I chose EcstasyData.org as my large image database which provided data for around 4200 ecstasy pills and other recreational drugs, 3969 of which (at the time I scraped the website) had images associated with each entry.
After scraping all the images along with relevant metadata, such as name, active components, size and mass, I ran ofxTSNE on several modifications of the image set.
First I ran it on the raw images scaled down to a standard size, which essentially grouped all of the pressed pills together, separated by color, all the baggies together separated by background color, and all of the tubular pills together, separated by whether they were horizontal or vertical.

On my second iteration, I turned everything into grayscale before processing it because I really didn’t care too much about color. This gave me slightly better results: pills with the same design regardless of color were grouped together.

On my last iteration, I turned everything into grayscale and then cropped out the background by assuming a circular shape, equalized the histogram and filled the background with black. Results are worse!!! I looks like the loss of information in terms of shape outweighs the consistency in background.

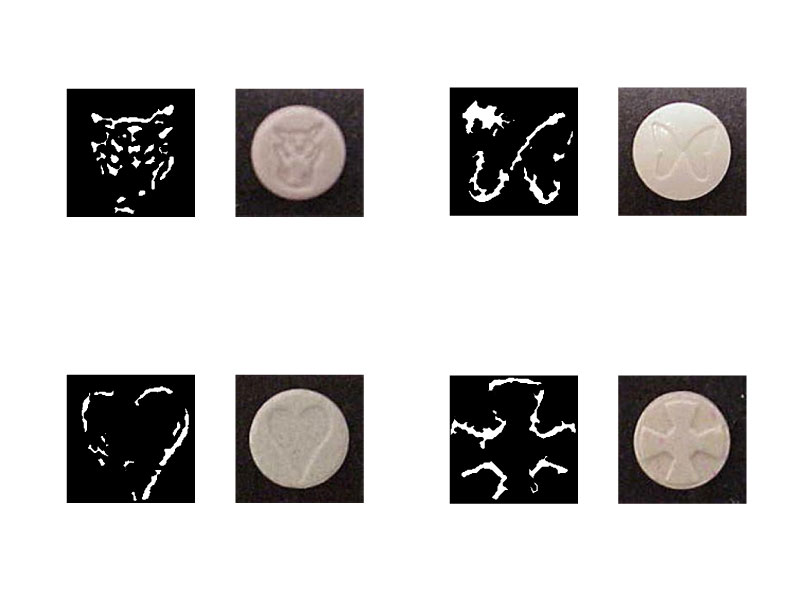
I decided that I wanted to extract the logos pressed into these pills and convert them into some sort of font collection (not quite unlike FontAwesome) or maybe an emoji set.
This turned out to be quite the challenge.
The image set, although visually consistent, had a lot of challenges in terms of image processing. The pills had enough variation in size, background color, lighting direction, lighting intensity, shape and physical contour, all of which made extracting icons extremely difficult. Embossed icons edges tended to be a very light vertical or a very dark vertical edge or a slightly light or slightly darker horizontal edge. Extracting the highlights and shadows was not too hard: after applying a median filter to remove noise, then doing a naive circle crop, and then slapping on a histogram equalization and curve on each image, I could isolate all the vertical edges and sometimes the horizontal edges.


From there I binarized the image using a threshold I found experimentally that worked on most of the images, applied a hole filling algorithm and found made Matlab find the coordinates of the black/white boundary for me. The results turned out alright. There were a lot of okay results and many more awful results