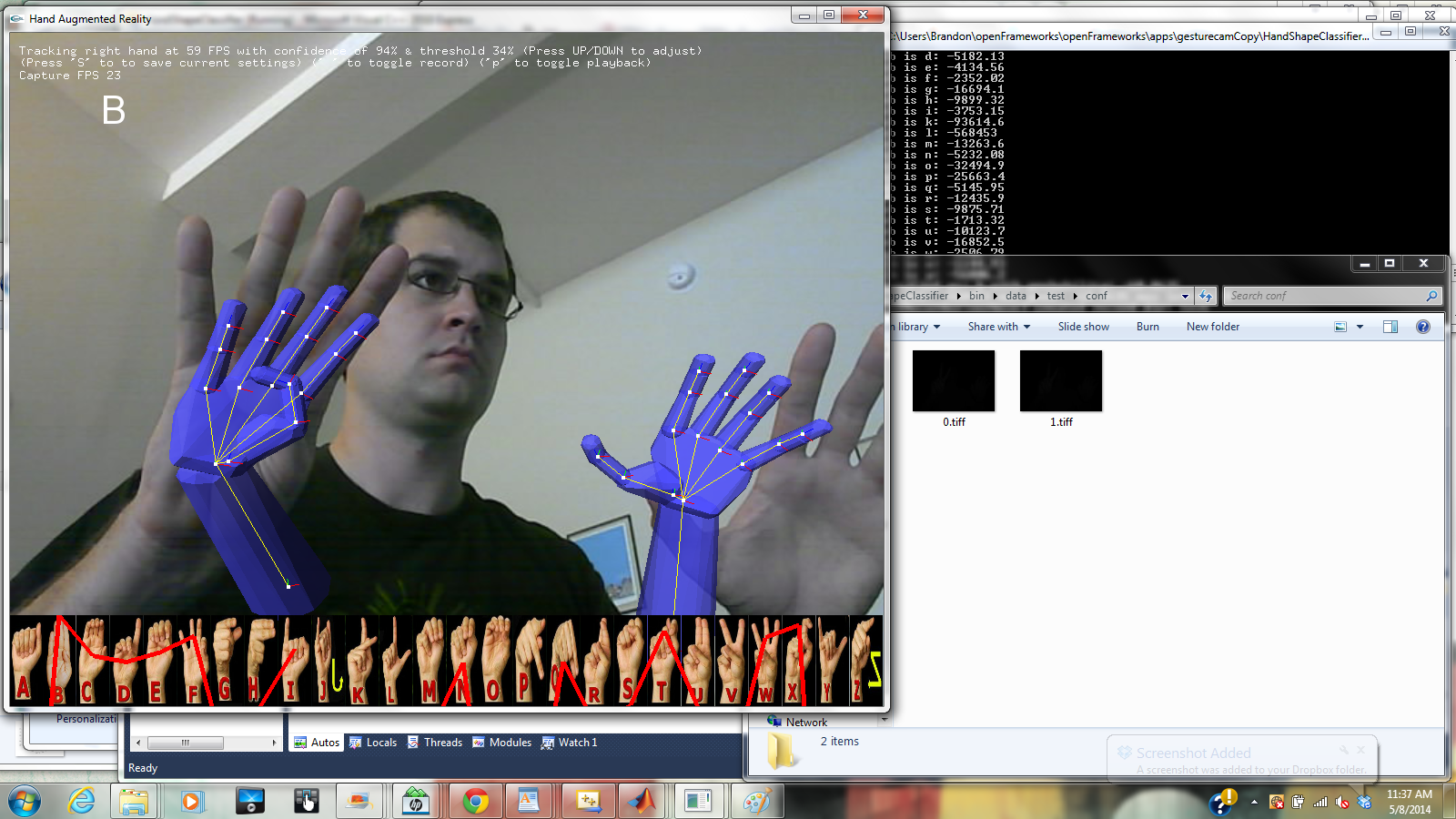
This project uses a Creative Interactive Gesture Camera as a testbed for exploring an ASL translation system in openFrameworks. The application is split into two parts: a data collection mode for recording training data and a classification mode for testing recognition algorithms. Thus far, only static handshape classification has been implemented. The video below demonstrates the classification mode.
Currently, the classification algorithm is only run when a key is pressed. A likelihood is calculated for each of the 24 static alphabet signs for which handshape models have been trained (the signs for ‘J’ and ‘Z’ involve movements and were thus excluded from this version). The probabilities are plotted over the corresponding letter-sign images at the bottom of the screen. As implemented, the letter with the highest probability is indicated, regardless of the absolute probability (thus a letter will be selected even if the current handshape does not truly correspond to any letter).
American Sign Language signs are composed of 5 parameters:
-Handshape (finger positions)
-Location (location of hands relative to the body)
-Palm Orientation (hand orientation)
-Movement (path and speed of motion)
-Non-Manual Markers (facial expressions, postures, head tilt)
In order to develop a complete translation system, all 5 parameters must be detected. At that point, there is still a language translation problem to account for the grammatical differences between ASL and English. A variety of sensor approaches have been explored in previous research, though to date, no automated system has approached the recognition accuracy of a knowledgable signer viewing a video feed.
At first, I looked into using a Leap Motion controller and/or Kinect. Both devices have been used in previous research efforts (Microsoft Research, MotionSavvy), but both have drawbacks. The Leap Motion has a limited range, making several parameters (Non-Manual Markers, Location, Movement) difficult to detect. The first generation Kinect, on the other hand, lacks the fine spatial resolution necessary for precise handshape detection.
The Creative Interactive Gesture Camera sits nicely between these sensors with finger-level resolution at a body-scaled range.
In fact, it is possible that the Creative 3D camera can detect all 5 ASL parameters. However, due to time constraints, the scope of this project has been limited to static handshape detection. While there are approximately 50 distinct handshapes used in ASL, I have focused on just classifying the alphabet for presentation clarity.
The results thus far have been positive, however there remains work to be done. Optimizations need to be made to balance the model complexity and classification speed. While this is not so important as implemented (with on-click classification), for a live system classification speed is an important factor. Also, handshapes that are not used in the alphabet need to be trained. Using only the alphabet makes for a clear presentation, but the alphabet characters are not more important than other handshapes for a useful system. Lastly, as with any modeling system, more training data needs to be collected.
I intend to continue developing this project and hope to make significant progress in the coming months. My current plans are to pursue the following developments in parallel: 1. Train and test the static handshape classifier with fluent signers 2. Implement a dynamic model to recognize signs with motions. I’m also interested in seeing how well the new model of the Kinect will work for such a system.
An openFrameworks application that highlights unique passages in each day’s readings.
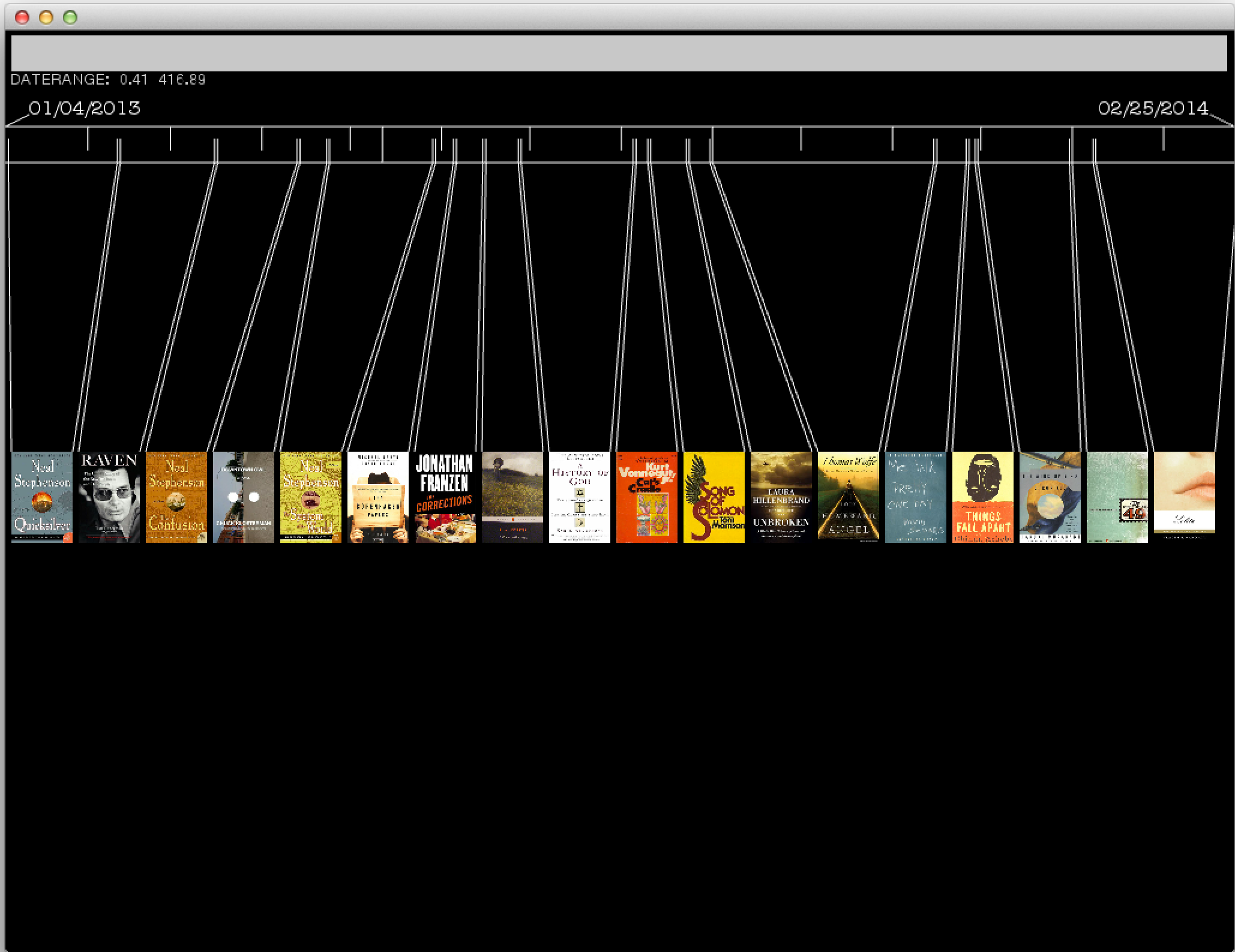
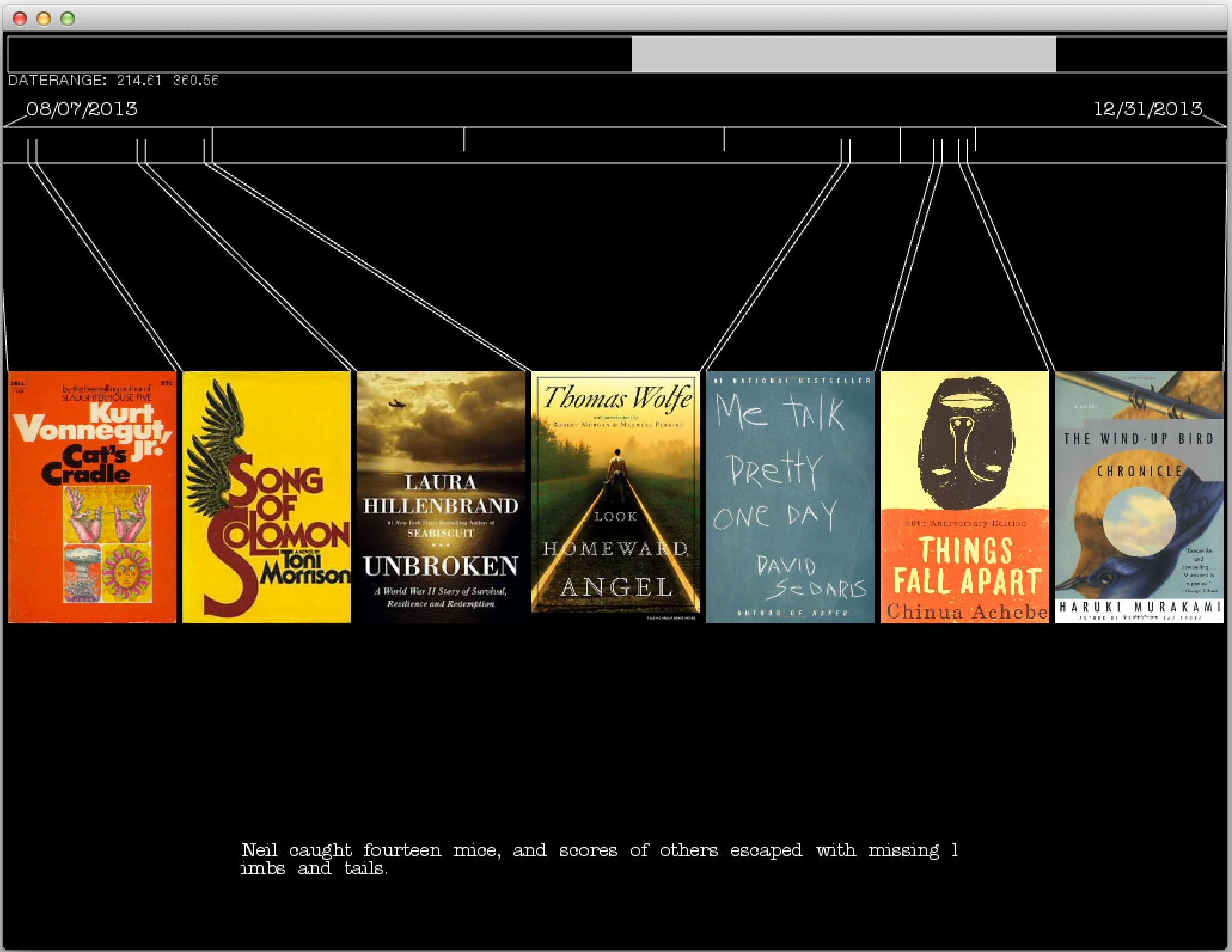
The application interface consists of a slider along the top that controls a range of dates. Books that were read during the selected time range are then displayed in the center of the screen with markers on the timeline corresponding to the start and end dates of that book.
[Wide Range Photo]
Moving the mouse along the timeline will then select a day an individual day. If any reading occurred on that day, the text that was read is analyzed against the entirety of the book. The sentence containing the most unique phrase in a given day’s reading is then displayed.
[Detailed tf-idf Photo]
The application is built with openFrameworks. The text analysis is done using Beautiful Soup and the Natural Language Toolkit in Python. Currently, data tracking the books and pages read over time are manually recorded in a CSV file.
The first version of the application (seen below) performed similar frequency analyses with several more information sources (fitness trackers, financial data, etc.). However, the interface was poorly developed. Trying to throw more data into a single common interface, simply muddied the execution. Focusing only on the text analysis resulted in a much cleaner project.
My project is a pair of sound sculptures created with old telephones, which were hacked to become audio recording / playback devices. The first telephone is used purely for audio playback, where dialing phone numbers accesses certain recordings stored in an SD card. The second telephone serves as both an audio recording and playback device.
I don’t have video documentation of the progress, so here’s a pretty photo instead:
For the first phone: I was able to hack into the phone speaker and have it play back recordings by dialing telephone numbers. I also got the Arduino to detect whether the handset is on or off the hook–so people can hang up the phone and the playback will stop.
For the second phone: I managed to get the recording to work with the internal microphone. All I have to do now is fiddle with the speakers + handset and I’m good to go! The code is already completed. Not sure if I’ll add a feature for the rotary dial–maybe if I have time.