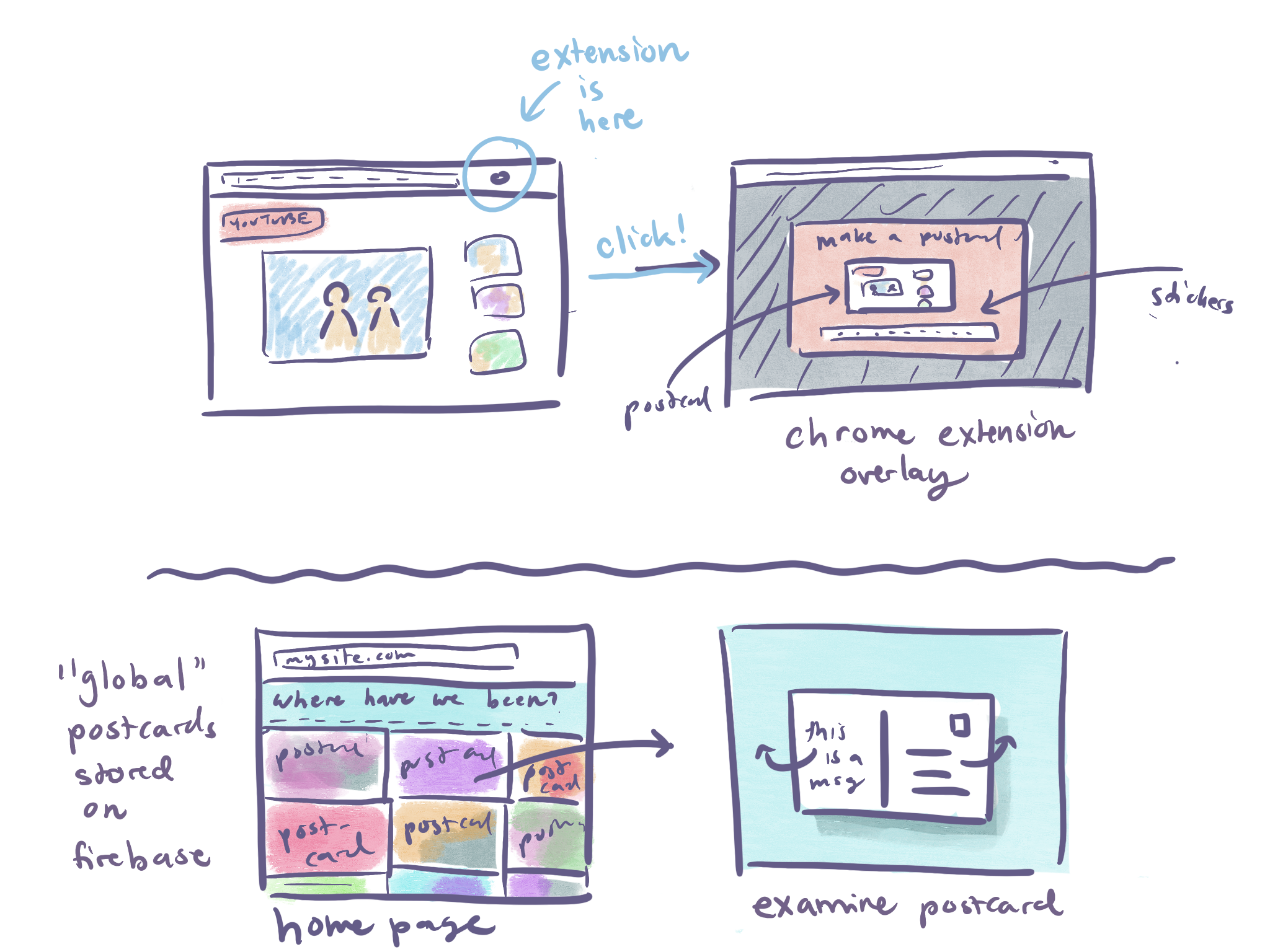
I plan on completing my manufactory project, which is a chrome extension that allows you to generate physical, mailable postcards from your internet adventures. “We live on the internet, so why not share your travels?”
For my final project, I intend to complete my Rebus Chat app that I began for the telematic project (http://golancourses.net/2019/jaqaur/04/10/jaqaur-telematic/). It will be basically the same as I described in that post, but I have changed part of the Rebus-ification pipeline and also solidified my plans for implementing the rest of the app.
The new Rebus-ification pipeline will not use Rita or The Noun Project‘s API (though I will still use icons from The Noun Project). I will use The CMU Pronouncing Dictionary to get IPA pronunciation for everything users type. I will also manually create a dictionary of 1000-2000 images, along with their pronunciation (these will be short words whose pronunciation is quite common). Then, I will try to match substrings of the users’s typed syllables with syllables I have in my dictionary. I will insert the images in place of the corresponding words.
In terms of other implementation details, I am using Android Studio along with Firebase to help with authentication and data storage (which I highly recommend). I have big dreams for this project; I hope I can finish it all in time!
For the final project in this course, I will be putting finishing up the piece I have been working on for the senior show: the work itself is a digital compilation of dreamscapes based off several dreams I had during a 3-month period of insomnia. It is interactive, and you can transition through/interact in different dreamscapes through the use of the tobii 4c eye tracker (i.e. your gaze is a subtle, almost unrecognizable controller of sorts…) Much like real dreams, the interaction will be very distorted, sometimes triggering responses that distance you from what you intend (for example when you look at something it stops moving or doing whatever interesting interaction it was before)…
I will be putting it into the Ellis but since there are two eye trackers, I hope I will be able to use one for the class exhibition as well on a separate NUC.
At the moment I am compiling all of the dream sequences into processing (from P5.JS so that they are compatible with the eye-tracker…) and putting the finishing touches on the interactions.
I propose to complete my watershed visualization project that I began but did not critique for Project 2. My project’s conceit is to generate a line in AR that visualizes the flow of water out of the given Pittsburgh watershed that you are standing in. It might look something like this:
As I’ve gotten feedback about this project, I’ve come to some important insights:
Watersheds are interesting because they contain themselves: A watershed is an area in which all the water flows to one point. The Allegheny and the Monongahela watersheds are a part of the Ohio watershed, which is a part of the Mississippi. What areas are too small to be watersheds? Where does this cycle end?
It’s important to connect this visualization to actionable information about protecting our watersheds. A raw visualization is interesting, but not enough to affect change.
Some aspects of the visualization can be connected to the viewer so that it feels more actionable. For this reason, I think it’s important that the visualization is grounded in the way that water flows from the point the viewer is standing on, as opposed to defining the borders of the watershed more generally. In this way, the viewer might understand their impact on their environment more easily.
My technical accomplishments so far:
I have built an AR app to iPhone.
I have loaded the Mapbox SDK in Unity, and I can represent my current location on a zoomable, pan-able map.
I have loaded the Watershed JSON data from an API, and can represent its geometry on the Mapbox map.
What I still need to do:
Draw a line of best fit, representing the flow of water, through the watershed containing the viewer’s current location, and add some randomness to it so that it’s a squiggly line, but still within the real bounds of the watershed.
Draw a line that connects the current location of the viewer to this line of best fit through their watershed, and add some randomness to that.
Create an AR object pointed in the direction of that line.
Model that AR object so that it appears to be a line on the groundplane.
Model that AR object so that it extends in the direction of the line, and curves based on the curves of the line, at approximately the appropriate distance from the viewer.
Test so that the line can be followed and updates accordingly.
I am thinking of using p5.js, webGL and hopefully some other libraries to create shaders that give an abstract representation of places, times and color palettes that I associate with certain places and times in my life.
An important aspect of this project is going to be creating a representation of these places that feels true to me but is also relatable to other peoples’ experiences. I think that I will need to think a lot about sound, velocity and interaction in order to make this a satisfying experience for me as a creator as well as for the audience.
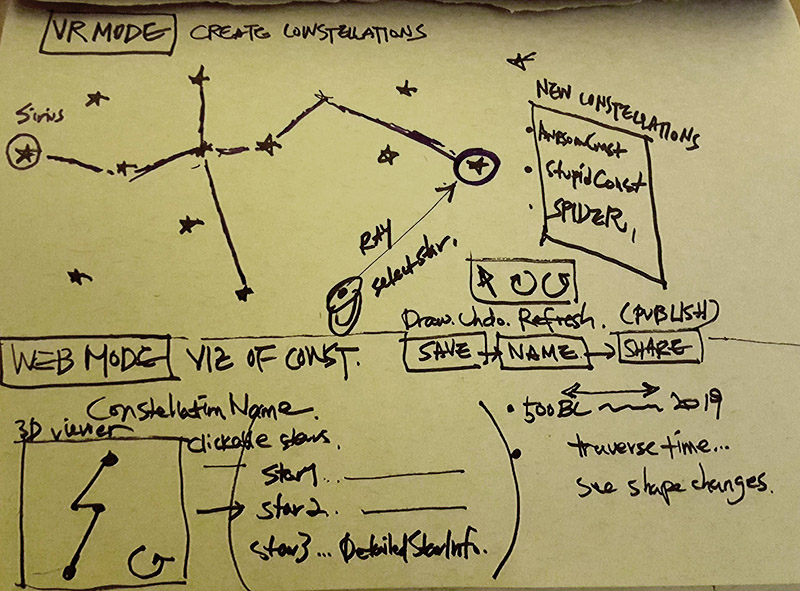
I plan to build a system that allows anyone to create their own constellations in virtual reality (VR), and easily save and share their creations with other people. Users would be able to select stars from an interactive 3D star map of our Galaxy that consists of the 2,000 brightest stars in the Hipparcos Catalog, and connect any of the stars together to form a unique custom constellation shape from Earth’s perspective. When the constellation is saved and named, users would be able to select and access detailed information on each star. They would also be able to break away from Earth’s fixed viewpoint to explore and experience their constellation forms in 3D space. The constellation would be added to a database of newly created constellations, which could be toggled on and off from a UI panel hovering in space.
The saved constellation data would also be used to generate a visualization of the constellation on the web, which would provide an interactive 3D view of the actual 3D shape of the constellation, with a list of its constituent stars and detailed information of each star. The visualization may potentially include how the constellation shape would have appeared at a certain point in time, and how it has changed over the years (e.g. a timeline spanning Earth’s entire history).
The core concept of the project is to give people the freedom to draw any shape or pattern they desire with existing stars and create a constellation of personal significance. The generated visualization would be a digital artifact people could actively engage with to uncover the complex, hidden dimensions of their own creations and make new discoveries.
A sketch of the concept below:
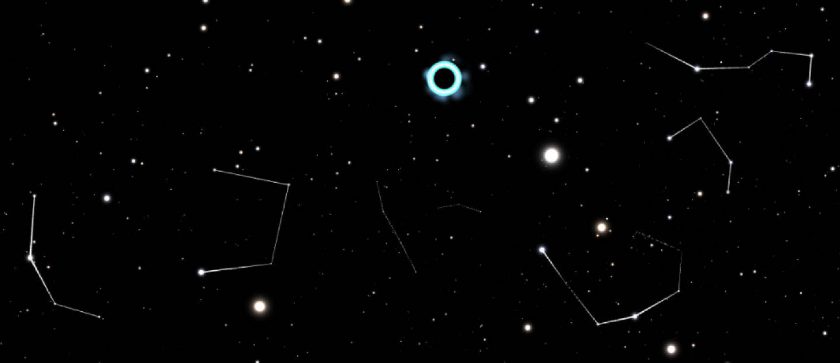
A rough sketch of the builder and visualization functionalitiesInteractive 3D star map I built in VRExploring constellation forms in 3D space, and accessing their info
For my final project, I would like to create one or two interactive wall projections. I’ve always imagined my Box2D project displayed on a large wall where people could approach it and interact with the shapes by touching it, so I think expanding on that idea wouldn’t be too bad of an idea. I also just have a large affinity for simple geometries.
The first step would be to get the first Box2D project working as an interactive projection. Next, I would use that as a stepping stone to create different ones. One thought that I had was a pulsing blob that people could pluck smaller blobs from to play with and merge with other blobs that are on the projection. Another that I thought of was a scene similar to the warp speed animations in Star Wars where particles would converge to a focus point (I can’t think of the correct term at the moment) and more focus points would be generated if more people approached it.
To achieve this I would use a standard projector for the animation and a kinect for body tracking since its implemented rather well in that hardware. I think that my main technical issue would be the calibration of the kinect to the projection on the wall.
I want to make a system that attempts to maximise some bodily response from a viewer.
This requires a parametric image and a way to measure bodily response in real-time. Given the hardware available, the simplest options seem to be either using heartbeat data, or the Muse EEG headband.
The project works as follows: Modify the parametric image. Evaluate response. Estimate gradient of emotional response w.r.t parametric parameters of image. Take a step of gradient ascent in the direction in parameter space that maximises the estimated emotional response function using reinforcement learning or genetic algorithms. Repeat. An alternative route would be to train a neural network to predict emotional response, and optimize using its surrogate world-model gradient, which would enable using stochastic gradient descent to optimize the image much faster.
Given the slow response of heartbeat data, I should use the Muse headband. In addition, we know the approximate timeframe that a given visual signal takes to process in a brain, although it remains to be seen if the noisy data from the EEG headband can be optimized against.
This project parallels work done using biofeedback in therapy and meditation, although with the opposite goal. An example of a project attempting to do this is SOLAR (below), in which the VR environment is designed to guide (using biofeedback, presumable using a Muse-like sensor) the participant into meditation.
For the parametric image, there are a variety of options. Currently, I am leaning towards using either a large colour field, or a generative neural network to provide me with a differentiatable parametric output. It would be awesome to use bigGAN to generate complex imagery, but the simplicity of the colour field is also appealing. A midway option would be to use something like a CPPN, a neural network architecture that produces interesting abstract patterns that can be optimized into recognizeable shapes.
Fall in love, go through rough patches, have it easy and wonderful, get baggage, meet other people. Don’t Let Me Down is a 2 player game about being each other’s foundations.
The second is doodle-place (doodle-place.glitch.me). I’ll be adding some grouping to the creatures so the world is more organized and interesting to navigate. I might also try Golan’s suggestion which is synchronize the creatures’ movement to some music.
Finally I want to add a simple entry screen for the emoji game (emojia.glitch.me). On it you’ll be able to customize to some extent your outfit, or maybe see some hints about gameplay. I’m not sure if this will be an improvement, but I think it can be quickly implemented and figured out. I also want to put the game on an emoji domain I bought last year: http://🤯🤮.ws (and finally prove it’s not a waste of my $5)