





What is my project? – An interactive children’s book designed for the iPad and accessed through Chrome (using Javascript/HTML)
Why did I choose this project?
– Illustration
– Pop-up Books
What is the point of my project? – Incorporate the reader into the story by allowing them to unfold it themselves. I want interaction on each page to draw in more connection from the reader than just flipping through a picture book would.
Why do I have so little done?
– I took longer attempting responsiveness for multiple device sizes that I’d like to admit
– I’m not super speedy at illustrating all the images and animations
Concerns for the rest of work I have:
– Overall experience won’t be good enough
–> I don’t have time to compose and record music
–> It might be pretty easy just to tilt and shake to push through the story and never read it




< <<< eh >>>>
– using phone and comp like roll-it isn’t as “pop-book-esque” as my goal is
– tilt too sensitive on mobile device
– calibration to starting position for what is considered “level”
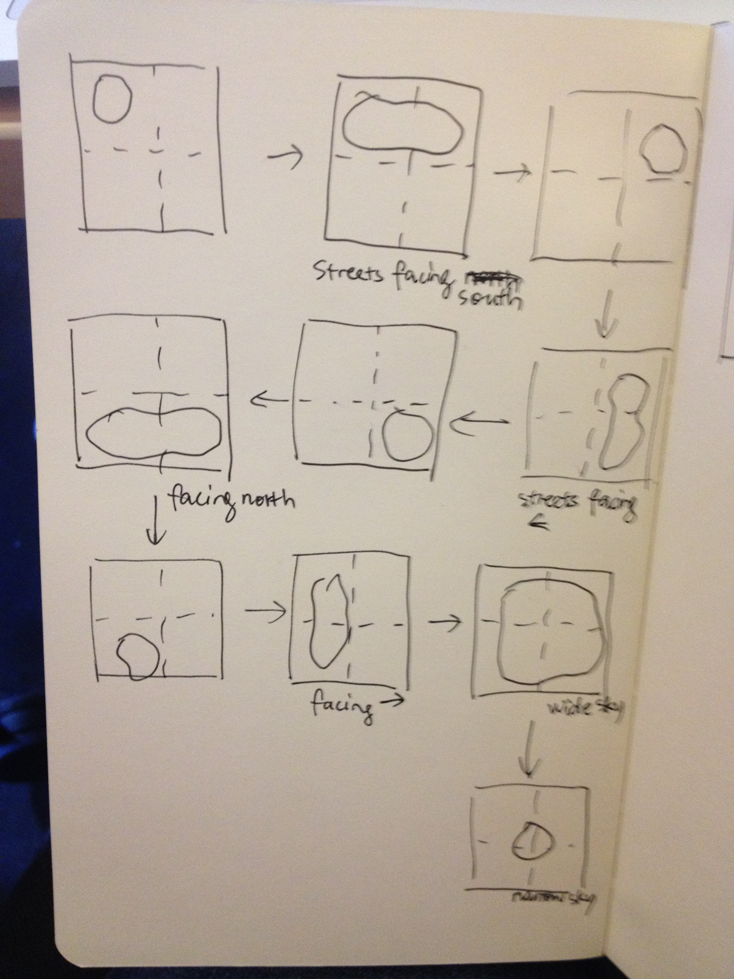
Generating a time-lapse of sky contours transitioning into shapes from google street views.
http://maps.googleapis.com/maps/api/streetview?size=1200×1200&location=40.720032,-73.988354&fov=180&heading=0&pitch=90&sensor=false

Identifying contour of sky (using OfxCV color contour recognition)->

A storyboard of a simple contour animation
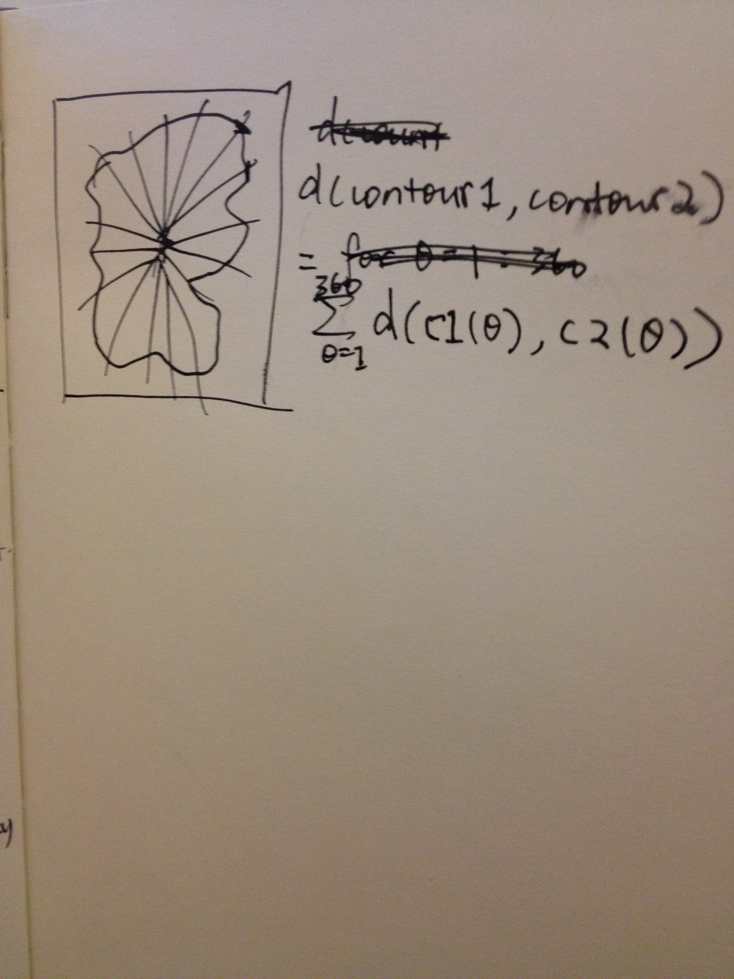
How to compute difference between contours:
A few views of sky in Hong Kong:




Questions:
How to scrape sky views of the whole world?
Mapreduce?
Better nearest contour searching algorithm?
Earlier experiments:


https://vimeo.com/93911554
Code @: GitHub
Overview
I am working with CMU’s own Richard Pell and his Center for Postnatural History to create an interactive exhibit which helps visitors understand how a set of model organisms create the gene pool for all genetically modified organisms.
What is the Center for Postnatural History you ask? Professor Pell says it best…
The Center for Postnatural History.

But wait, what about the model organisms? What are those?
Model Organisms are the building blocks for every genetically modified organism you can think of. They have a gene pool which is thought to cover every possible combination of attributes. If you want to create a goat with spider silk in its milk, or a cactus that glows, you are likely going to be working with combining genes from one or more of these model organisms.
What They Already had:
A database
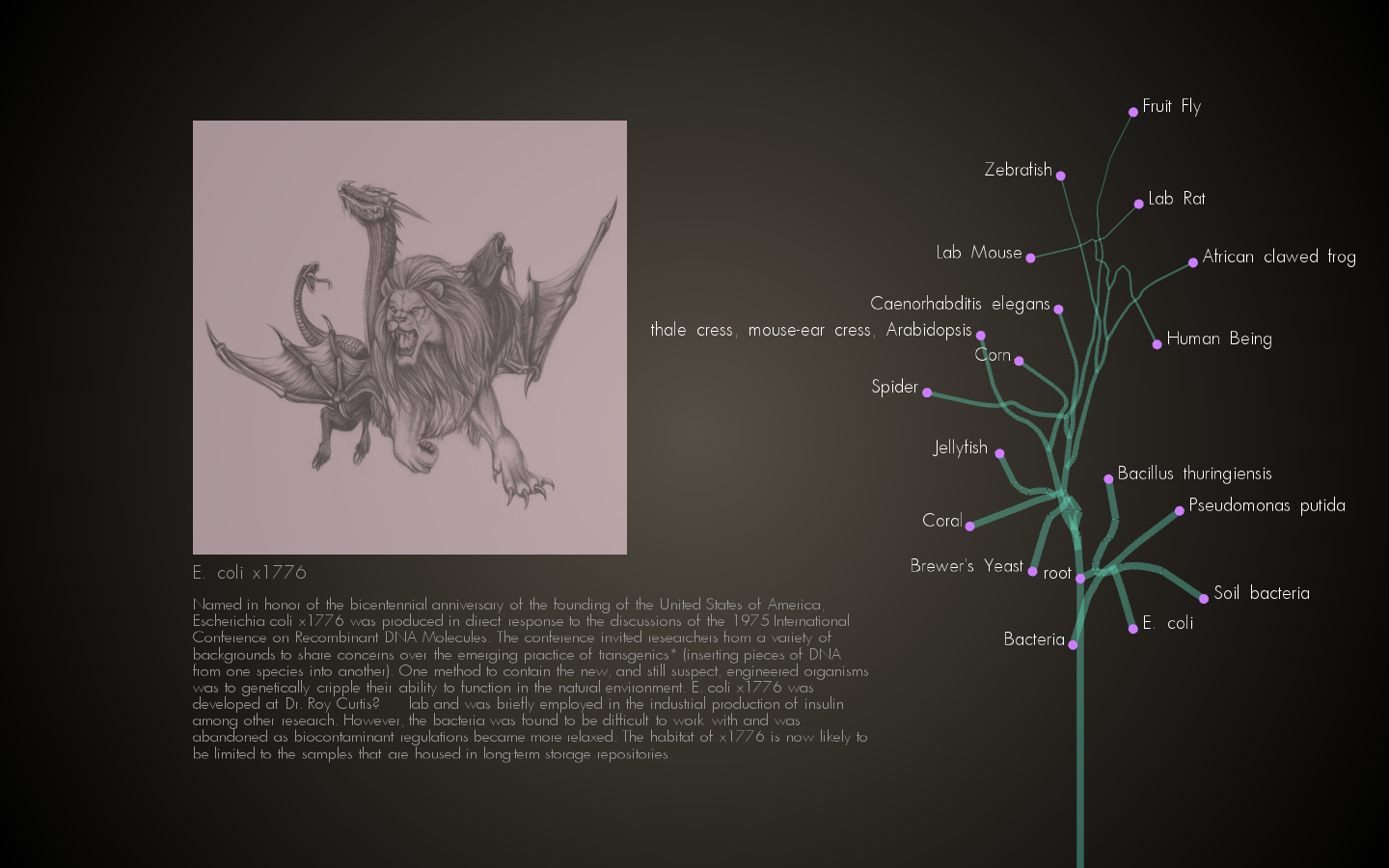
The Center for Postnatural History maintains a database of genetically modified organisms. This is a manually maintained database
A processing sketch.
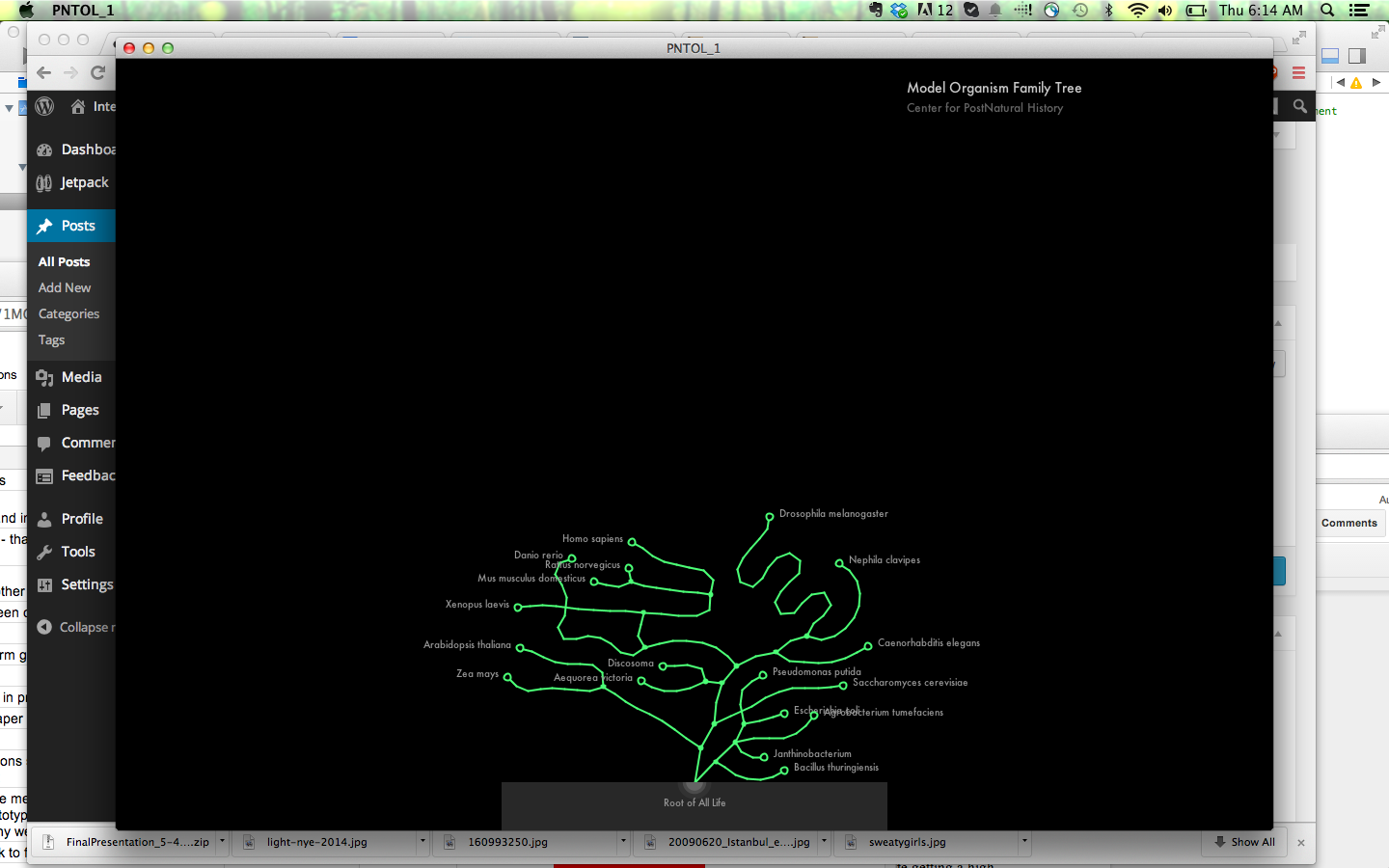
Wrapping my head around the problem
Getting the model organism tree to display – playing around:
Developing the App:
First Tree reading from database:

Creating a tree using verlet springs from Memo Akten’s ofPhysics addon.
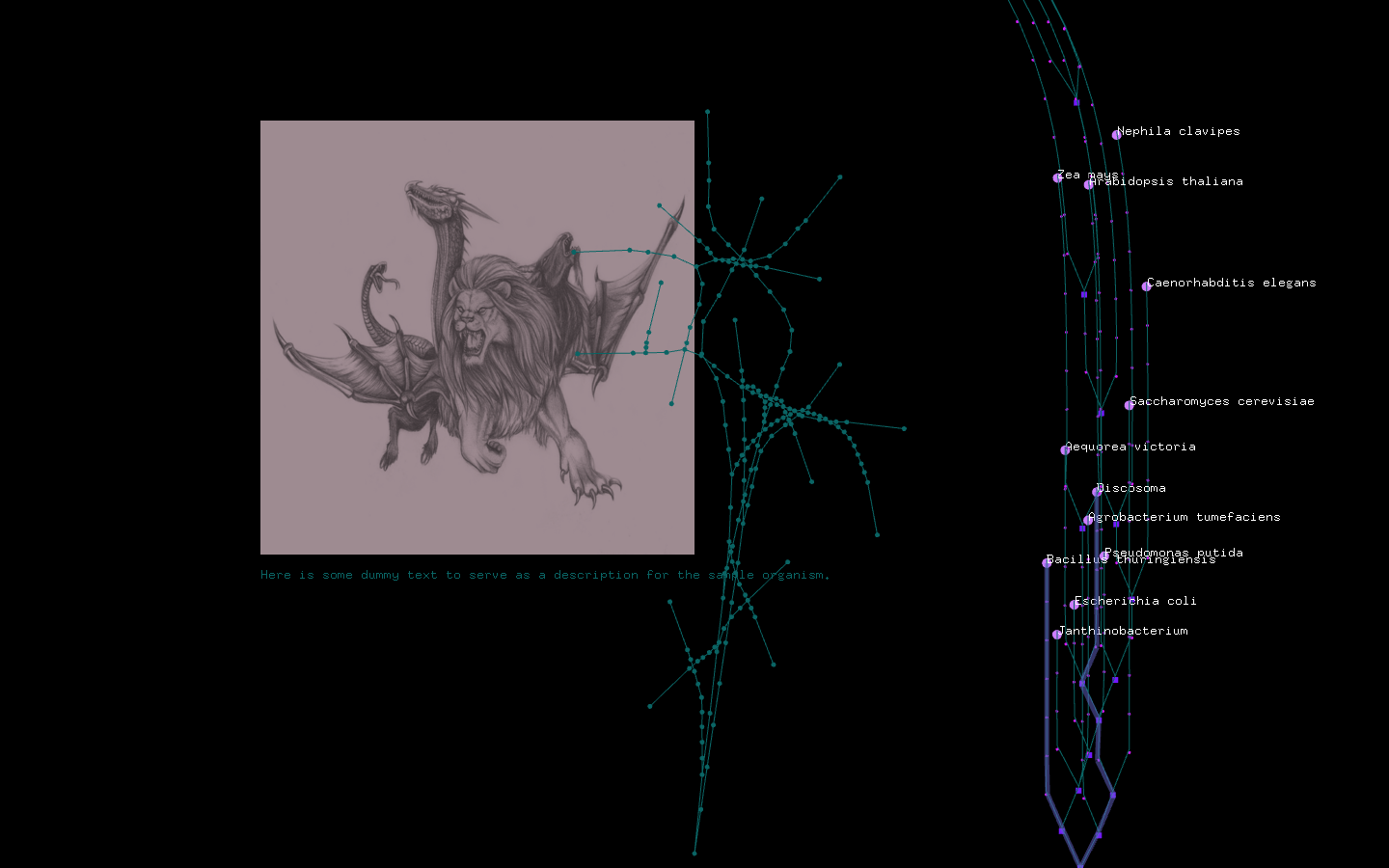

Linking UI to read database information and visual improvements on tree. Nodes now draggable.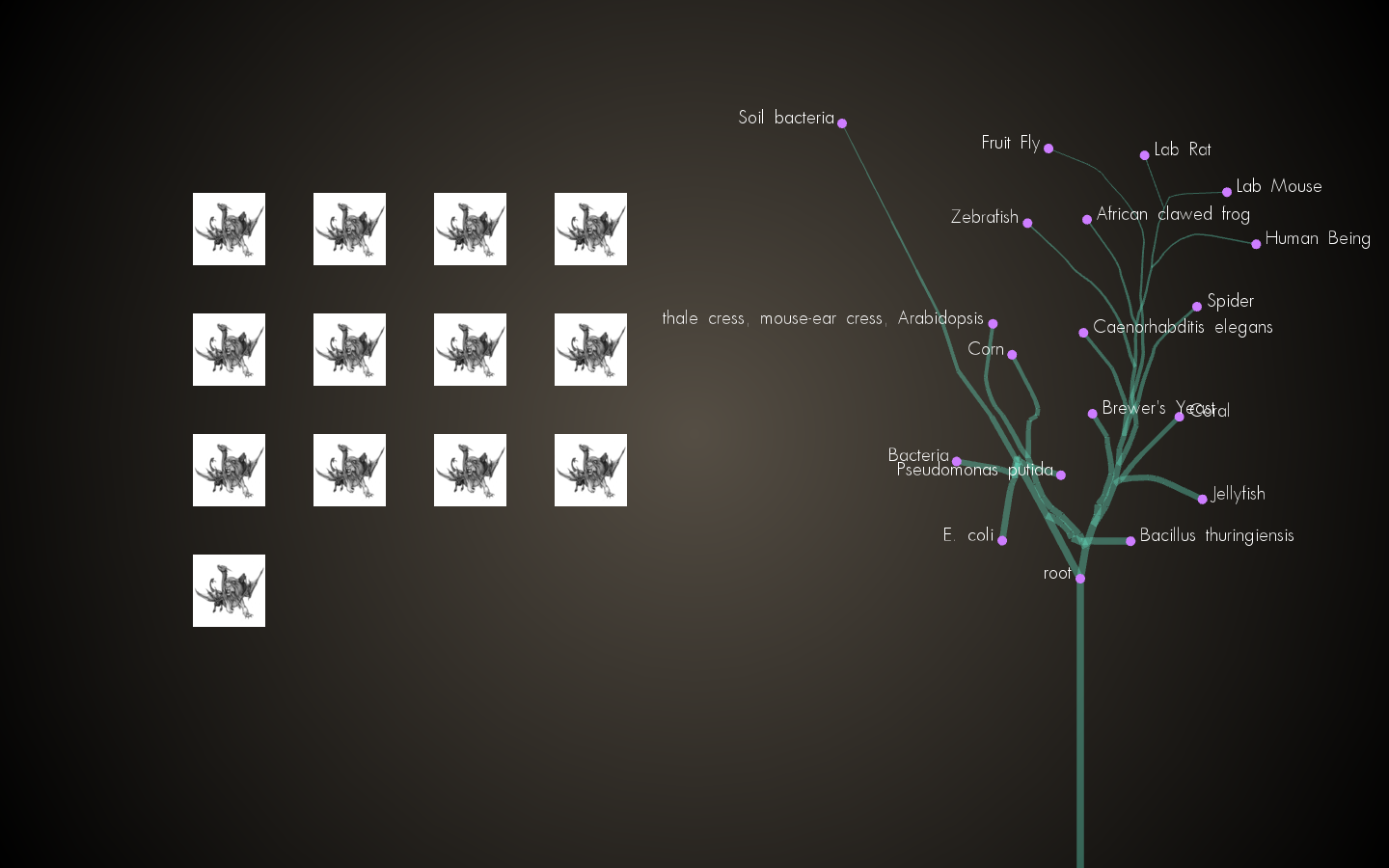
Next Steps
Tree Improvements – Better Branch Width, More “tree-like” spread, intelligent initial placement of leaves, Organism Path Highlighting.
Ambient Background – Smooth background with some sort of cellular movement instead of the plain gradient. Possibly lay with depth of field (though I’ll have to learn some basic shader stuff, so time could be an issue)
Get pictures out from behind the password wall – Right now the database API doesn’t contain links to the photos, they only exist as part of the wordpress site. How to get these photos given an organism ID?
Compile on iPad – Compile OF for iPad so it can live on that device in the physical Center for Postnatural History
For our final project, Emily Danchik and I are collaborating on a song generation tool that uses TEDTalks as it’s source for vocals. The primary tools we are using are Python, NLTK and various python libraries, and Praat.
We’ve chosen to divide the work into two parts:
Emily is working on audio processing. In order to make the TED speakers seem like they’re rapping to a beat, we first need to know where the syllables are in each sentence. Unfortunately, accurate syllable detection is still an open research topic, so we are exploring ways to approximate boundaries between syllables.
While determining syllable boundaries is a challenge, it is possible to detect the center of a syllable with relative accuracy. We have used a script written for Praat, a speech analysis tool often used in linguistics research, to identify these spots.
So far, we have determined approximate syllable boundaries by finding the midpoint between syllables, and calling it a boundary. This seems to work relatively well, but could use some improvements: for silibants (like ‘ssss’) and fricatives (like ‘ffffff”), this method is not accurate.
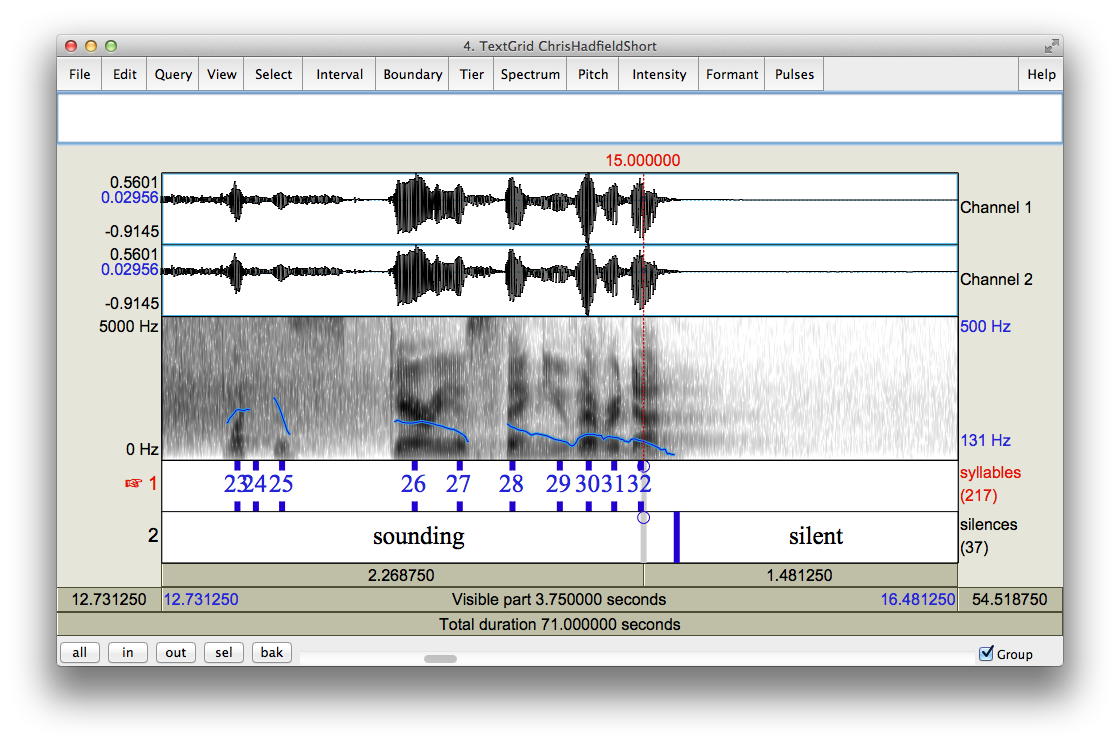
We have been lucky to meet with Professor Alan Black in the CMU Language Technologies Institute, to determine ways of improving our process. As we move forward, we will document the changes here.
Once we have each syllable in isolation, we perform a stretch (or squash) by a given ratio so that each syllable lasts for exactly one beat of the rap song. We find this by determining the ratio between the length of the syllable and the beats per minute of the rap. To form a phrase, we simply string these syllables together over a beat.
Here are some of our initial tests:
I am working on the lyric generation. We’ve scraped 100 GB of TEDTalk videos and their corresponding transcripts (about 1100 TEDTalks). The transcript files contain what they’ve said between a given start time and end time, which is usually 5-15 words, for hundreds or thousands of time periods in each of the 2-36 minute videos. Using NLTK, we’re able to analyze each line of text for how many syllables the line is, as well as what it would rhyme with. We’ve created a series of functions that allow us to query for given terms in a line and lines that would rhyme with this line given syllable-count constraints. This combined with some ngram analysis of common TEDTalk phrases, a set of swear words, or other pointed queries allow us to have some creative control over what we want our TEDTalkers to say.
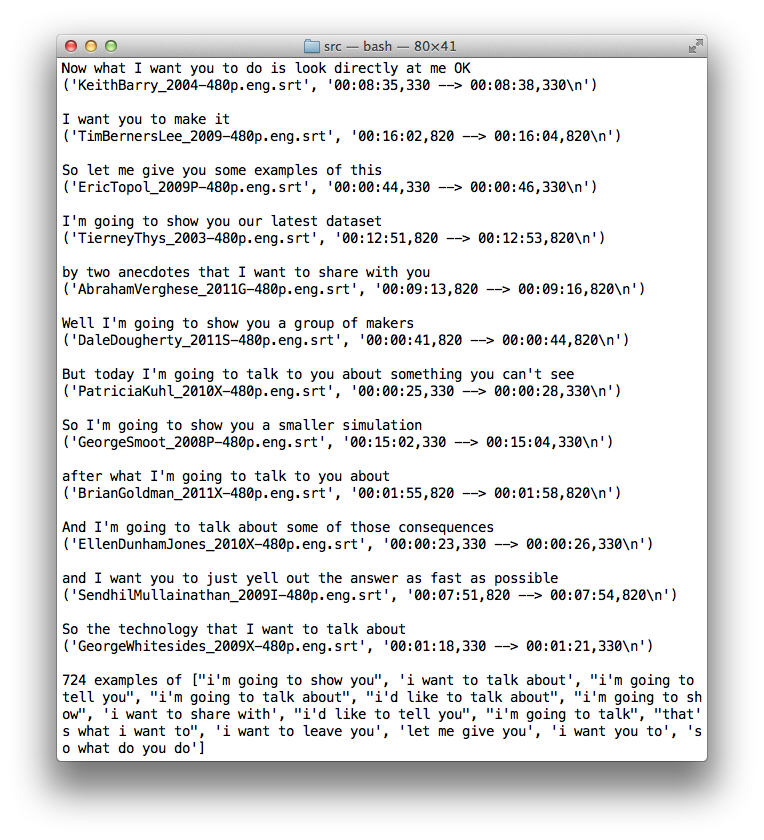
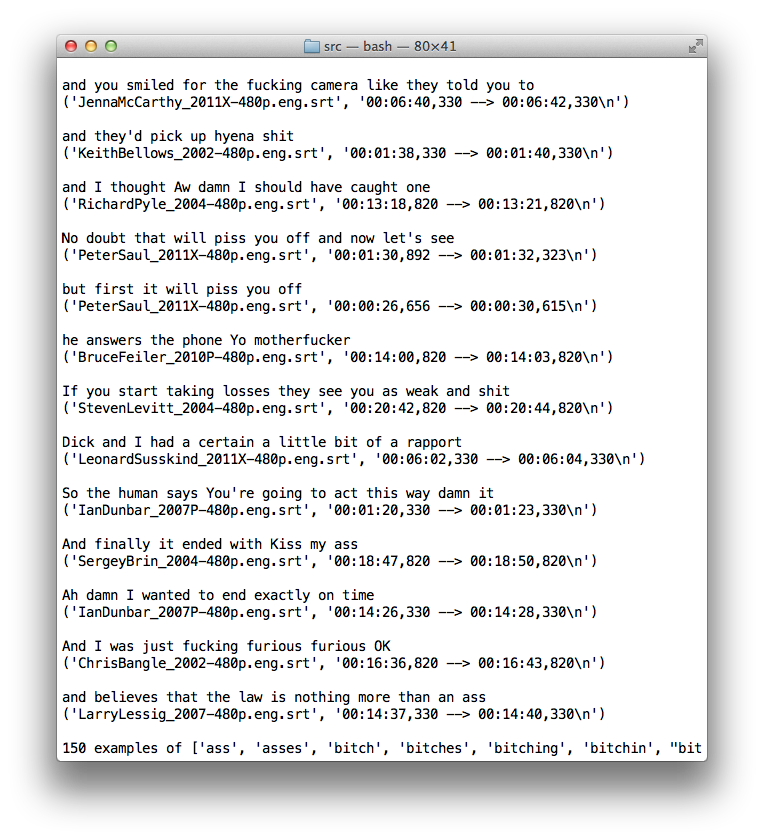
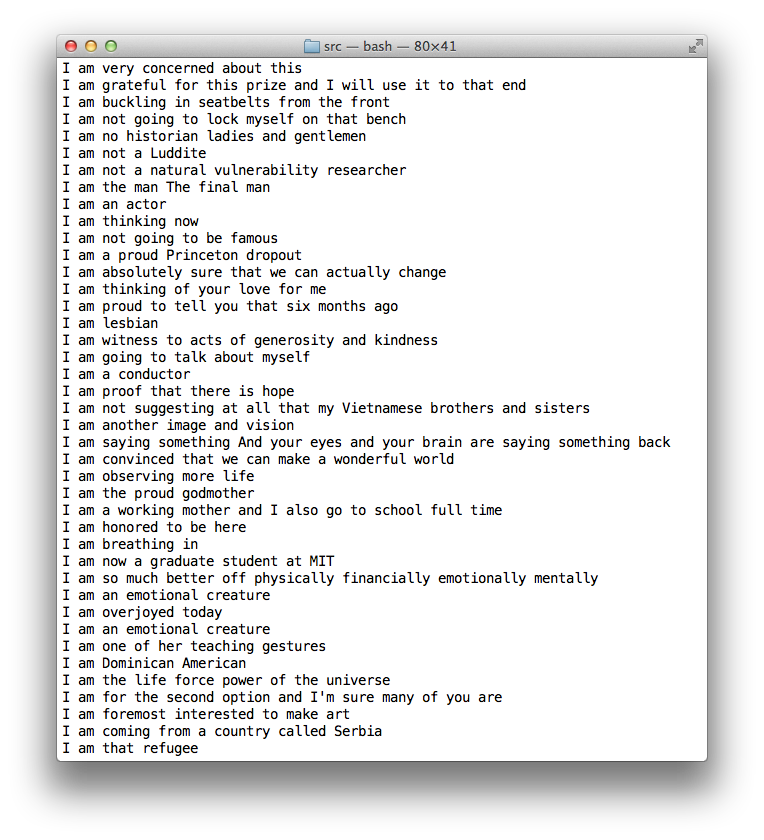
Using this idea, we will generate a chorus based on some set of constraints that will define what the song is about. We will then use the chorus as a seed for the verses to ensure some thematic thread is maintained, even if it’s minimal, and the song ends up being grammatically incorrect.
A sample chorus:
and my heart rate
and my heart rate
If you buy a two by four and it’s not straight
like smoking or vaccination
is that it’s a combination
and you work out if you make the pie rate
no one asked me for a donation
soap and water vaccination
like smoking or vaccination
The end product is expected to be a music video that jumpcuts between multiple TEDTalks, where the video is time-manipulated to match the augmented audio clips.
We’re using the TEDTalk series for multiple reasons. Some reasons include: