For our final project, Emily Danchik and I are collaborating on a song generation tool that uses TEDTalks as it’s source for vocals. The primary tools we are using are Python, NLTK and various python libraries, and Praat.
We’ve chosen to divide the work into two parts:
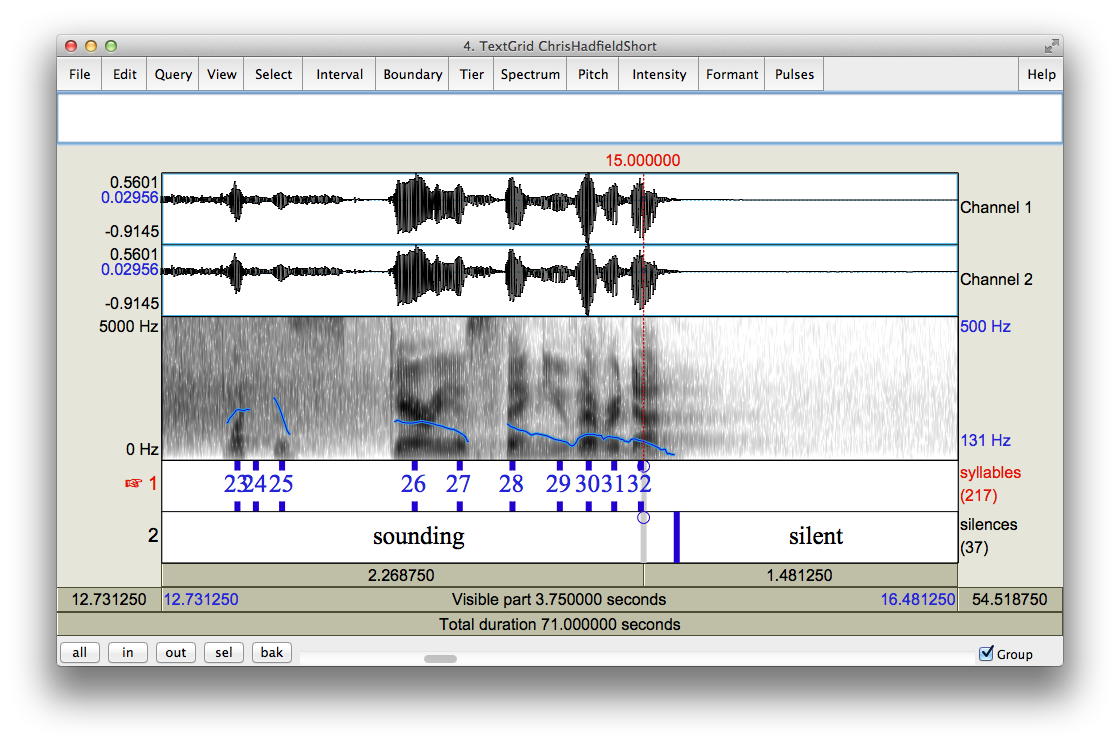
Emily is working on audio processing. In order to make the TED speakers seem like they’re rapping to a beat, we first need to know where the syllables are in each sentence. Unfortunately, accurate syllable detection is still an open research topic, so we are exploring ways to approximate boundaries between syllables.
While determining syllable boundaries is a challenge, it is possible to detect the center of a syllable with relative accuracy. We have used a script written for Praat, a speech analysis tool often used in linguistics research, to identify these spots.
So far, we have determined approximate syllable boundaries by finding the midpoint between syllables, and calling it a boundary. This seems to work relatively well, but could use some improvements: for silibants (like ‘ssss’) and fricatives (like ‘ffffff”), this method is not accurate.
We have been lucky to meet with Professor Alan Black in the CMU Language Technologies Institute, to determine ways of improving our process. As we move forward, we will document the changes here.
Once we have each syllable in isolation, we perform a stretch (or squash) by a given ratio so that each syllable lasts for exactly one beat of the rap song. We find this by determining the ratio between the length of the syllable and the beats per minute of the rap. To form a phrase, we simply string these syllables together over a beat.
Here are some of our initial tests:
I am working on the lyric generation. We’ve scraped 100 GB of TEDTalk videos and their corresponding transcripts (about 1100 TEDTalks). The transcript files contain what they’ve said between a given start time and end time, which is usually 5-15 words, for hundreds or thousands of time periods in each of the 2-36 minute videos. Using NLTK, we’re able to analyze each line of text for how many syllables the line is, as well as what it would rhyme with. We’ve created a series of functions that allow us to query for given terms in a line and lines that would rhyme with this line given syllable-count constraints. This combined with some ngram analysis of common TEDTalk phrases, a set of swear words, or other pointed queries allow us to have some creative control over what we want our TEDTalkers to say.
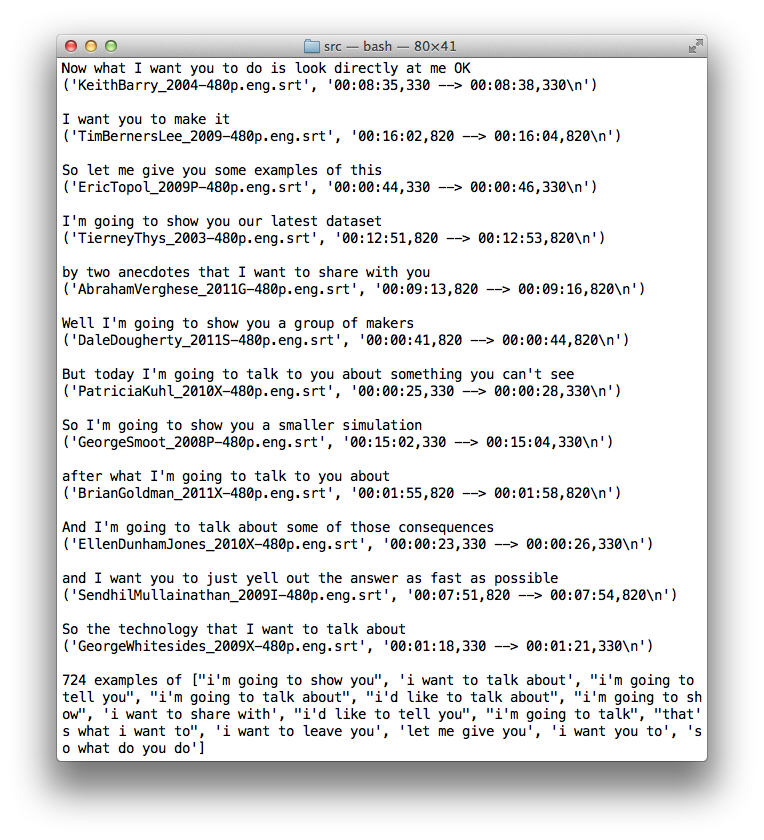
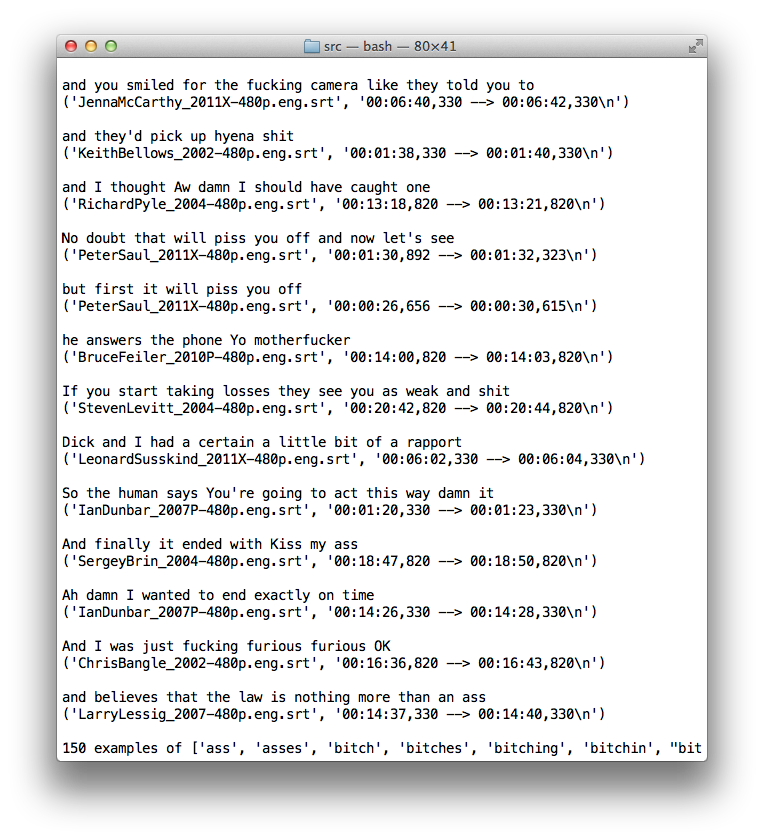
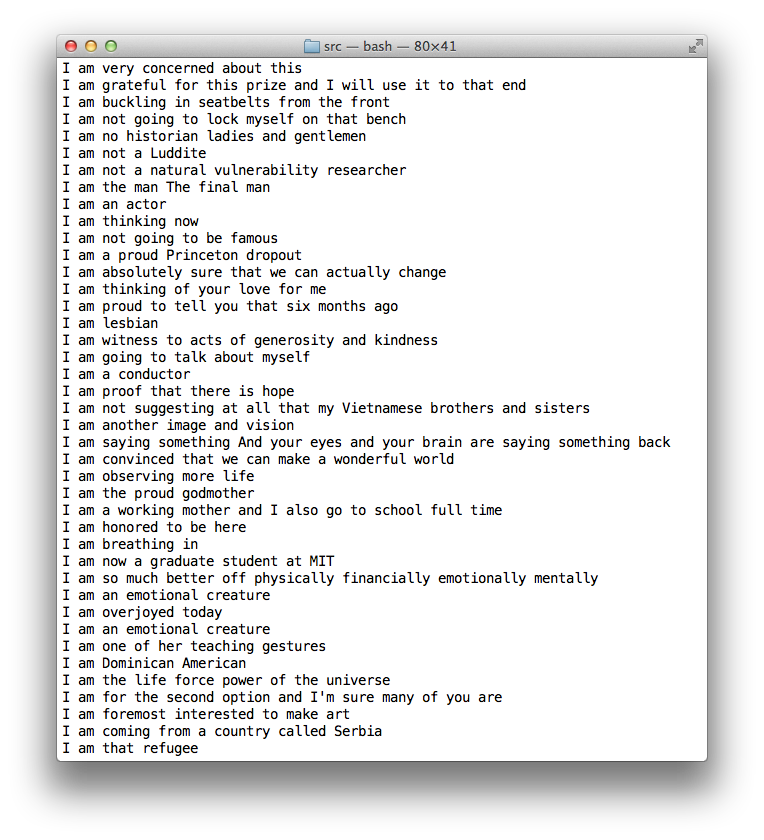
Using this idea, we will generate a chorus based on some set of constraints that will define what the song is about. We will then use the chorus as a seed for the verses to ensure some thematic thread is maintained, even if it’s minimal, and the song ends up being grammatically incorrect.
A sample chorus:
and my heart rate
and my heart rate
If you buy a two by four and it’s not straight
like smoking or vaccination
is that it’s a combination
and you work out if you make the pie rate
no one asked me for a donation
soap and water vaccination
like smoking or vaccination
The end product is expected to be a music video that jumpcuts between multiple TEDTalks, where the video is time-manipulated to match the augmented audio clips.
We’re using the TEDTalk series for multiple reasons. Some reasons include:
- We believed the single speaker, enunciated speech, and microphone-assisted audio would be helpful in audio processing.
- People know TED, or at least some of the source speakers.
- There’s also a lot to say by combining powerful people into a rap.
- It’s fun to poke fun at.