This project is an exploration into an American Sign Language (ASL) translation using 3D cameras.
An automated ASL translation system would allow deaf individuals to communicate with non-signers in their natural language. Continuing improvements in language modeling and 3D sensing technologies make such system a tantalizing possibility. This project is an exploration of the feasibility of using existing 3D cameras to detect and translate ASL.
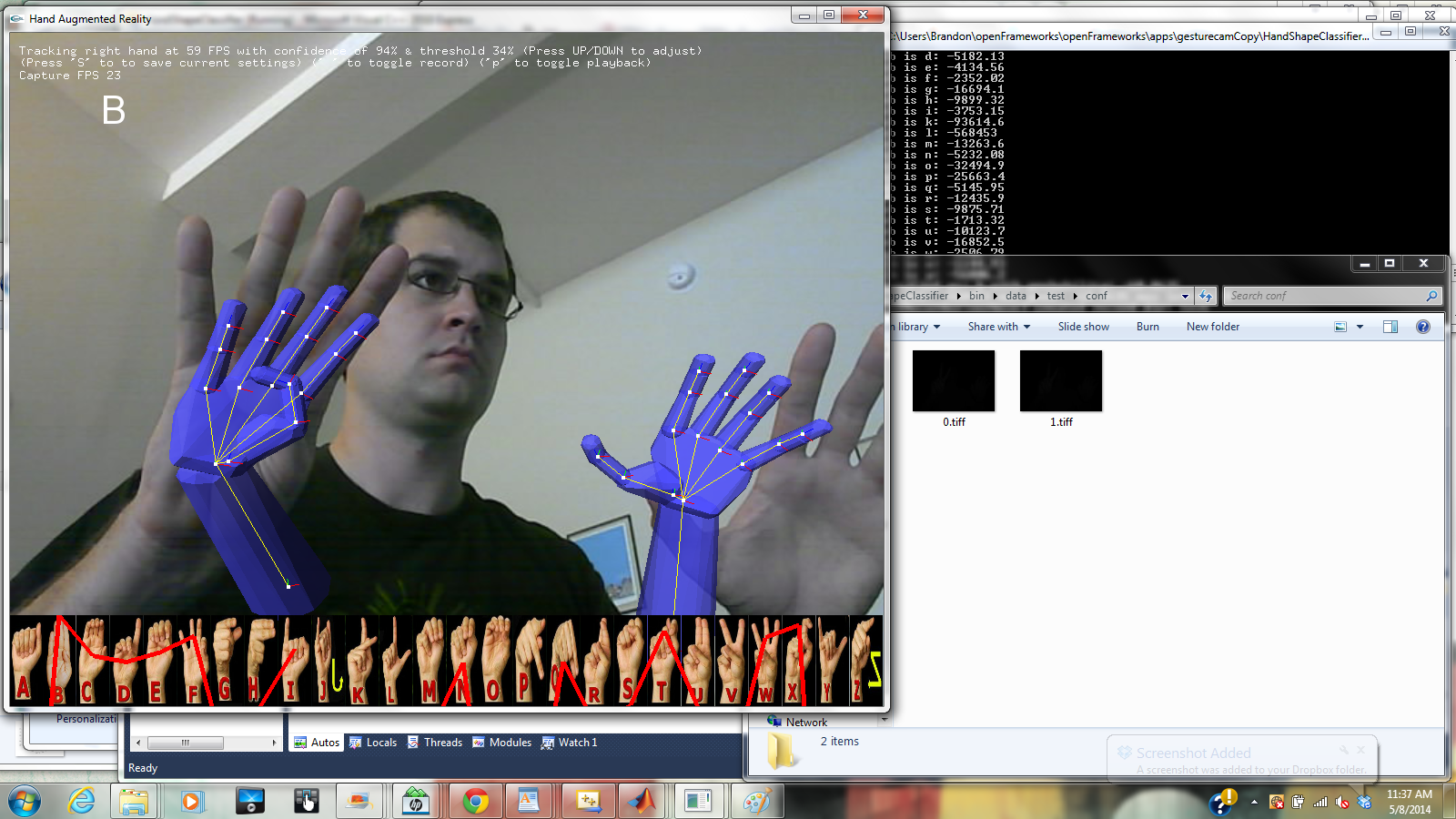
This project uses a Creative Interactive Gesture Camera as a testbed for exploring an ASL translation system in openFrameworks. The application is split into two parts: a data collection mode for recording training data and a classification mode for testing recognition algorithms. Thus far, only static handshape classification has been implemented. The video below demonstrates the classification mode.
Currently, the classification algorithm is only run when a key is pressed. A likelihood is calculated for each of the 24 static alphabet signs for which handshape models have been trained (the signs for ‘J’ and ‘Z’ involve movements and were thus excluded from this version). The probabilities are plotted over the corresponding letter-sign images at the bottom of the screen. As implemented, the letter with the highest probability is indicated, regardless of the absolute probability (thus a letter will be selected even if the current handshape does not truly correspond to any letter).
American Sign Language signs are composed of 5 parameters:
-Handshape (finger positions)
-Location (location of hands relative to the body)
-Palm Orientation (hand orientation)
-Movement (path and speed of motion)
-Non-Manual Markers (facial expressions, postures, head tilt)
In order to develop a complete translation system, all 5 parameters must be detected. At that point, there is still a language translation problem to account for the grammatical differences between ASL and English. A variety of sensor approaches have been explored in previous research, though to date, no automated system has approached the recognition accuracy of a knowledgable signer viewing a video feed.
At first, I looked into using a Leap Motion controller and/or Kinect. Both devices have been used in previous research efforts (Microsoft Research, MotionSavvy), but both have drawbacks. The Leap Motion has a limited range, making several parameters (Non-Manual Markers, Location, Movement) difficult to detect. The first generation Kinect, on the other hand, lacks the fine spatial resolution necessary for precise handshape detection.


The Creative Interactive Gesture Camera sits nicely between these sensors with finger-level resolution at a body-scaled range.

In fact, it is possible that the Creative 3D camera can detect all 5 ASL parameters. However, due to time constraints, the scope of this project has been limited to static handshape detection. While there are approximately 50 distinct handshapes used in ASL, I have focused on just classifying the alphabet for presentation clarity.

The results thus far have been positive, however there remains work to be done. Optimizations need to be made to balance the model complexity and classification speed. While this is not so important as implemented (with on-click classification), for a live system classification speed is an important factor. Also, handshapes that are not used in the alphabet need to be trained. Using only the alphabet makes for a clear presentation, but the alphabet characters are not more important than other handshapes for a useful system. Lastly, as with any modeling system, more training data needs to be collected.
I intend to continue developing this project and hope to make significant progress in the coming months. My current plans are to pursue the following developments in parallel: 1. Train and test the static handshape classifier with fluent signers 2. Implement a dynamic model to recognize signs with motions. I’m also interested in seeing how well the new model of the Kinect will work for such a system.