CHIMERA MACHINE EXPERIMENTS
(work-in-progress)
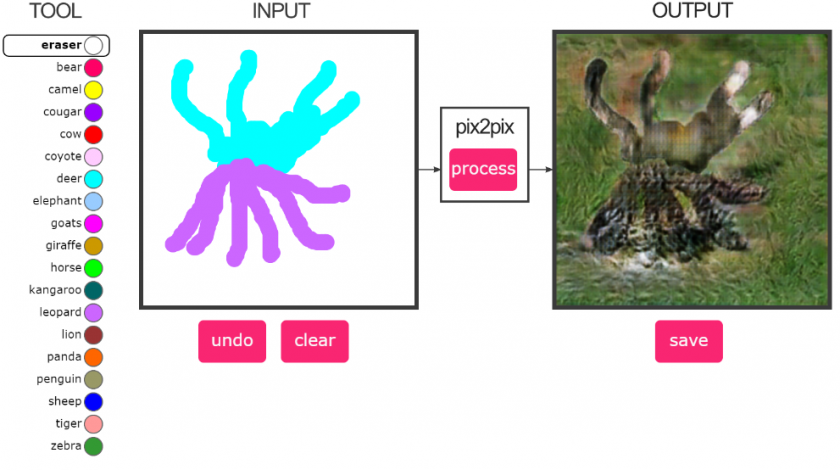
Sample Results



Process: Ideations & Explorations

Throughout history, human beings have been fascinated by imaginary, hybrid creatures, which appear in myriad forms in many different cultures. My initial idea was to enable people to merge different parts of human and animal anatomical features, but via the expressive drawings of stick figures.
My approach involved applying different color brushes to represent different animals, and combining different color strokes to give form to wildly divergent hybrid animals that stimulate our imagination.
Concept Development

MY FIRST FORAY INTO MACHINE LEARNING..
I decided to use Christopher Hesse’s Pix2Pix tensorflow build to train and test a new GAN model specifically designed for chimera creations. It was a great opportunity to become familiar with creatively working and experimenting with ML, including its quirks. Understanding how the training process works in terms of the code was quite a learning curve. Setting up the right environment to run super-long, GPU-intensive tasks was not a straightforward process at all. Every different version of Pix2Pix had its own specific library and version dependencies for python, CUDA toolkit and cuDNN, so there was much trial and error involved in finding compatible, functioning versions to get everything reliably working (as in not crashing every 30 minutes or so).
Dataset Collection & Manipulation


The dataset I ultimately chose for training was the KTH-ANIMALS dataset, which included approximately 1,500 images of a wide variety of animals (19 different classifications) with the foreground and background regions manually segmented. At first I thought the segmentation data was missing, since I could only see a stream of black png images; it turned out that the creator of the dataset just had a matrix for each mask and saved it in the form of pngs. I had to batch process the files to identify the different pixels (I had to identify the number of unique pixel values to determine the number of masks in the image and the background pixel value, which was most frequently (2,2,2) for images with one animal, (3,3,3) for two animals.)
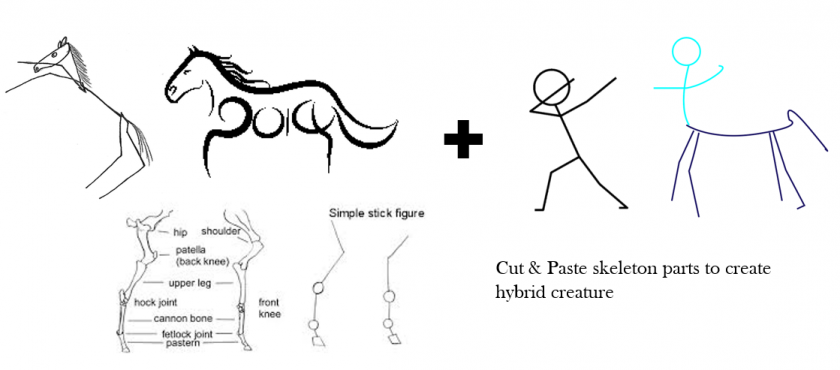
Data selection was pretty tricky and challenging, because there were not a lot of datasets out there that were suitable for my purposes. I narrowed my search from (specific) animals and humans to just (general) animals, especially since it was difficult to find datasets of nude human beings that were not pornographic. There were no animal datasets I could find with pose or skeleton estimations; the only thing that came closest was research on the pose estimation of animals through deep learning, which consisted of training models to recognize certain parts of the animal’s anatomy by manually marking those parts in selective video frames (DeepLabCut, LEAP). I decided to try experimenting with masks instead of detailed annotated skeletons as a proof of concept.
Since the workable size for pix2pix was constricted to 256×256, the auto-cropping unfortunately cropped much important information from the imagery, such as the head and hind areas. I spent quite some time trying to implement seam carving (context-aware cropping) and replicate the same cropping method for both images and masks, but failed to find convenient ways of achieving this without a deeper understanding to substantially edit the code (I do plan to look deeper into it when I get the chance). I also looked into Facebook’s Detectron object recognition algorithm to automate the mask creation for photos that do not come with masks, for higher quality training data curation in the future.
Training Process
Training was set at 200 max epochs, on an i7 Windows 10 desktop computer with a Nvidia GeForce GTX 1060 GPU. The Pix2Pix-tensorflow version used for training was proven compatible and stable with python 3 + CUDA 10.0 + cuDNN 7.4 + tensorflow-gpu 1.13.1. (As of the timing of this post, the tf-nightly-gpu is too unstable and CUDA 10.1 is incompatible with cuDNN 7.5). Whereas training with tensorflow (CPU version) took 12+ hours to reach only 30 epochs, training for 200+ epochs on a CUDA-enabled GPU took less than 12 hours on the same desktop.
I edited the code to export the model into a pict format on CoLab, since the code was flagged as malicious on every computer I tried running it on.
input output target input output target



Discussion
Pix2Pix is good at recognizing certain stylistic features of animals, but not so great at differentiating specific features, such as the face. You can see how it often obliterates any facial features when reconstructing animal figures from masks in tests. To isolate features, I believe it would be more beneficial to train the model on detailed annotations of pose estimations that differentiate parts of the anatomy. It would be good to train on model on where the arms begin for instance, and where it ends to see if it can learn how to draw paws or horse hoofs. This approach might also enable the drawer to combine figures with detailed human anatomical parts such as our hands and fingers. I would have to experiment with human poses first (face, general pose, hand poses etc.) to see how robustly this approach works.
The way Pix2Pix works constrains the learning to a specific size, which can be immensely frustrating, since datasets rarely contain just one uniform size, and cropping photographs of animals often sacrifices important details of the animal structure as a whole.
The reconstruction of the background imagery is interesting. I didn’t isolate eliminate the background to train the model, so it applies a hybrid approach to the background as well. I didn’t differentiate one mask from another in the instance of multiple masks in one image, half hoping this might actually help the model combine many of the same creatures at once. I’ll have to compare this model with a model that is trained to differentiate the masks, and see how the results differ.
Ideas for Expansion
I would like to continue experimenting with different approaches of creating hybrids to fully explore the type of imagery each method is capable of creating. (CycleGAN, for example, might be useful for creating wings, horns, etc. from skeletal lines to augment features.) I want to curate my own high-quality animal dataset with context-aware cropping. I also want to play with image selections and filtering, and see if I could train a machine to create images that look more like drawings or sketches.
I would love to build a less rigid interface that allows more expressive gestural strokes, with controllable brush size and physically augmented options such as Dynadraw-type filtering. I would also want to play with combining human (nude) figures with animals, as well as with mechanical objects. I think it would be interesting to explore how GAN could be used to create interesting human-machine hybrids. Would it produce hallucinogenic imagery that only machines are capable of dreaming and bringing into being? Using pose estimations would also allow me to explore a more refined approach to intelligently and deliberately combining specific parts of animals and human beings, which may prove useful for creating particular types of imagery such as those of centaurs.