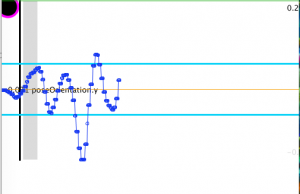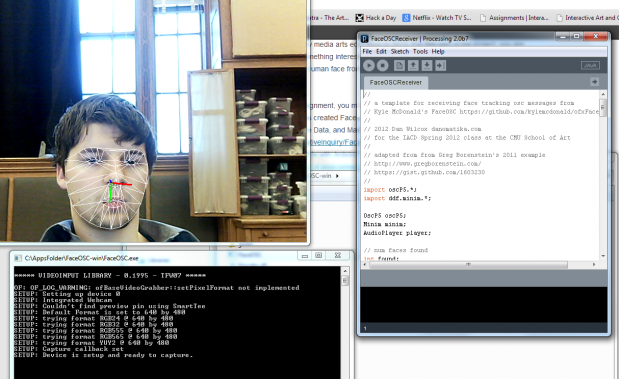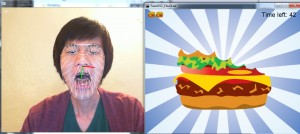
Hamburger eating contest using FaceOsc and Processing. It tracks the user’s mouth height until it reaches a threshold. You’ll take a bite out of the hamburger when you close your mouth again. The image sequence is stored in an array and is called according to the counter.
Future work would be to implement head position and show the bite with the corresponding location on the hamburger through image masking.
Github link: https://github.com/BlueSpiritbox/p1_faceosc-hamburgers
import oscP5.*;
OscP5 oscP5;
//our FaceOSC tracked face dat
Face face = new Face();
PFont f;
PImage bg, img, icon, startBtn;
String imgString;
int imgIndex = 0;
int imgLast = 8;
int burgerNumber = 3; //number of hamburgers
float bgRotate = 0;
int startTime;
int currentTime;
int maxTime = 60; //time limit
String counter;
boolean playing = false;
boolean eat = false;
boolean readyToEat = false;
boolean finished = false;
void setup () {
size(600, 480);
frameRate(60);
imgString = "hamburger-"+str(imgIndex)+".png";
img = loadImage(imgString);
bg = loadImage("bg.png");
icon = loadImage("icon.png");
startBtn = loadImage("start-button.png");
f = createFont("Arial", 24, true);
currentTime = maxTime;
oscP5 = new OscP5(this, 8338);
}
void draw() {
//background + rotation
pushMatrix();
translate(width/2, height/2);
rotate(bgRotate*TWO_PI/360);
bgRotate += 0.5;
image(bg, -bg.width/2, -bg.height/2);
popMatrix();
img.resize(400, 400); //resizes image
image(img, (width/2)-(img.width/2), (height/2)-(img.height/2)); //puts hamburger image in the center
//draw hamburger icons
for ( int i=0; i 0) {
if ( face.mouthHeight > 3 && !readyToEat) {
println("Mouth Open");
readyToEat = true;
}
if ( face.mouthHeight < 2 && readyToEat) {
readyToEat = false;
eatBurger();
}
}
}
}
void eatBurger() {
imgIndex += 1; //next hamburger image
if ( imgIndex == imgLast ) {
checkBurgers(); //checks how many burgers are leftd
}
imgString = "hamburger-"+str(imgIndex)+".png";
img = loadImage(imgString);
println("Nom nom nom!");
}
void checkBurgers() {
if ( burgerNumber != 1) { //if 1 or more burgers left
imgIndex = 0; //reset to full burger
burgerNumber--; //minus 1 burger
}
else {
imgIndex = imgLast; //blank image
burgerNumber--; //no more burgers left
finished = true;
}
}
void startButton() {
cursor(HAND);
fill(0, 170);
rect(0, 0, width, height);
image(startBtn, (width/2)-(startBtn.width/2), (height/2)-(startBtn.height/2));
if ( mousePressed == true ) {
startTime = millis();
cursor(ARROW);
playing = true;
}
}
void score() {
fill(0);
textFont(f, 64);
textAlign(CENTER);
text("Your score: "+currentTime+"!!", width/2, height/2+12);
}
void keyPressed() { //hotkeys for testing purposes
if ( playing ) {
switch (key) { //press 'a' to take a bite
case 'a':
if ( burgerNumber != 0 ) {
eatBurger();
}
break;
default:
break;
}
}
}
// OSC CALLBACK FUNCTIONS
void oscEvent(OscMessage m) {
face.parseOSC(m);
}