I expanded upon my event project, which used a generative neural network to ‘rot’ and ‘unrot’ images.
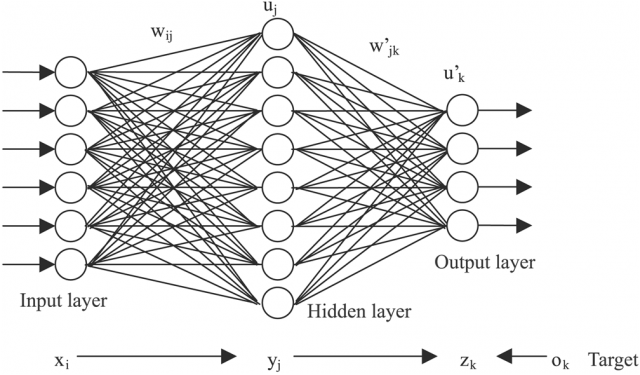
Summary of Neural Networks
Neural networks are an artificial collection of equations which take some form of data as input and produce some form of data as output. In the above image, each of the leftmost circles represents input nodes, which accept a single decimal number. These inputs can represent anything, from statistical information to pixel colors. Each input node then passes the input on to every node in the next layer. The nodes in the next layer accept every number from every one of the input nodes, and combine them into a new number, which is passed along to the NEXT layer. This continues until we reach the output layer, where the numbers contained in the output nodes represent the ‘final answer’ of the network. We then compare this final answer with some intended output, and use a magical method known as backpropagation to adjust every node in the network to produce an output closer to the intended one. If we repeat this process several million times, we can ‘train’ the neural network to transform data in all sorts of astonishing ways.
pix2pix
pix2pix is a deep (meaning many hidden layers) neural network which takes images as input and produces modified images as output. While I can barely grasp the conceptual framework of deep learning, this github repository implements the entire network, such that one can feed it a bunch of image pairs and it will learn to transform the elements of each pair into each other. The repository gives examples such as turning pictures of landscapes during the day into those same landscapes at night, or turning black and white images into full color images.
I decided to see if the pix2pix neural network could grasp the idea of decay, by training it on image pairs of lifeforms in various stages of putrefaction.
My dataset
I originally wanted to do my own time lapse photography of fruits and vegetables rotting, but quickly realized that I had neither the time to wait for decay to occur, nor a location to safely let hundreds of pieces of produce decay. Instead, I opted to get my data from Youtube, where people have been uploading decay time lapses for decades. I took most of my image pairs from Temponaut Timelapse and Timelapse of decay, both of whomst do a good job of controlling lighting and background to minimize noise in the data. By taking screenshots at the beginning and end of their videos, I produced a dataset of 3850 image pairs.




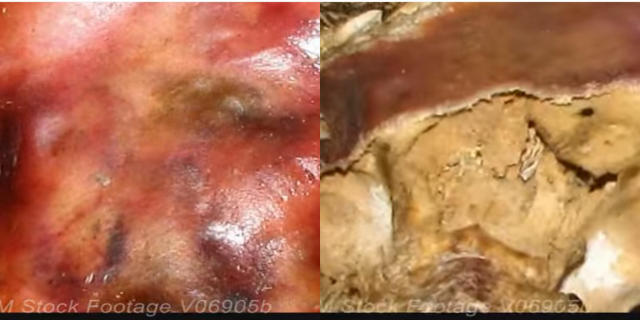
I trained two neural networks: one to ‘rot’, and the other to ‘unrot’. After training each network for 18 hours, they were surprisingly effective at their respective grotesque transformations. Here is an example of the unrotter puffing me up in some weird ways.
Normal:

Unrotted:
However, the pix2pix network can only operate on images with a maximum size of 256 x 256 pixels, far too small to be any real fun. To fix this, I tried both downsampling and splitting every image into mosaics of subimages, which could be passed through the network, then put back together, resized, and layered on top of each other to produce larger images:![]()


However, the jarring borders between images had to go. To remedy this, I create 4 separate mosaics, each offset from the other such that every image border can be covered by a continuous section from a different mosaic:




We then combine these 4 mosaics and use procedural fading between them to create a continuous image:

Doing this at multiple resolutions creates multiple continuous images…

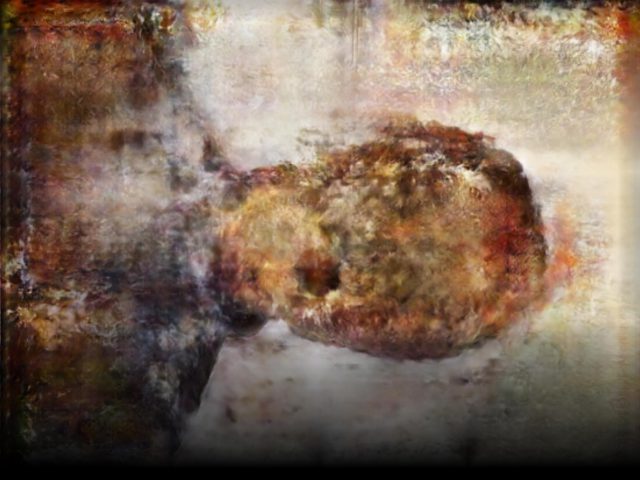
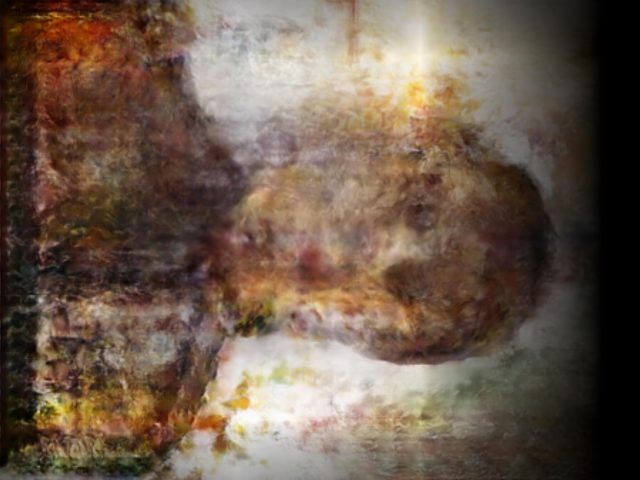

…which we can then composite into a single image that contains information from all resolution levels:
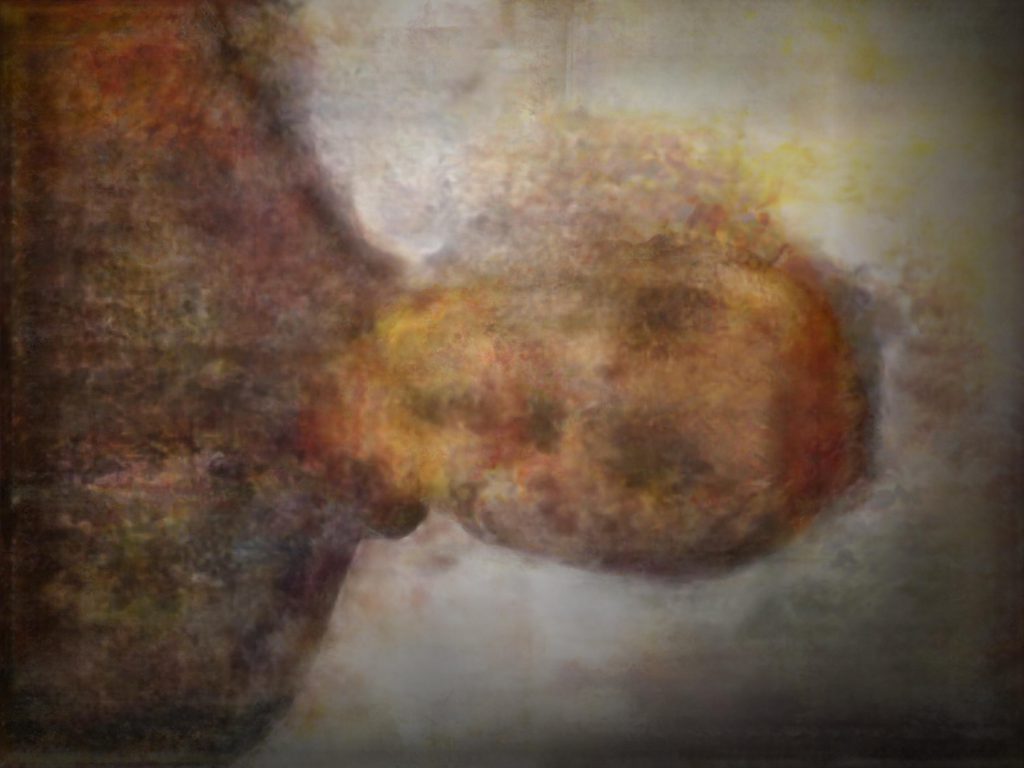
Using this workflow, we can create some surreal results using high resolution inputs:



—-

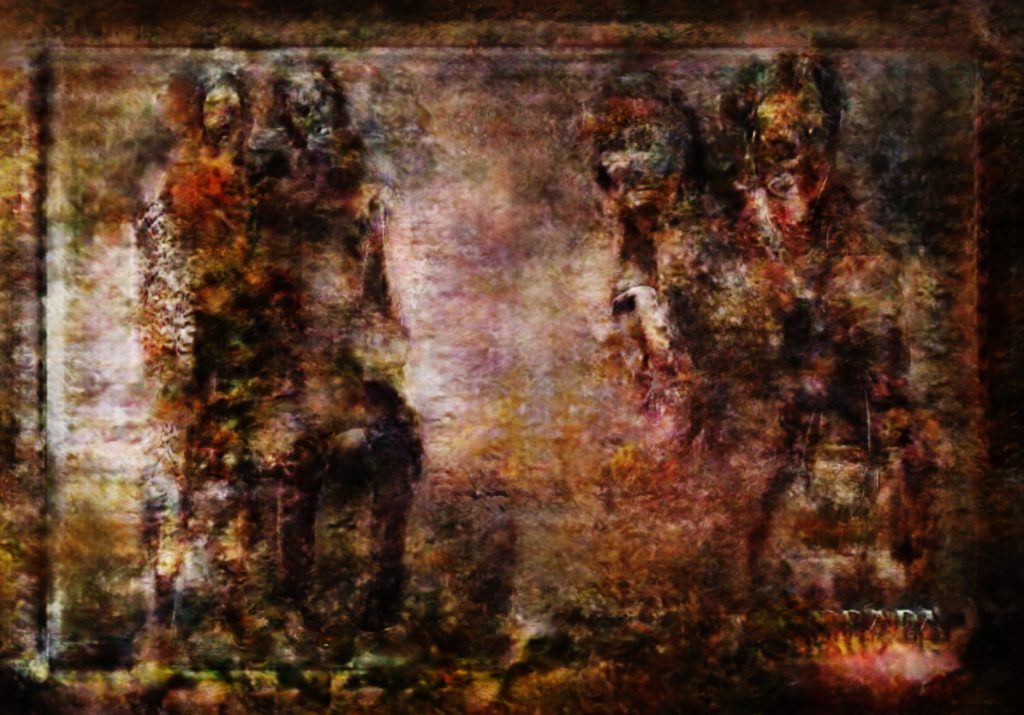
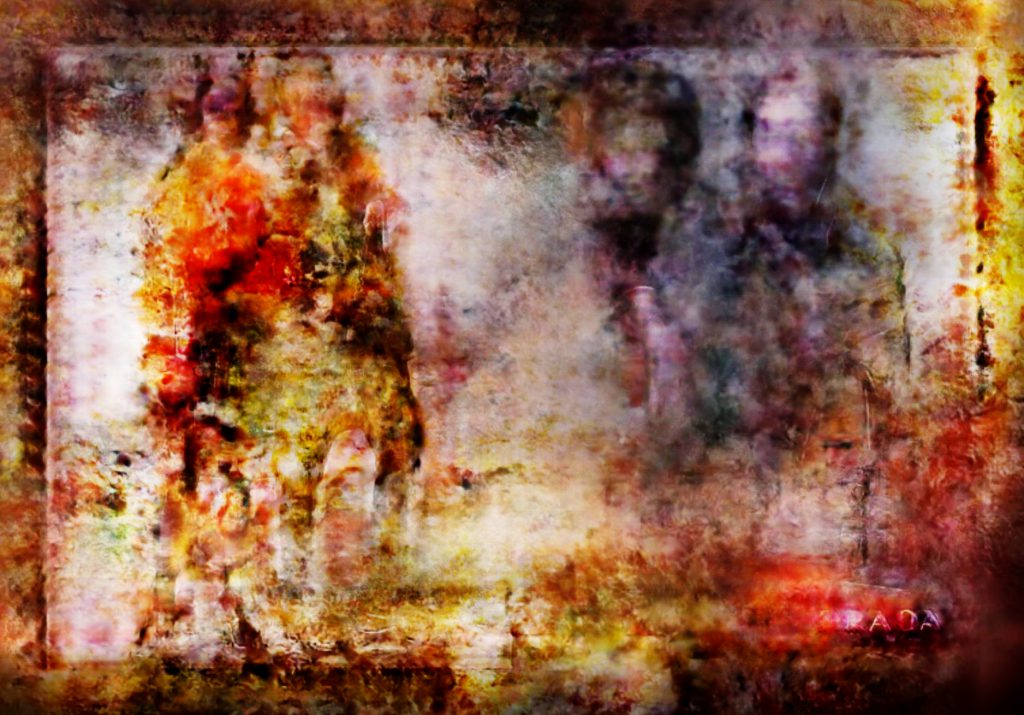
—-
![]()

![]()
—-
Golan Levin provided me with Ikea’s furniture catalog which produced interesting, albeit lower-res, results:



—



Next Steps
The entire process of downsampling, splitting, transforming, and recompositing the images is automated using Java and Windows batch files. I plan to create a Twitter bot which will automatically rot and unrot images in posts that tag the bot’s handle. This would be both interesting to see what other people think to give the network, and a great way to get publicity.
The training dataset, while effective, is actually pretty noisy and erratic. Some of the training images have watermarks, youtube pop-up links, and the occasional squirrel, which confuse the training algorithm and lead to less cohesive results. I would love to use this project as a springboard to get funding for a grant in which I set up my own time lapse photography of rotting plants and animals using high definition cameras, many different lighting conditions, and more pristine control environments. I think that these results could be SIGNIFICANTLY improved upon to create a ‘cleaner’ and more compelling network.
Special thanks to:
Phillip Isola et al. for their research into Image-to-Image translation
Christopher Hesse for his open source tensorflow implementation
Golan Levin for providing Ikea images and suggesting a Twitter bot
Ben Snell for suggesting multi-resolution compositing
Aman Tiwari for general deep learning advice and helping me through tensorflow code