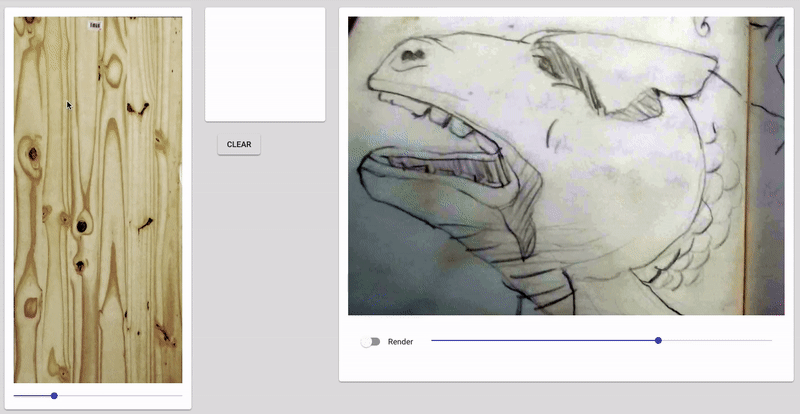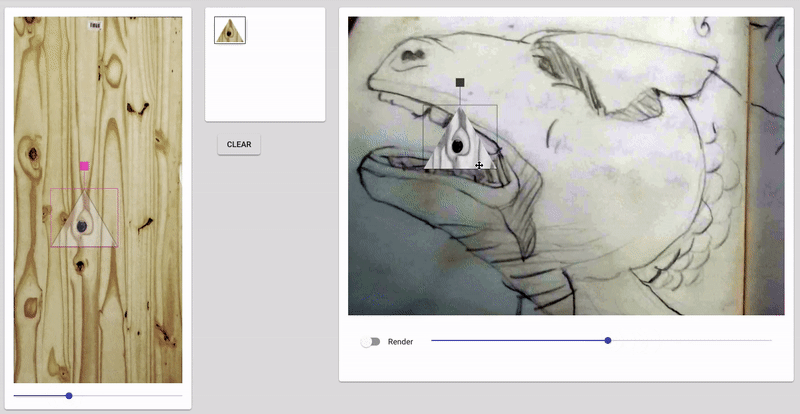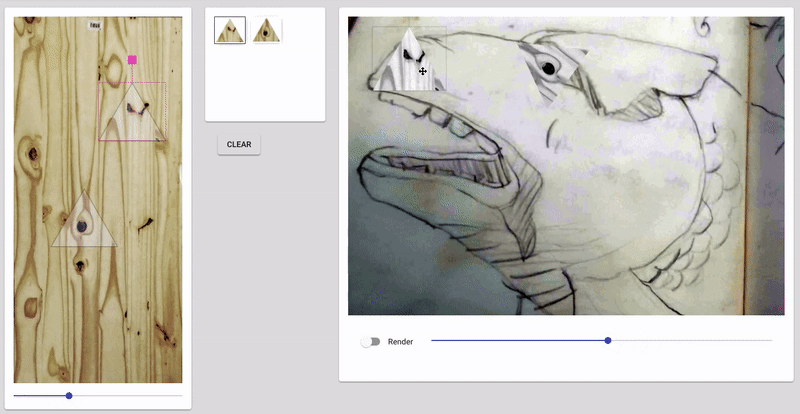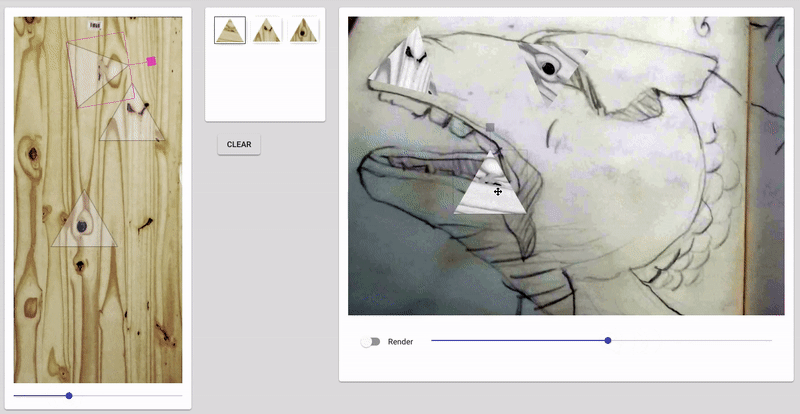
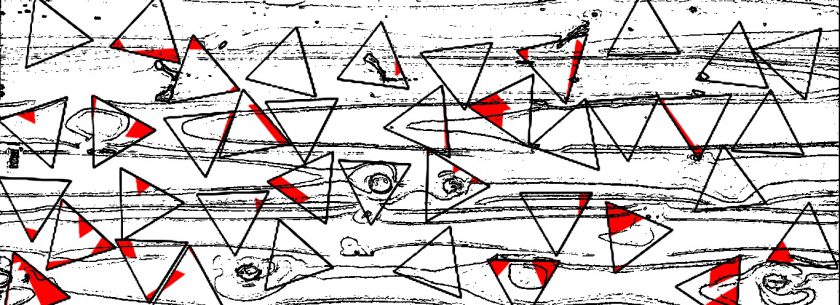
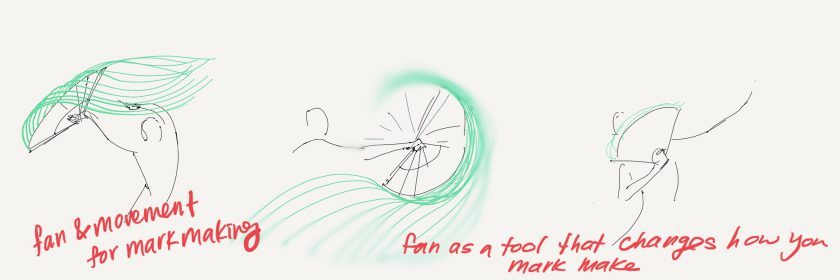
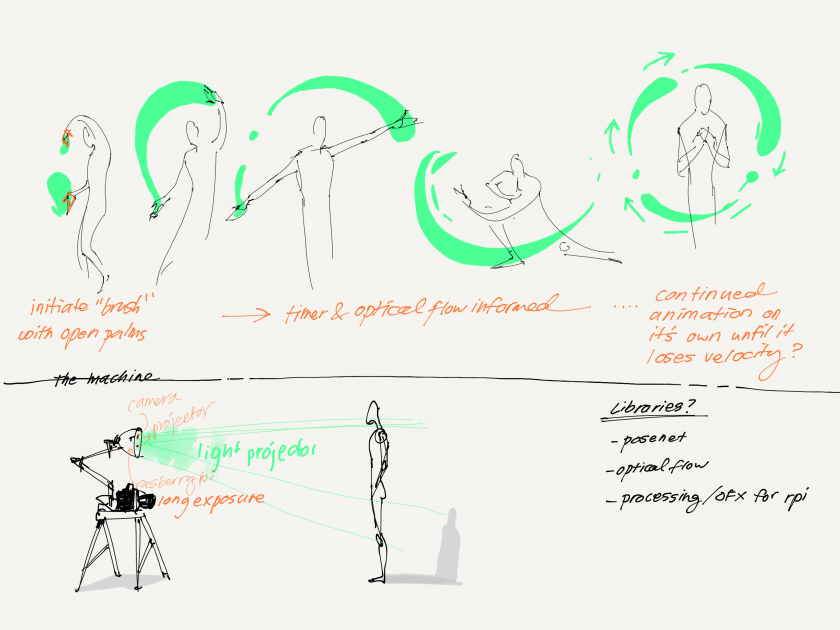
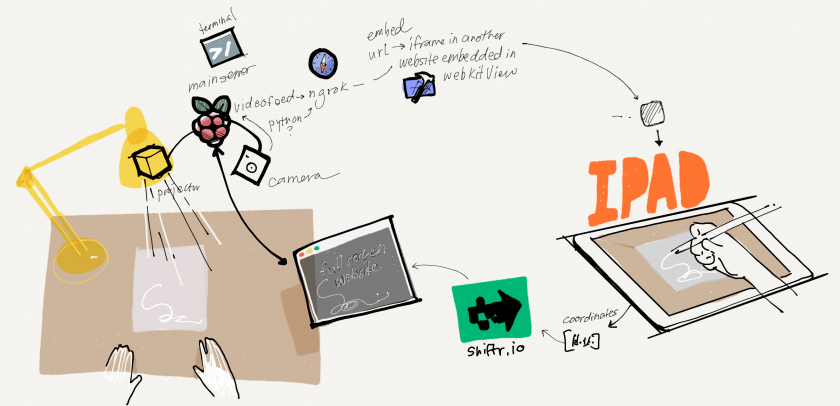
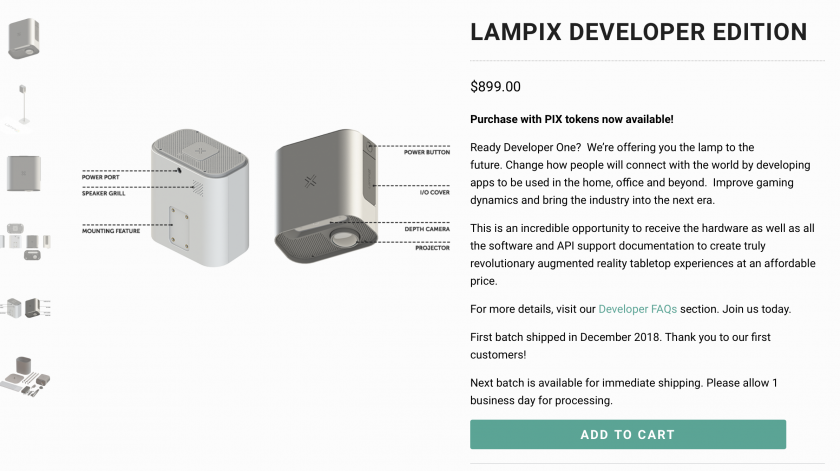
Some screenshots of the “drawings” after 20 minutes of napping post-video and after implementing a 3rd ‘trigger’/training session
Brain User Interface based Drawing
When stripped down to the bare bones, this project was my first attempt at trying to create a drawing based brain user interface (BUI) using a commercially available brain wave sensing headband (Muse2) in order to do so.
My interest in creating such a piece originally laid in the desire to develop a program that could transcribe your dreams as illustrations while you were unconscious, allowing you to wake up to a image that was supposed to be a transcribed dream journal of sorts… Specifically I wanted to use brainwaves of a sleeping user in order to begin to draw a thing which then would be completed by SketchRNN (when it decided that it was certain it knew what was being rendered), and then move onto the next start of a drawing, repeating over and over until the user wakes up in the morning only to see a composition of “their dream” (or rather what the program believe their dream to be). Unfortunately, this was not achievable in the time given for this project due to a few factors:
a.) The fact that the brain sensing headband didn’t arrive until about 6 days before the project was due
b.) my own unfamiliarity with the programs necessary to make a program like that become reality
Considering the first obstacle in particular I found it conducive to try and narrow down my scope as much as possible to this: a program with which you could use the raw EEG data of your brainwaves to paint with, so essentially using your focus on particular thoughts in order to manipulate a digital painting tool – Though as you will see, this too was much more difficult than I initially expected.
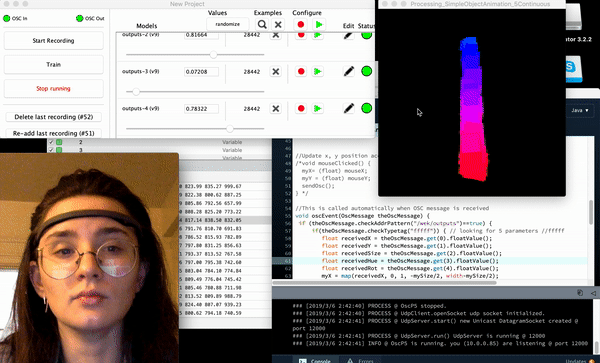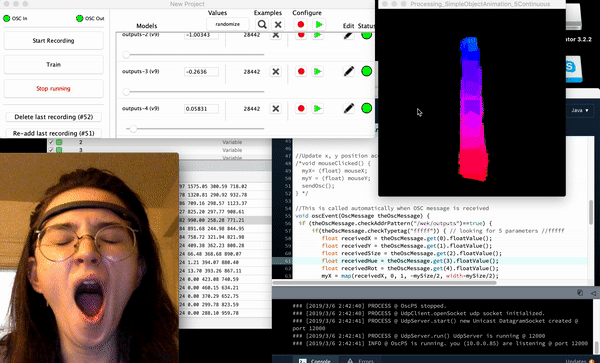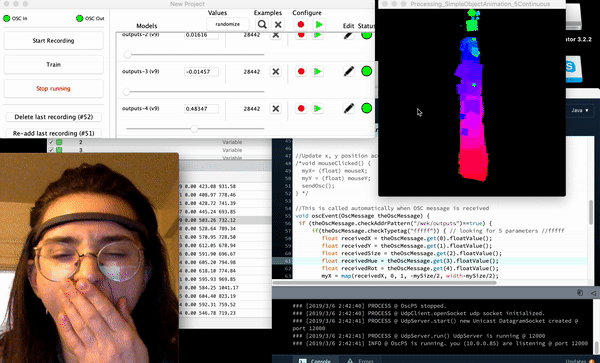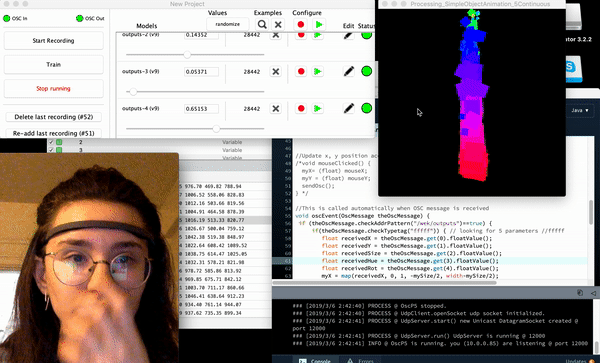
Process
Much like Golan warned me, the “plumbing” for this project seemed to suck up the most amount of time – as it was a great deal of work trying to get information out of the headband in the form of OSC data (so that I could forward it into Wekinator, use machine learning in order to “train” the drawing program, and then from there implement it in processing).
The plumbing actually required a few extra steps, one of the most important being getting to know OSCulator (an extremely valuable tool recommended to me for use by Golan) – even though I had the ability to export the OSC data of the headset via the 3rd party app, museMonitor, all of the OSC data being exported was in the form of several separate messages (a format that Wekinator didn’t seem to recognize) so I used OSCulator in order to format the OSCdata into Wekinator’s standardly and only accepted float list format. Though there is a great deal of information on muse headset data, and wekinator alone – there is hardly any information on the use of wekinator, OSCulator, and muse in combination so much of my time was spent doing research simply on how to get the information from one platform to another.
Overall, this slightly frustrating and certainly trying process took me the better half of 5 days, and as a result I wasn’t able to spend as much time on the concept or actual training of the application unfortunately. In retrospect, I’m glad I was able to accomplish as much as I did considering how little information I felt there was regarding such a niche method in addition to how little I initially felt I could comprehend. It was definitely an amazing learning experience.
Future Iteration…
So, even though I do have a BUI that functions somewhat coherently, I do think that I would have liked to spend more time on fleshing out my original concept or even implementing features to turn this into a clever game (such as a very difficult game of “snake” or some sort of a response to fugpaint that takes frustration with interface to a whole new level provided nearly impossible workarounds). I will be spending more time on this because it’s been a pretty engaging idea to play with/develop.
Special thanks to:
Golan (for introducing me to some very helpful tutorials on how to use Wekinator, for turning me onto OSCulator which I eventually used to get the OSC data into Wekinator, and for encouraging me to pursue the development of this project!)
Tatyana (for suggesting Wekinator to me when I initially pitched my idea to her before we shared our research in class for the midway point)
Grey (for making some very helpful suggestions as to how I could get the OSC data into Wekinator without the use of OSCulator, and for offering his assistance to me )
Tom (for acquiring the muse headband!)