
Nara's Project 1: The World According to Google Suggest
The Idea
The inspiration for this project came when I saw this blog post a couple of weekends ago, wherein the author typed “why is” followed by different country names to see what Google Suggest comes up with, resulting in some interesting stereotyped perceptions of these countries. I opened up Google and tried a few searches of my own (I’m Dutch, so I started off with “why is the Netherlands”) and discovered that unlike the blog post had suggested, not all countries came up with stereotype-like phrases; many of them were legitimate questions. So, instead, I tried a few queries like “why are Americans” and “why are the Dutch” and found that when phrased that way, focusing on the people rather than the countries, one was much more likely to see stereotypes and perceptions rather than real questions.
I quickly realized that it shouldn’t be too difficult to write a program that queries Google for searches in the form “why are [people derivation]” for different countries and see how we stereotype and perceive each other. When I presented this idea in class last week, my group members suggested that in addition to querying Google.com, I should also query other geographic localizations of Google such as Google.co.uk.
The Data
One of the trickiest parts of this project was figuring out where/how to get the data, as it seems that Google fairly recently changed its search API from the old SOAP-based model to something new, and most of the documentation and how-to’s on the web focus on the old API. I also couldn’t figure out where Google Suggest fits into the search API and finally decided to give up on the “official” API altogether. I finally discovered that one could obtain the Google Suggest results in XML format using the URL http://www.google.com/complete/search?output=toolbar&q= followed by a query string. (This URL works for all geographic localizations as well; simply replace “google.com” with “google.co.uk” or what have you.)
All my data is obtained using that URL, saving the XML file locally and referencing the stored XML file unless I specifically tell it to scrape for new data. I did this because this is not an official API, unlike Google’s real APIs which require API keys, so I wasn’t sure if they would get upset if I am repeatedly scraping this site. The results don’t seem to update all too frequently anyway.
Input
The program takes as input a CSV file that has a list of countries and the main derivation for the people of each of those countries. For example, “United States,American” and “Netherlands,Dutch”. These are later used to construct the query strings used for scraping Google Suggest.
Another idea that I had was to color-code the results based on whether each adjective or phrase has a positive, negative, or neutral connotation. Patrick told me that such a list does exist somewhere on the web, but I did not manage to find it. So, it currently uses an approach based on manual intervention. The program also takes as input a CSV file with a list of adjectives followed by the word “positive”, “negative”, or “neutral”. It reads these into a hash table, and each adjective gets associated with a random tint or shade of the color I picked for each of the words (green for positive, red for negative, blue for neutral). When the program is set to scrape for new data, it writes any newly encountered adjectives/phrases to the CSV file, followed by the word “unknown”. I can then go into the CSV file and change any of those unknowns to their proper connotation. This approach currently works quite well because it currently has a listing of some 100 phrases, and each time it scrapes for more data it finds fewer than 5 new phrases on average. Of course, this manual intervention isn’t a long-term solution and ideally a database could be found somewhere that can be scraped for these connotations.
Filters
I did purposely filter out some of the phrases that are returned by the searches. For example, phrases of the style “[why are the dutch] called the dutch” were common, but did not contribute to my goal of showing stereotypes and perceptions of people; these are the more legitimate questions that I’m trying to avoid. Unfortunately there wasn’t really a good way to do this other than providing a manually-edited list of certain keywords associated with phrases and phrase patterns I deliberately want to exclude.
The Results
You can see the program ‘live’ here. I say ‘live’ because as noted above it is referencing stored XML files and not querying Google in real time. However, it is ‘live’ in the sense that you can freely interact with it.
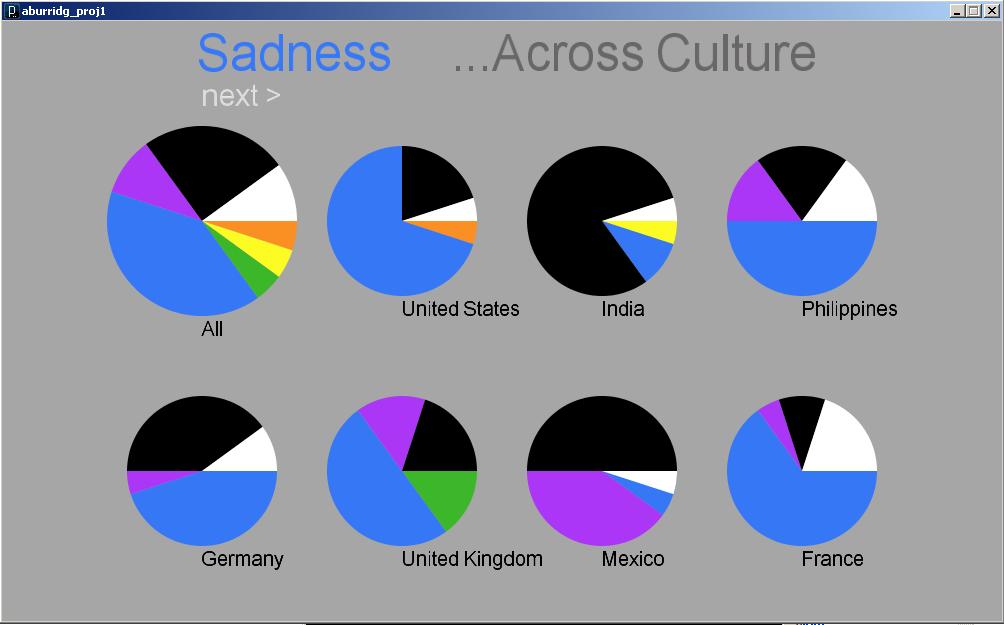
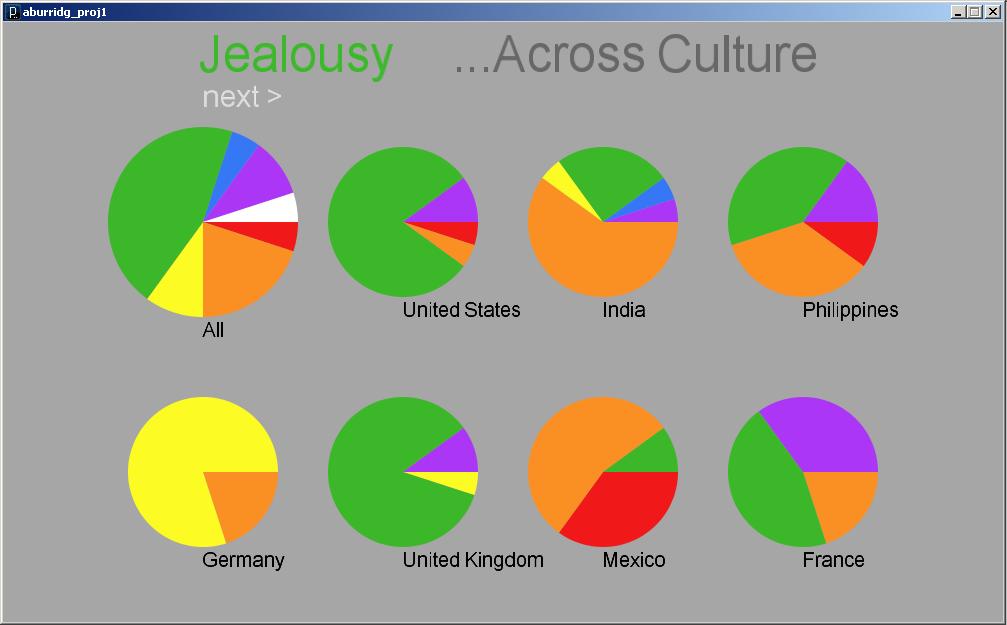
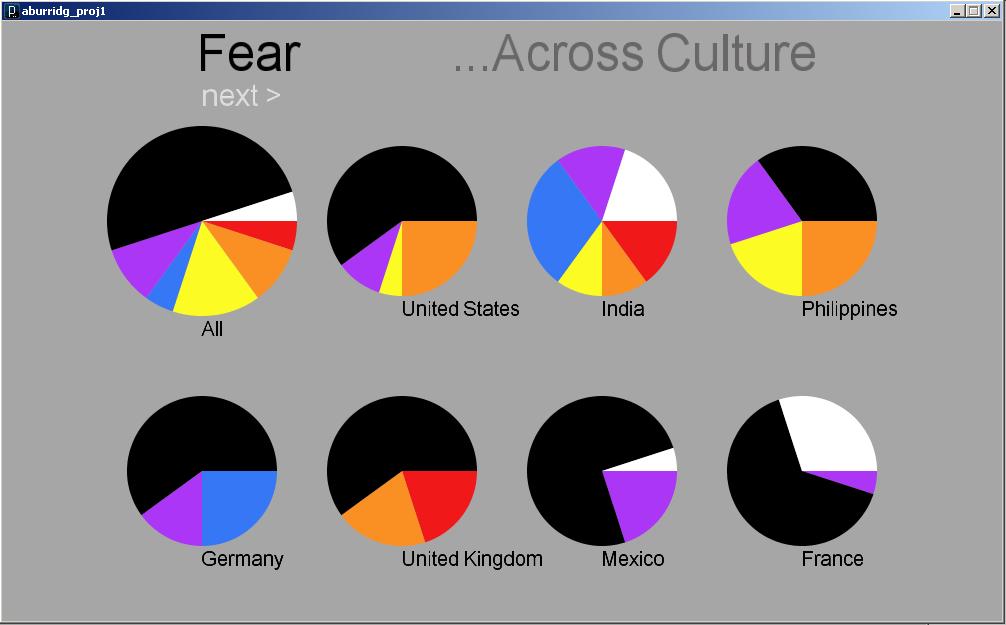
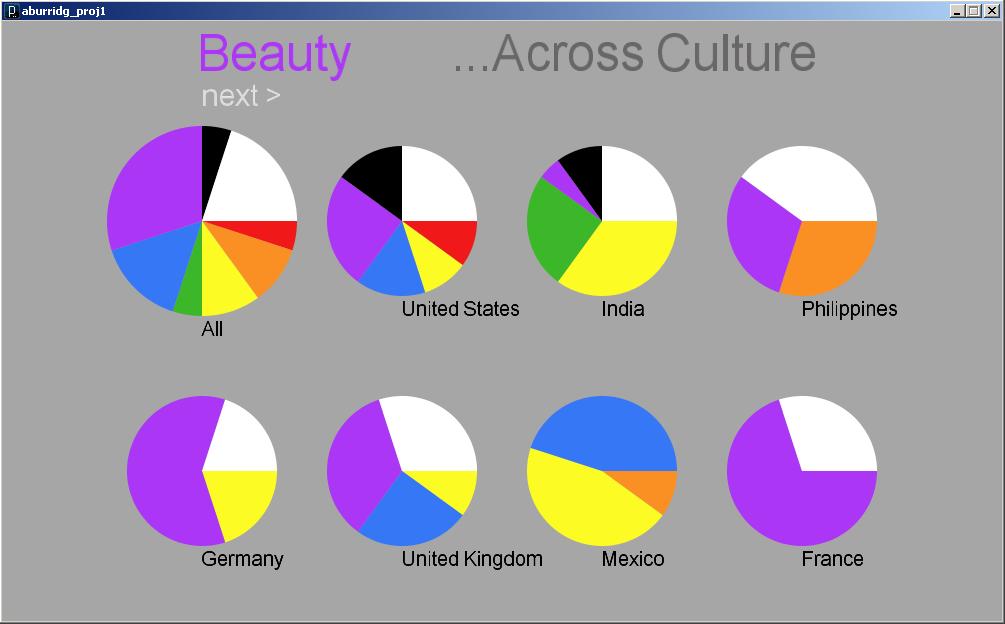
The program currently displays the results for 24 different countries and 6 different versions of Google. I tried other versions of Google but it seems to only work for the geographic localizations of English-speaking countries; other localizations tended to only yield results for fewer than 10 different countries.
Not all countries came up with a lot of different words and phrases associated with them. I actually originally started out with a list of about 30 countries, and I had to take out a few that just weren’t yielding any results. There are still a few left that do not have many, but I decided to keep them because I did not want to create this false perception that because all the countries shown have a wide range of results, any country queried will have that wide a range. My list, I feel, is much more honest and shows that people simply aren’t doing as many queries on Danish people as they are about Americans. I also felt compelled to include at least one country for each continent, which sometimes was difficult, especially in the case of Africa and the Middle East. So, one might wonder why I chose to keep some of the countries that do not have very interesting results, but there actually was good reasoning behind my final list of countries.
The Visualization & Interface
The interface is pretty barebones and the visualization is readable but not terribly beautiful or compelling. I actually started out intending to use the treemap for comparisons available on ManyEyes, but I tried to implement the algorithm in the paper they reference and didn’t get very far. (I had little time to work with and I have no experience implementing an algorithm described in a research paper.) So, I opted for this much simpler approach, inspired somewhat by the PersonalDNA visualization of personal qualities like a DNA strip with longer widths for qualities that are more dominant. It is basically like a stacked bar graph.
As far as interactive features go, the user can:
- Hover over any part of the “DNA strip” to uncover words that do not fit (ie. the label is wider than the part of the strip).
- Click on a word or phrase and see all the countries that have that trait, ranked by the percentage of their search results that that phrase takes up.
- Click on one of the tabs on the bottom to examine how the attributes change when different geographic localizations of Google are queried.
- Click on the name of a country to dim out the other countries. This setting is retained when switching tabs at the bottom, making it easier to examine the changes in a specific country across the different geographic localizations of Google.
The Future
Here’s a few things I would’ve liked to implement had I had more time:
- Including something about the number of queries for each query string; possibly allowing the user to rank the occurrences of a phrase by number of queries for that phrase instead of by percentage of that country’s queries.
- An ability to filter the list of countries in various ways, such as by continent.
- Relating it to a world map, especially with the colors. For example, a simple SVG map of the world could be color-coded according to the most dominant color for each country. The results could be interesting, on a country as well as a continent level.
- Having data moving and shifting using tweens, rather than just displaying the data in one frame and then the changed data in the next frame.
- A prettier interface with more visual hierarchy.
The Conclusion
All in all, I’m not dissatisfied with this project, although I view it more as a good start to a project rather than a finished piece. It has a lot of opportunities for further development, and I hope I do get around to expanding and refining it more someday, but in this case I just simply did not have the time. I was out of town this past weekend for grad school interviews, and I had 2 other projects due this week as well, one on Tuesday and another also on Wednesday. It’s been a hell of a week with very little sleep, so even though I recognize the weaknesses of this project, I admittedly am quite happy and proud of myself for getting something up that works at all.
The zip file with the applet and the source code can be found here.

")
")






































 solbisker_project1_moving_v0point1 – PNG
solbisker_project1_moving_v0point1 – PNG
