Monday Afternoon from Smokey on Vimeo.
My event process captures a boring non-time; me waiting, hanging with my cat. This ‘downtime’ is something I do every day, yet when I think about or communicate about my day, it is literally the gaps around which my actual ‘events’ take place. This idea wasn’t interesting to me until I realized that this sort of time is basically all my cat does. He chill’s all day long. I captured a few of these downtime moments, emphasis on my cat, I temporally overlapped the moments, and let them loop. In this way drawing focus to small details that otherwise go unnoticed, just like how these moments go unnoticed during our days.
I was further inspired by Cinemagraphs and Afrianne Lupien’s ‘Crazy Cat Portraits’, which do a great job of being a polished and crafted magical photos without loosing a documentation feel.

The system for capturing this was nothing special. Lots of 360 videos without moving a camera, but with moving my cat and myself. Then an After Effects composition to mask out sections, and repeating layers to create the loops for the last step. Some color grading for clarity, not style. Time consuming, but nothing tricky.
Process
This project took a lot of twists and turns, here is a updated review of my progress and how I got here. I wanted to push the boundaries of what I have been doing in 360 video. My main objective was to create something that seemed a little bit magical, while capturing an routine-like event, as looping is amenable to exaggerating and re-conceptualizing routines.
I knew if I could loop 360 with camera movement, I could achieve a solid effect.
My first experiments involved things that moved in some radial way. I could combine rotating objects, with -perhaps- opposing or in-sync camera movement to create visually stunning (and magical) environments.
Circular things look need in equirectangular format. @golan‘s face can be seen distorted on the bottom right. pic.twitter.com/ipF2bXuA4G
— Smokey (@hdyar) April 6, 2017
This ended in disappointment, for while they are interesting in an equirectangular view, the scene itself is just what it is. I was unable to build a rig to rotate the camera that I was pleased with, which I feel was the missing ingredient to this method.
I briefly experimented with larger radial camera movements, which were fascinating to watch in an equirectangular view, as the distortion morphs around.
Footage from a 360 camera tied to a ceiling fan looks exactly like you would expect it would. pic.twitter.com/vXFfoFfY6Z
— Smokey (@hdyar) April 16, 2017
Fascinating, but a proper inquiry into capturing interesting morphing equirectangular scenes is not what I set out to do, and in 360 they are just vomit inducing videos. Stabilizing could give myself some level of ‘freedom’ after the fact to make sure the loop points were perfectly lined up, and help prevent vomit; as well as more ‘perfectly’ (smoothly) morphing shapes. The first technique I tried was manually locking a point into the center of view. 10 seconds with this technique took over 2.5 hours of grinding effort in AutoPano video. The results were not worthwhile, motion blur and perspective distortion was too big of a factor on top of even an ideal single-point stabilization.
The second method was to transform the video into a cubemap, track points on each face, and stabilize (via warp) the average tracking between faces to create smooth transitions, and convert back to equirectangular. I used Mettle’s after effects plugins to perform this technique, which crashed my computer every time it tried to solve for the camera. While the technique is still conceptually solid, the camera movements, motion blur, and shake amount were seemingly too large for the method to handle.

When I finally settled on the method that would be my final project, I did a test shoot one evening. I filmed my room with just my cat in it for over 2 hours. 8.96gb of footage, and my cat almost didn’t move at all.
Sunday Night, Static Cat from Smokey on Vimeo.
In order to get around processing all 9gb of footage, I did the entire composite on the ‘double-bouble’ source footage. Since Samsung Gear 360’s software only wants to stitch SOOC video, I had to export both ‘bubbles’ and stitch with autopano video (which explains the watermarks).
If nothing else, this taught me to film as little extra footage as possible for the sake of processing time later.
For the final project, I thus settled on: Static Camera, myself in the video (to interact with the cat), daytime/window light, and a flat documentary aesthetic. Results above.






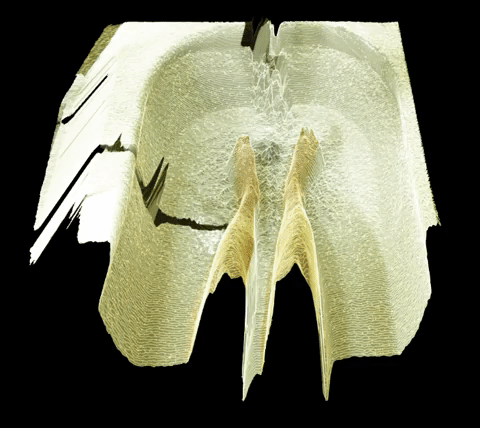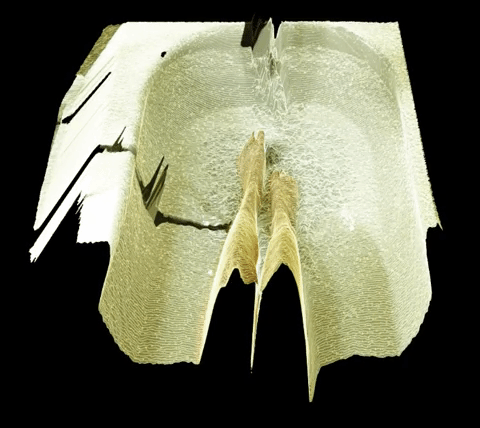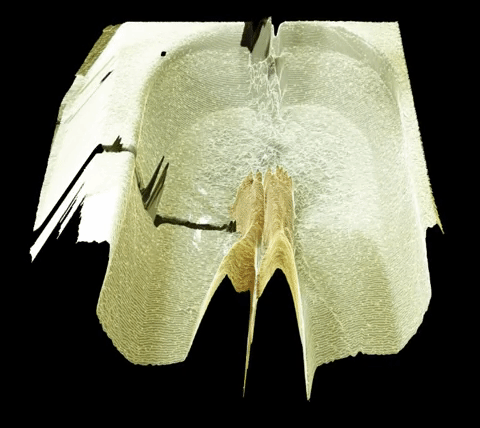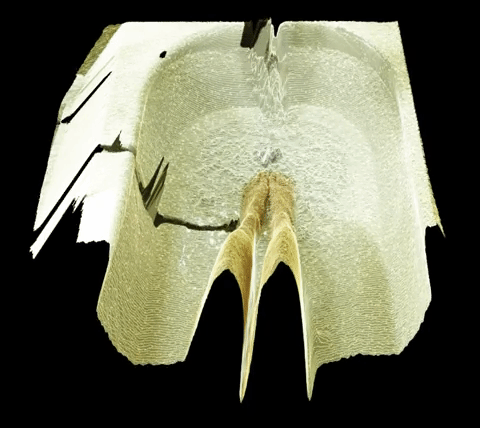






















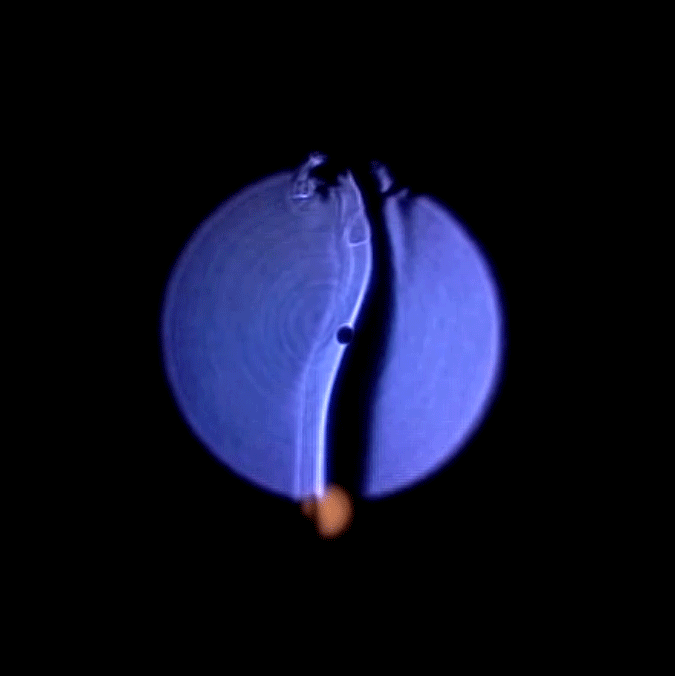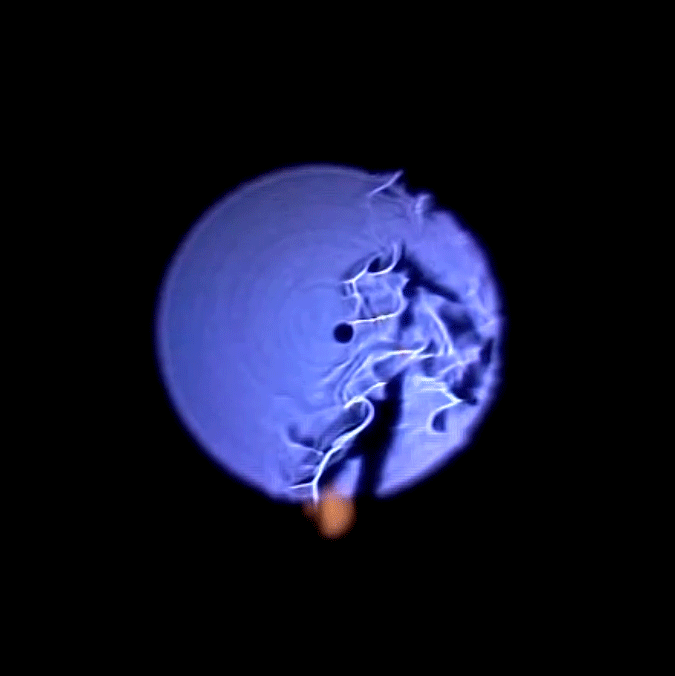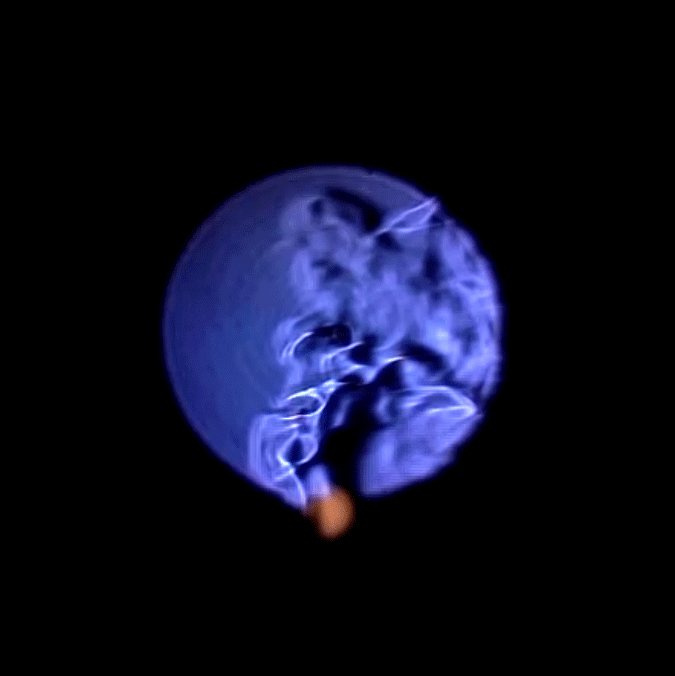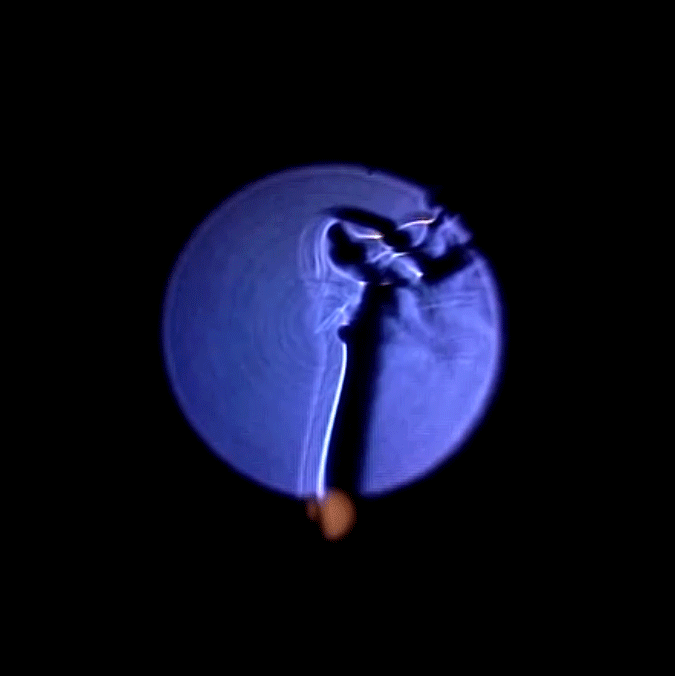
 The first part of the setup would consist in having a ball launcher throwing balls that would follow a consistent trajectory.
The first part of the setup would consist in having a ball launcher throwing balls that would follow a consistent trajectory.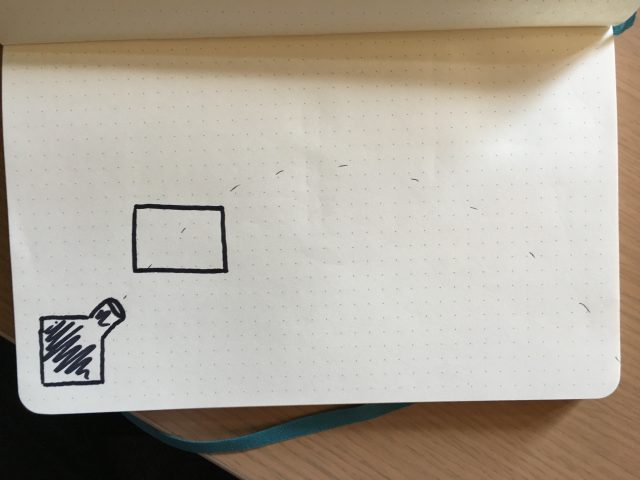 I would then put a camera on the robot arm.
I would then put a camera on the robot arm.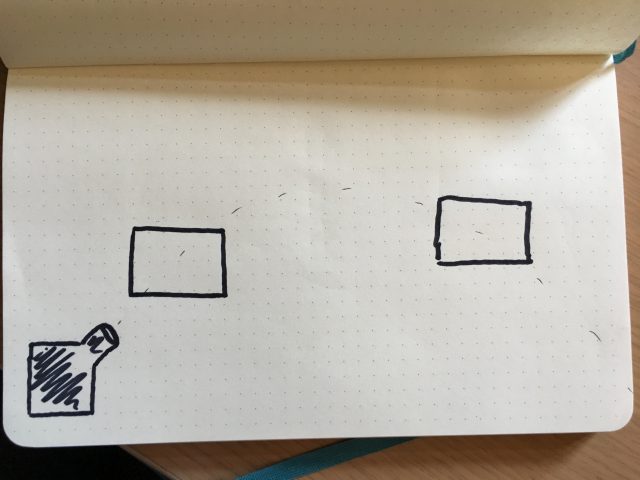 I will have the robot arm move in a loop that would follow the trajectory of the balls.
I will have the robot arm move in a loop that would follow the trajectory of the balls.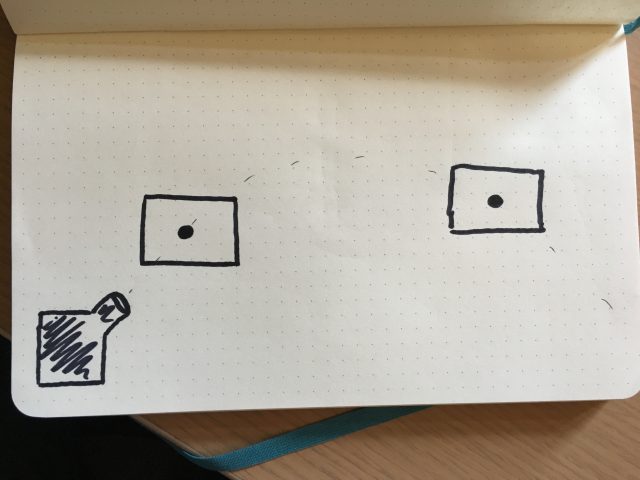 I would then throw a ball with the launcher. The robot (and camera) would follow the ball and keep it in the center of the frame.
I would then throw a ball with the launcher. The robot (and camera) would follow the ball and keep it in the center of the frame.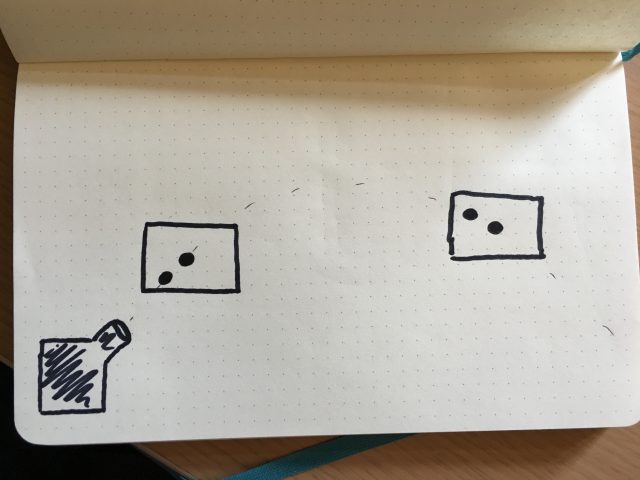 The robot would start another loop and another ball would be thrown, but with a slight delay compared to the time before. The ball followed would then appear to be slightly off the center of the frame.
The robot would start another loop and another ball would be thrown, but with a slight delay compared to the time before. The ball followed would then appear to be slightly off the center of the frame.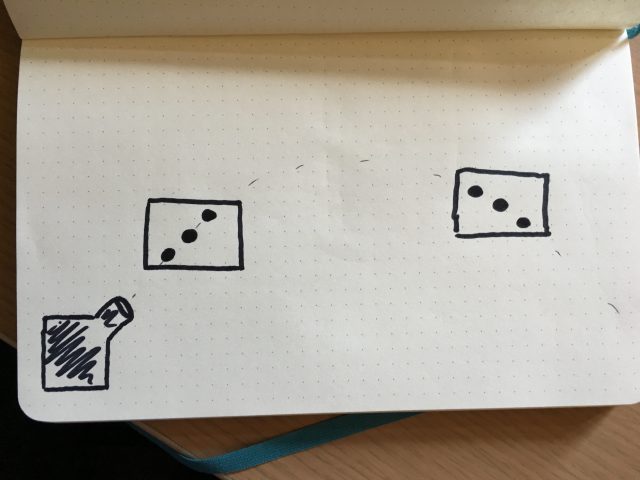 Repeating the process and blending the different footages would do the trick and the whole trajectory would appear to move dynamically.
Repeating the process and blending the different footages would do the trick and the whole trajectory would appear to move dynamically. My trouble began when I started programming with the robot. Managing to control such a machine implies writing in a custom language, using inflexible functions, with mechanical constraints that don’t allow to move the robot smoothly along a defined path. Moreover, the robot has a speed limit that it cannot go past and the balls were going faster than this limit.
My trouble began when I started programming with the robot. Managing to control such a machine implies writing in a custom language, using inflexible functions, with mechanical constraints that don’t allow to move the robot smoothly along a defined path. Moreover, the robot has a speed limit that it cannot go past and the balls were going faster than this limit. For the launcher, I opted for an automatic pitching machine for kids. It was cheap, but probably too cheap. The time span between each throw was inconsistent and the force applied for each throw was also inconsistent. But now that I had it I had to work with this machine.
For the launcher, I opted for an automatic pitching machine for kids. It was cheap, but probably too cheap. The time span between each throw was inconsistent and the force applied for each throw was also inconsistent. But now that I had it I had to work with this machine.




 And here is what the scene looked like from a different point of view.
And here is what the scene looked like from a different point of view.