For my final project, I’ve been working on creating a mashup of different panels from the Dilbert comic strip. Running for over 25 years, author Scott Adams has created close to 10,000 individual strips. To create the mashup, I needed the text from each individual comic strip panel.
As part of the earlier data scraping assignment, I wrote some Python code to scrape the text of each of the Dilbert comic strips embedded in the page source from Dilbert.com. However, the text only applies to an entire strip, and does not specify the words associated with each particular panel.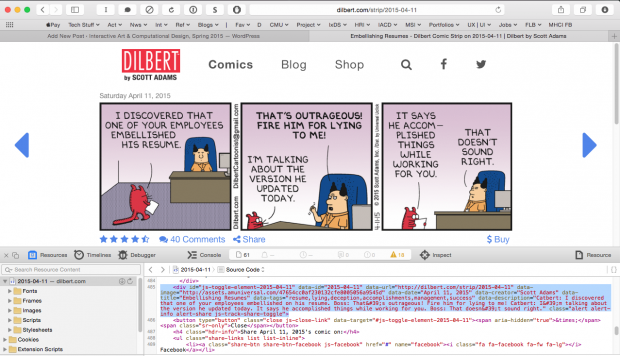
For this assignment, I wrote additional Python code to scrape and download each individual comic strip that has been published online. I then had code go through each strip to separate it into individual panels so they could be mashed up with other panels.

In order to isolate dialogue to specific panels, I intended to perform optical character recognition (OCR) on each of the panels. However, using the Tesseract OCR library by itself showed that it is not intelligent enough to separate dialogue from two separate characters (such as the right-most panel, above) — the OCR library treats it as a single block of text.
To work around this, Golan provided me with clever suggestions and valuable software support to use OpenCV and OpenFrameworks to perform a sequence of image manipulations. First, a flood fill from the black upper-left corner is performed to take out the characters, who are always touching the bottom edge. The image is then converted to grayscale, and a median filter is applied to remove pixel noise. The dialogue letters are then dilated to consolidate them into defined, isolatable blobs so that bounding rectangles can be formed. 
The coordinates of the bounding rectangles of each panel were stored in an XML file, which was then used by another Python program to perform OCR on each of the blobs, and use the scraped dialogue as ground truth to determine which OCR’ed text is associated with a specific panel by using the Levenschtein distance algorithm.
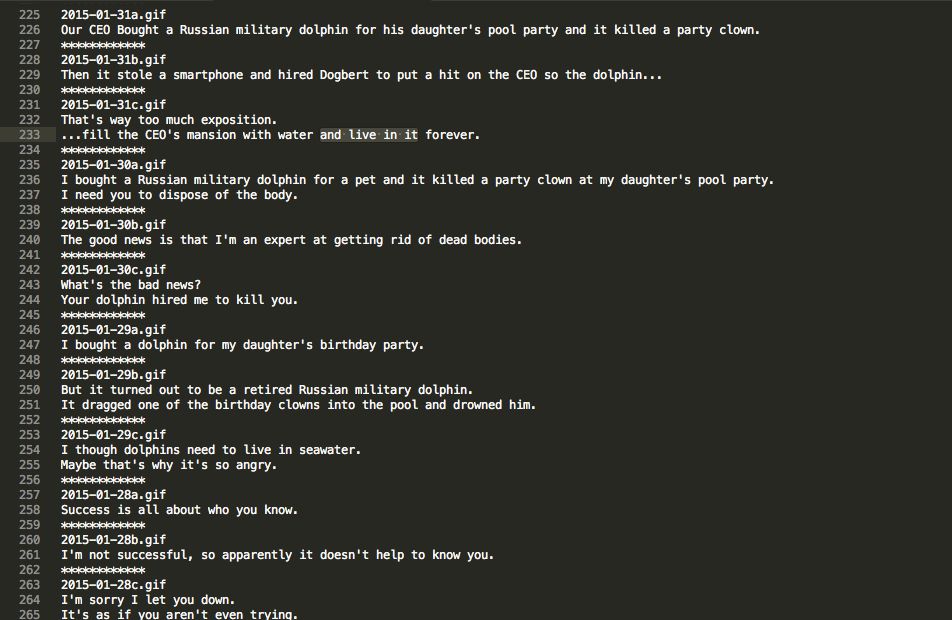
Once the dialogue for specific panels were captured, I then used the CMU rhyming dictionary to randomly assemble a set of panels that rhyme with each other. I’m still working on a Python web server interface, which would allow the user to initiate the generation of a new strip.
