Tweetable summary: Explore your thoughts and the words we use. Call 314 222 0893 or visit http://www.letsconsider.us/.
Let’s Consider is a phone-based service that users can call and explore what they are thinking about at a moment. Side effects may include some humorous chuckles, and a bit of scratching-of-the-head. With Let’s Consider, a user starts with ten broad categories and then can explore over 30,000+ English-language concepts and words.
Let’s Consider is a mashup of Twilio communication services for phone connectivity, WordNet for hierarchical concepts, a library for simplifying WordNet queries, and natural language processing module for Node.js.
Process
Let’s Consider is the result of multiple iterations.
Originally, the plan was to visualize State of the Union text data using data visualization and text-analysis. Without an interesting question to ask the data, no interesting concepts arose.
Next, I looked at taking State of the Union audio and mashing it together into super-cuts based on particular phrases. Using detailed and precise transcripts to modify video clips is a very interesting idea with lots of applications. Dozens of audio or video clips could be layered all with a common phrase; video clips could be appended for an infinite State of the Union. Sadly, the technical challenge of getting precise audio transcripts proved insurmountable.
I did some brainstorming with Golan and others about other things we could do with audio. Eventually we were discussing new APIs and services coming out for phone-based applications. I started thinking about connecting people over the phone under different contexts—complaint line, self-help line, sharing experiences line. We were concerned that there might issues connecting people in such an open-ended way.
 Inspired by Jorge Luis Borges’ short story “The Library of Babel“, I decided to create my own Library of Babel of all the concepts in English in combination with an audio phone system. Borges’ short-story describes an unimaginably large library that contains 410-page books of every possible combination of characters. Librarians, deluged with so much information, try to find different ways to deal with all the books, but there is no way to order it.
Inspired by Jorge Luis Borges’ short story “The Library of Babel“, I decided to create my own Library of Babel of all the concepts in English in combination with an audio phone system. Borges’ short-story describes an unimaginably large library that contains 410-page books of every possible combination of characters. Librarians, deluged with so much information, try to find different ways to deal with all the books, but there is no way to order it.
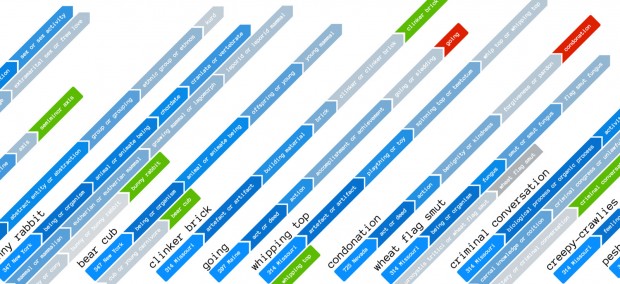
Instead of every combination of characters, Let’s Consider takes ten broad categories of concepts, and then allows the user to go through progressive, increasingly more-specific menus to find what they are interested in.
Description of Let’s Consider
“The Library of Babel” was published in the collection of short stories called The Garden of Forking Paths. “The garden of forking paths” would be an appropriate subtitle for Let’s Consider. Starting with broad categories, the user goes through more specific steps. Finally they arrive at a concept, then are asked to decide what synonym they are thinking about. They they tell whether this concept makes them feel positively or negatively. Then the call ends.
There is a website (www.letsconsider.us) that visualizes all the calls that have been received. The website serves as a repository for every interaction that people have with the system.
There were two main challenges with making this concept work: how to frame the interaction broadly and how to design an audio-only system.
Framing the concept was a challenge. Some suggested this concept could be used to actually generate interesting information about the person. If a person was going towards sad or melancholy ideas, the system could suggest they do something fun, etc. Others suggested that it could be an absurd experience combining random prompts as the user goes down a rabbit hole of concepts.
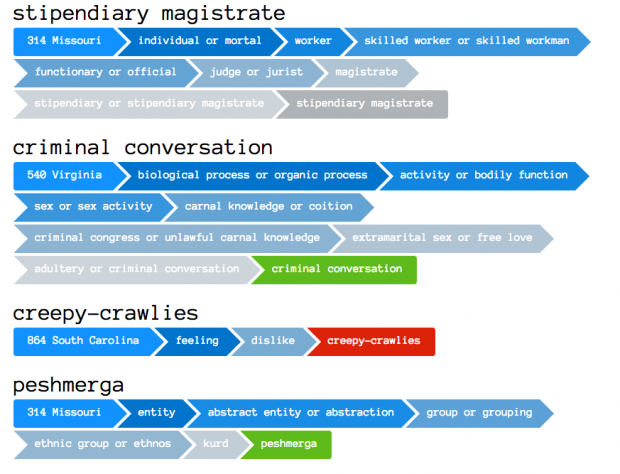
I initially used a framing of complaining or grousing. Users were prompted to figure out what was bothering them at the moment (working system name: Let’s Kvetch). I changed this to a psychotherapist framing. The system would infinitely ask questions until arriving a definitive solution humorously at odds with the probing questions.
Based on feedback, I reduced the framing and instead prompt people to try to discover what they are thinking about. I like this framing because it encourages centeredness and reflection using a rather absurd system.
The other challenge was designing the audio only system. Most of the menus the user encounters contains a list of complex concepts. For example trying to find common house plants requires the user to recognize that they are “vascular plant or tracheophytes.” I tried a few ways to get around this including ordering the labels in different ways. I ended up surfacing examples for every choice, so “vascular plant or tracheophytes” also has “such as rose bushes, elm tree, or basil.” This still isn’t perfect because some of the references are obscure and only three examples doesn’t give an accurate overview of 1,000+ concepts. Still it’s a start.
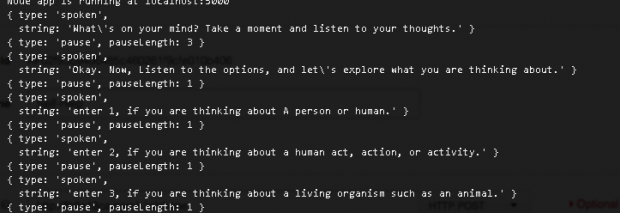
Timing and word usage were another detail that was important. Twilio allowed inserting pauses in second increments. I wish they had allows millisecond pauses because I would have used those too. Also, the text I sent to Twilio includes periods where commas should be to slow down Twilio’s voice.
Conclusion and Thoughts
Let’s Consider is a middling success in terms of art piece. It requires a lot of work for the user to engage with the service and once the user does, it is a challenge for them to accurately navigate the menu system to get to the concept they are thinking about. Where Let’s Consider is successful is a playful exploration of words and concepts using synthesized voice instead text. The use of voice is especially effective in spite of the higher cognitive load it places on the user. The voice often mispronounces words comedically, and the voice reminds us that these words and concepts are often used in spoken contexts, not just on screen.
There are two areas I wish I could have improved for this final critique. One is to incorporate popularity rankings into the labeling system. By more prominently showing popular concepts, I think the navigability would be increased. I also think that the physical component of the system could better set the stage for the user. Right now, the system connects to any touch-tone phone. Madeline Gannon suggested using an old rotary phone on a pedestal to make the experience of using the system unique and different from normalcy. I agree with that. I think this system would be a nice “art” piece that people more conscientiously interact with.