
Computationally generating raps out of TED talks.
About
TEDraps is a project by Andrew Sweet and Emily Danchik.
We have developed a system which allows for the creation of computationally-generated, human-assisted raps from TED talks. Sentences from a 100GB corpus of talks are analyzed for syllables and rhyme, and are paired with similar sentences. The database can also be queried for sentences with certain keywords, generating a rap with a consistent theme. After the sentences for the rap are chosen, we manually clip the video segments, then have the system squash or stretch them into the beat of the backing track.
Text generation
We scraped the TED website to generate a database of over 100GB of TED talk videos and transcripts. We chose to focus on TED talks because most of them have an annotated transcripts with approximate start and end points for each phrase spoken.
Once the phrases were in the database, we could query for phrases that included keywords. For example, here is the result of a query for swear words:
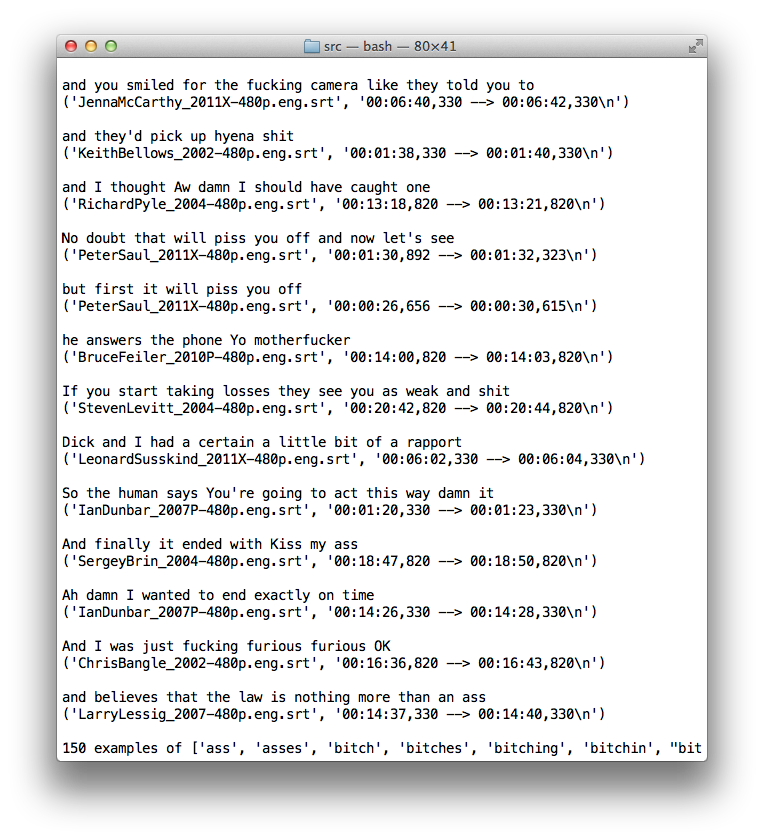
Here is another example of a query, instead looking for all phrases that start with “I”:
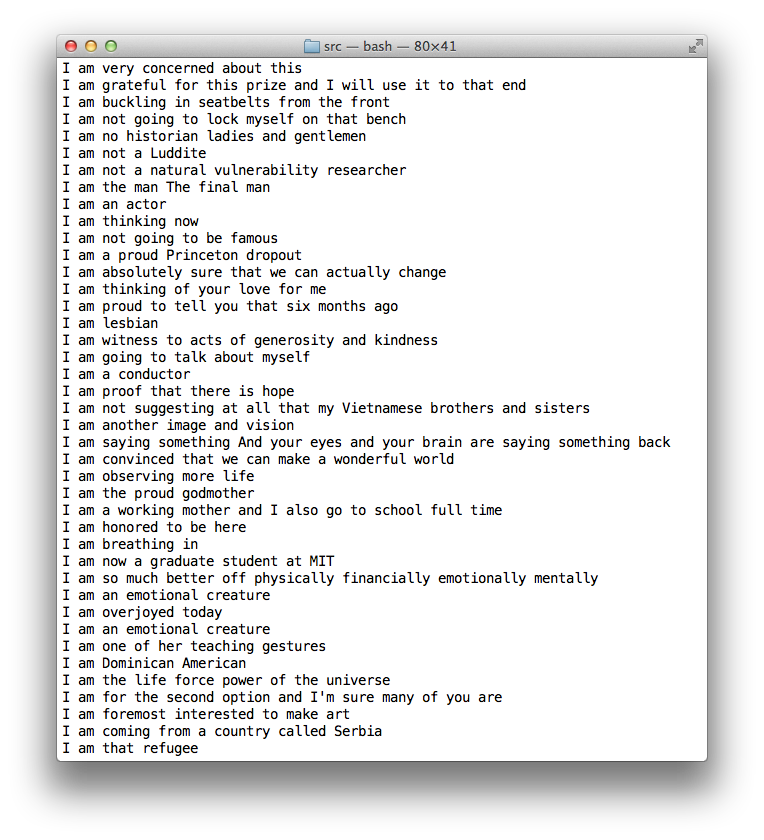
Using NLTK, we were able to analyze the corpus based on the number of syllables per phrase and the rhymability of phrases. For example, here is a result of several phrases that rhyme with “bet”:
to the budget
to addressing this segment
of the market
in order to pay back the debt
that the two parties never met
I was asked that I speak a little bit
Then the question is what do you get
And so this is one way to bet
in order to pay back the debt
Later, we modified the algorithm to match up phrases which rhymed and had a similar number of syllables, effectively generating verses for the rap. We then removed the sentences that we felt didn’t make the cut, and proceeded to the audio generation step.
Audio generation
Once we identified the phrases that would create the rap, we manually isolated the part of each video that represented each phrase. This had to be done by hand, because the TED timestamps were not absolutely accurate, and because computational linguistic research has yet to develop a completely accurate computational method for separating spoken word.
Once we had each phrase on its own, we applied an algorithm to squash or stretch the segment to the beats per minute of the backing track. For example, here is a segment from Canadian astronaut Chris Hadfield’s TED talk:
First, the original clip:
Second, the clip again, stretched slightly to fit the backing track we wanted:
Finally, we placed the phrase on top of the backing track:
We did not need to perform additional editing for the speech track, because people tend to speak in a rhythmic pattern on their own. By adding ~15 rhyming couplets together over the backing track, we ended up with a believable rap.