Superboneworld
A system transcribing people into skeletons, hanging out.
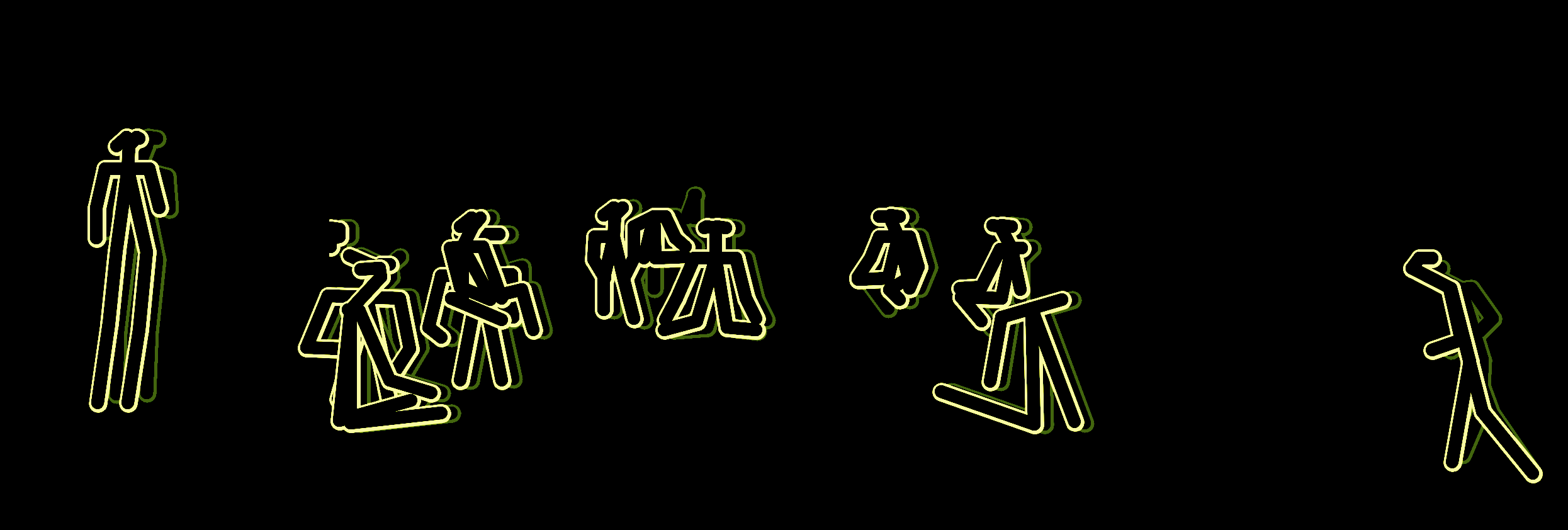
?
Superboneworld† is a system that extracts and visualises human pose-skeletons†† from video. This extracted information is then displayed in a scrolling, ticker-like format on a 4:1 display. As Superboneworld scrolls past us, we see different strands of human activity — dancing, walking, yoga, pole dancing, parkour, running, talent-showing — overlaid, combined and juxtaposed. When we reach the end of the pose-ticker, we loop back to the start, seeing the next slice of Superboneworld†††.
I wanted to explore the commonalities and contrasts within and across certain forms of human movement. I was interested in putting in one 'world' myriad different people moving about in myriad different ways.
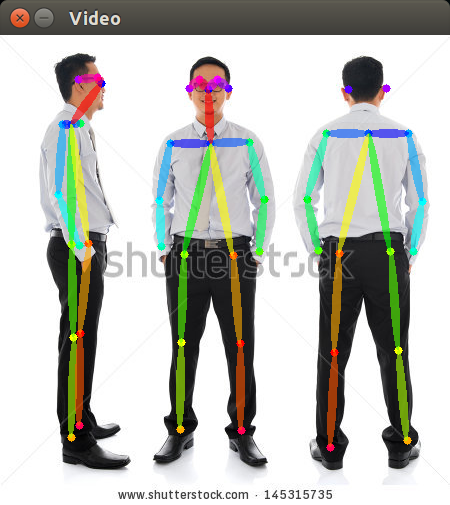
The capture system consisted of a neural network, the same one as the one used in pose-world, that extracts4 pose information from video.
This system was fed a large number of videos ripped from the internet, ranging in 0.5-10 minutes in length.
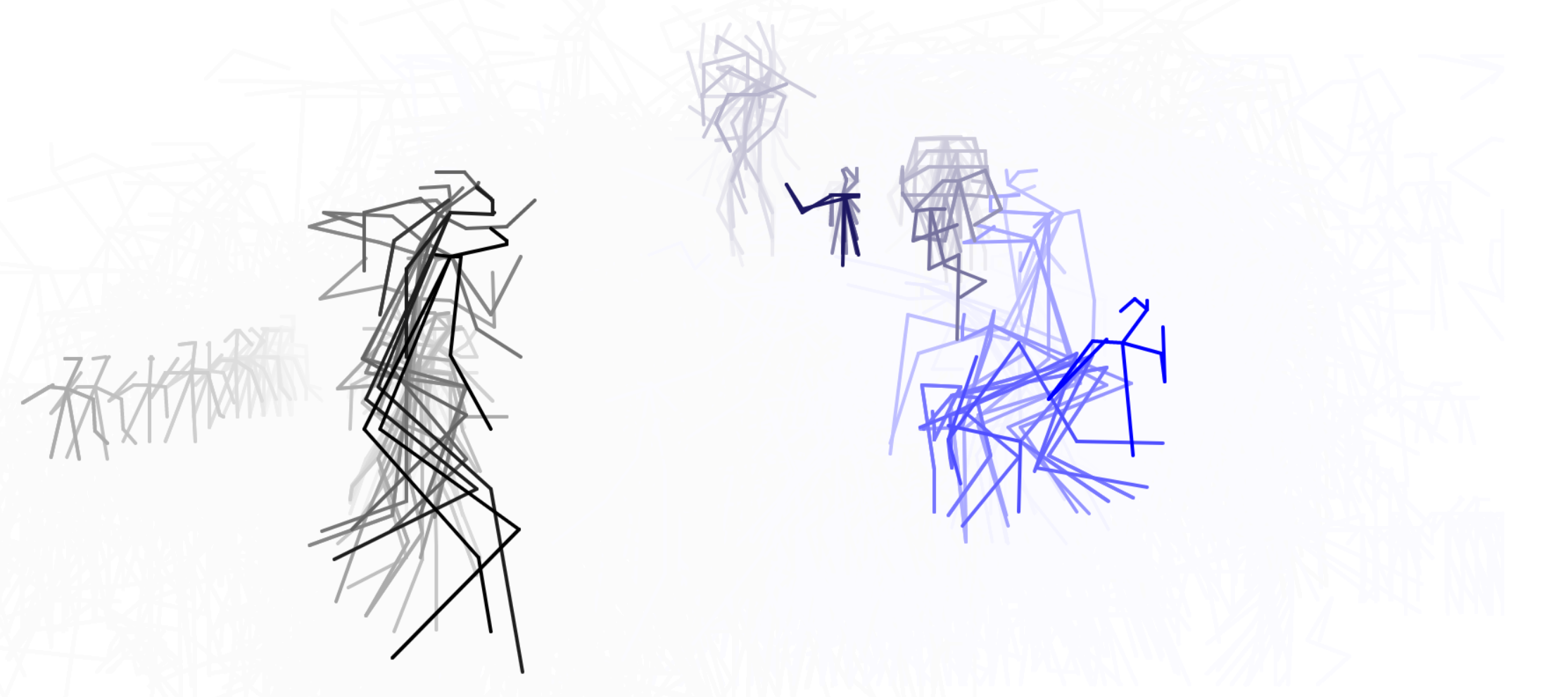
This gave me frame-by-frame knowledge5 of the poses of people within the video. I then visualise this by drawing all the pose information I have for all of the skeletons (i.e, in the above image, the missing left forearm of the leftmost skeleton (most likely) means that the neural network was unable to recognise it from the image.
Each video stays static relative to Superboneworld (we are moving across it), so each video produces a Bonecommunity of skeletons moving around over time, i.e a 'pose-video'. Certain Bonecommunities are drawn in a different colour because it looked nicer that way. As a Bonecommunity scrolls out of view, it is frozen in time till we get round to it again.
notes
† significant portion of credit for name goes to claire hentschker
†† a pose-skeleton is a 'skeleton' that describes the pose of a person, such as where their joints are located and how to connect those joints up to reconstruct their pose
††† the 'pose-videos' ('Bonecommunity') only play when they are being displayed — after we have scrolled past one, the skeletons are frozen till it next comes back round, so each time we go around Superboneworld, we see a little more of each little 'Bonecommunity'
4 given an image containing people, it tells me where the limbs are located (within the image), and which limbs belong to which people.
5 the computer's best guess
process !
neural
I first experimented with this neural network system for my event project, pose flatland (open sourced as pose-world).
The structure of the neural network did not change much from pose flatland, the primary changes being me optimising it to run faster while I was thinking about what to actually capture. The optimisation mostly consisted of moving calculations from the CPU (previously using OpenCV) to be done on the GPU by translating them into PyTorch.
I also modified the system such that it could process and produce arbitrarily large output without having to resize images to be small and square.
After getting to a state where I could reasonably process a lot of videos in a short amount of time (each frame took ~0.08 to 0.2 seconds to process, so each video takes 2-10x its length to process, depending on the number of computer-confusing people-like things in it and number of people in it).
I first experimented with parkour videos, and how to arrange them. At this stage, the viewpoint was static and pose-videos were overlaid, which was initially confusing and all-over-the-place to look at.
After striking upon the idea to use the superlong 4:1 display lying around the STUDIO, I also decided to directly to more directly interrogate the expression in videos on the internet. Before this, I was unsure if moving on from the live webcams (as used in pose flatland was a good idea, but after seeing a number of outputs from various popular trap music videos, I was convinced that it was a good idea to move in the direction of using videos on the internet.
The majority of the videos I used could be considered 'pop-culture', for some value of 'culture' & 'pop' — they were mostly all popular within the genres they embodied. For instance, one of the videos is the music video for Migos' seminal track Bad and Bougee, and another is the very important 21 Savage/Metro Boomin track X. For the videos from genres that I am less knowledgeable about, such as parkour or yoga, I choose videos that would generally showed most of people's bodies most of the time, and were somewhat popular on Youtube.
As a refresher, here is the output of the neural network directly drawn atop the image that was processed:

Here are some images for the earlier, parkour iterations:


Note the various flips and flying around:


I realised by pressing Ctrl-Alt-Cmd-8 I could significantly improve the quality of the media artifact by inverting my screen:

media object
After downloading and processing the videos, I set about arranging them. I mostly did this blind, by writing a JSON file describing where each 'pose-video' should be placed on Superboneworld. I then wrote a small p5js script that downloaded the pose-video, placed it in the correct location (for most of them, initially far, far offscreen), and then slowly scrolled across Superboneworld, taking care to pause and unpause the Bonecommunities as they came into view.
Whilst building this visualisation, I realised that they would look better drawn as blobs rather than stick figures, as they have significantly more dimensionality, and their ordering atop each other (a Bonecommunity has a z-ordering).
After this, I loaded up a webpage containing the p5js script, plugged my computer into the 4:1 screen in the STUDIO, and showed it.
Here is an image from the exhibition:

Here are some GIFs:
similar work made in the past
Golan Levin's Ghost Pole Propogator is the most visually and conceptually similar project, although I did not really notice the similarity till after making pose flatland.
Here is the best documentation of it I could find:
source code
The neural network modifications and javascript visualisers have been merged into pose-world. Look at it for instructions for how to process your own video.
The piece is available to be viewed at bad-data.com/superboneworld. It streams ~100 mb of data to your computer, so it may be a little slow to load. However, after loading it caches all the downloaded data so subsequent runs are fast.
thanks to:
- Claire Hentschker for significant help in the conceptual development of this project
- Zhe Cao, Tomas Simon, Shih-En Wei, Yaser Sheikh, for doing the research and releasing an implementation that made this possible
- tensorboy for the re-implementation of the above research in an easy to extend way
- All the other artists in Experimental Capture who thought this project was cool and helped me make it better
- &
- Golan Levin for this class!