I originally had .gifs taken from blingee.com, which would’ve proven to be a COMPLETELY hilarious gif decorator visualization of some sort, but I don’t really give a shit about that anymore.
I recently found out a good friend of mine passed away. We only knew each other through the internet, and our friendship was primarily conducted over mediums like forums, IRC and skype chats. A few years ago, he archived 13 iterations of the skype group we were in, totaling to thousands of messages between more than 20 different users (who ranged from normal members to bots to Chinese autoglass salesmen). As part of a larger archival project of his work, I’m going to clean up the data he saved and create an interactive visualization of the lifetime of the group.
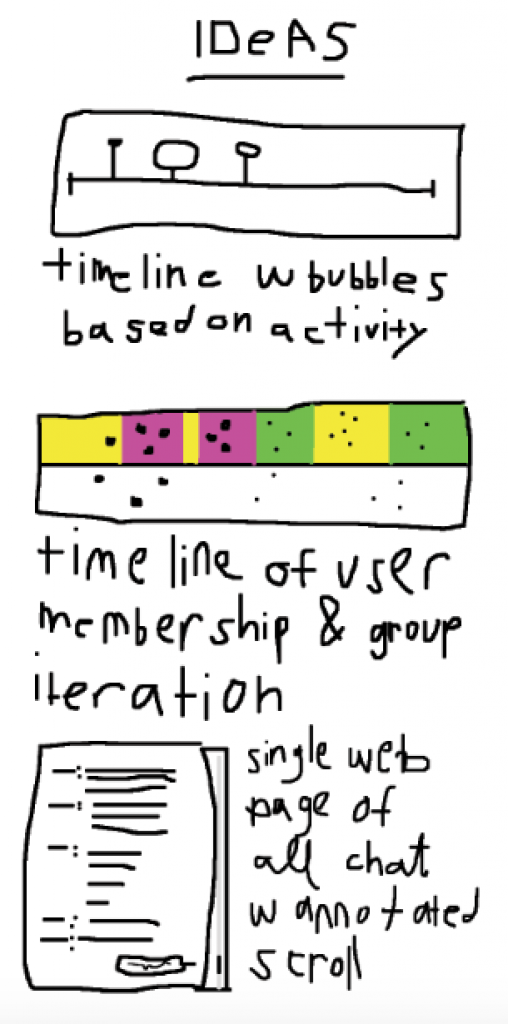
Internet relationships are weird. Your social interactions create concrete artifacts that you can collect and save. If you really wanted to, you could literally quantify your friendship with someone online through the exchange of written word and images (and, in the age of Web 2.0, voice and video call lengths). Everything is timestamped and prepackaged for you, if I wanted to I could literally recreate our conversations, with the exact same timing that was used in the original chat.
I guess it’s kind of serendipitous that we bonded over a comic that was about internet friends playing a video game together, and that the only form of dialog in the comic is the medium of the chatlog. Chat archival has always been popular, with funny/memorable snippets from IRC chats archived by sites like bash.org.
There’s a large dialogue regarding data collection by massive corporations, but I don’t see nearly as big of discussion about peer collection. Our digital bodies are increasingly becoming just another facet of our physical bodies, with mediums like Facebook and Instagram simply extending our irl relationships. But there will always be instances where that relationship is flipped–where our physical bodies become extensions of our digital ones, and our primary mode of interaction is through platforms like forums & chats.