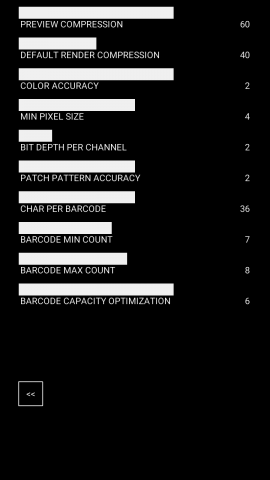
As many of you know, I decided to explore ground penetrating radar heavily this semester. I have been interested in geology combining with artwork for quite a while, although I’m not completely sure why. A lot of my art has to do with stratospheres of soil/minerals and their makeup. Although this is primarily a tool for archeology and civil engineering/construction, I found it gave me some really cool data.
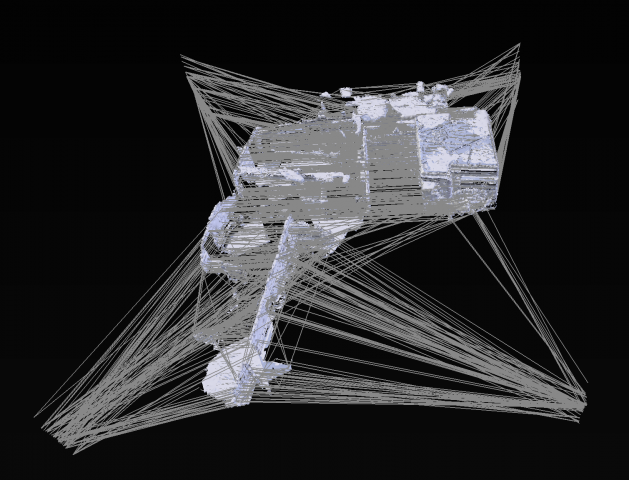
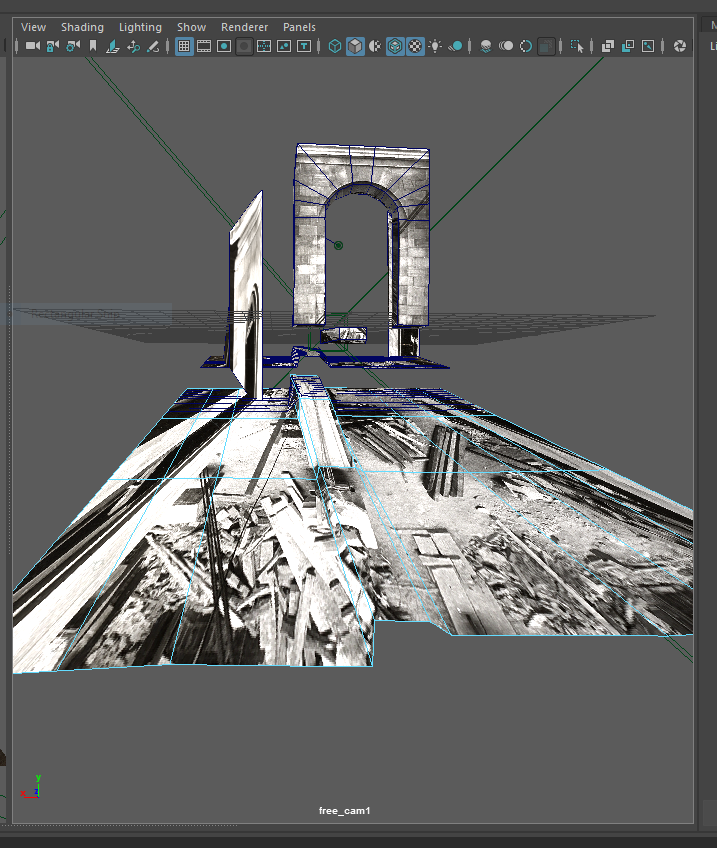
I started with the idea that I was going to go to a graveyard to get scans of graves to turn into music (in the process of being set up with GeoSpatial). Golan was kind of enough to get GeoSpatial to come to CMU campus though, and I decided to look for some of images/things on the campus that most people never see. Definitely by far the coolest thing was the hidden artwork Translocation by Magdalena Jetelová. This was an underground room that was put underneath the cut in 1991. I talked with the lovely Martin Aurand (architectural archivist of CMU) who told me some of the stories about this piece. In the late 80s/early 90s, a CMU architecture professor that was beloved by many of the staff had died in a plane crash on her way to Paris. To honor her, the artist Magdalena Jetelová created a room beneath the cut in a shipping container, with lights and a partition. There was a large piece of acrylic on top of it so that you could actually walk around on top of it. This artwork was buried somewhere around 2004 however, as water had started to leak in and ruin the drywall/fog the acrylic. Most people on campus don’t know that it exists. We were lucky enough to get a scan of this area which went in a grid-like pattern so that I can turn it into an isosurface rendering (more on this later). 



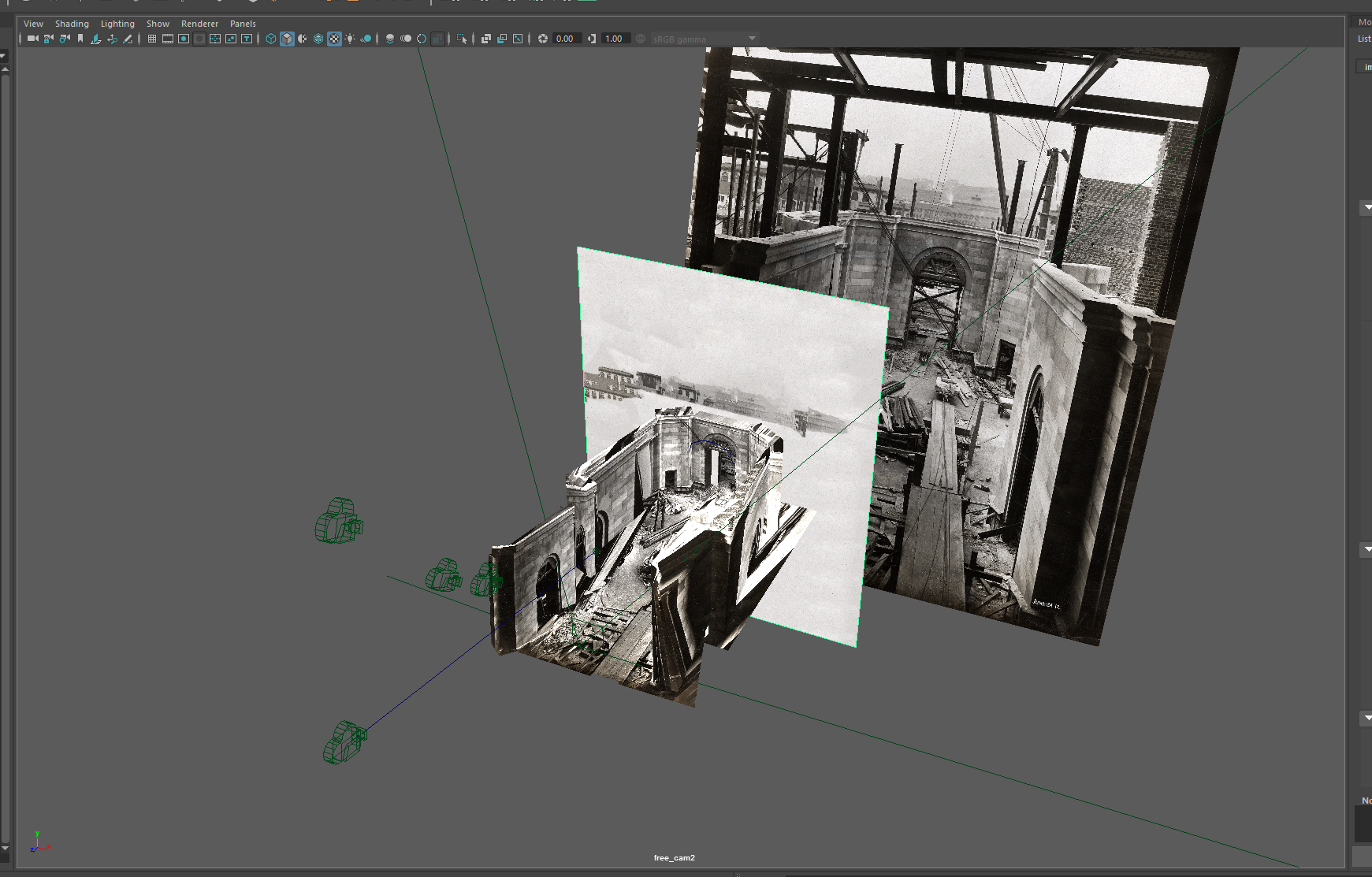
Another area that I wanted to explore was the area by Hunt Library now known as the peace garden. This used to be a building called Langley Laboratory (although this was often labeled Commons on maps). I went and visited Julia Corrin, one of the other archivists on campus to look through the archives to find old pictures of CMU. One part of Langley Laboratory in particular caught my eye as it was a small portion that jutted off the end that appeared in no photographs except the aerial photos and plans. Julia did not actually know what that part of the building was for and asked me to explore it. After looking through the GPR data, I don’t believe any remnants of it remained. It is likely that the building’s foundation was temporary/were completely removed for the creation of Hunt Library.
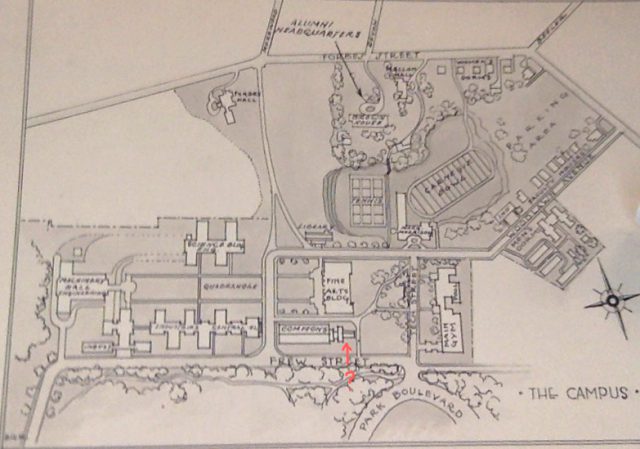
The last big area I wanted to explore was the Number Garden behind CFA. This area was interesting particularly because Purnell Center is immediately below it. This was particularly interesting to scan as we could see the ways that the underground ceiling sloped beneath the ground we were walking on/the random pipes and electrical things that were between the sidewalk and the ceiling.
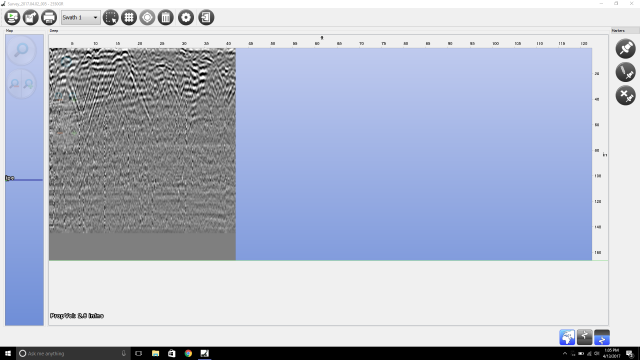
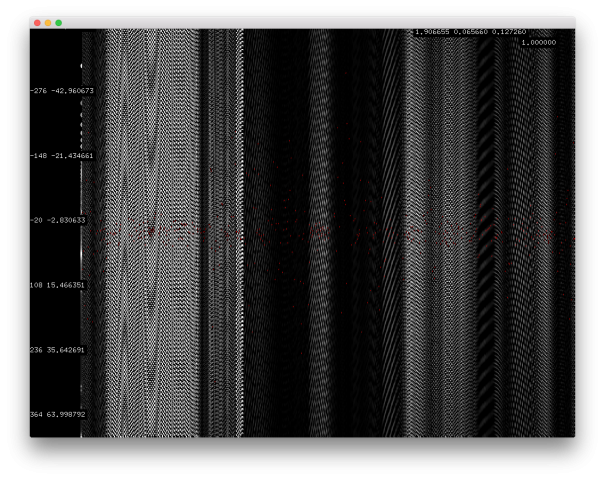
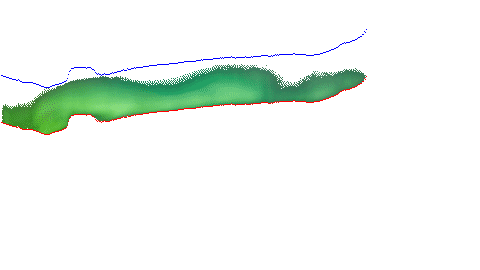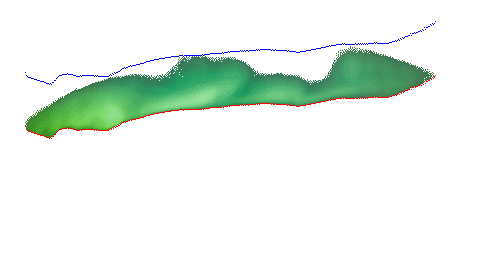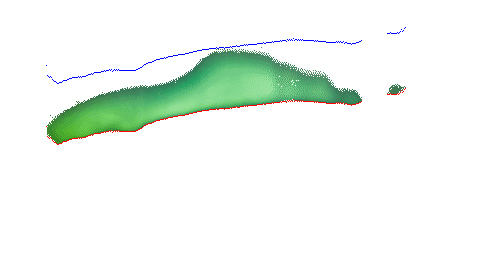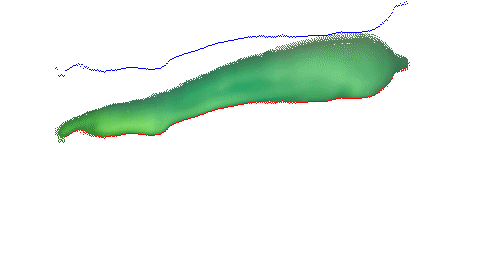
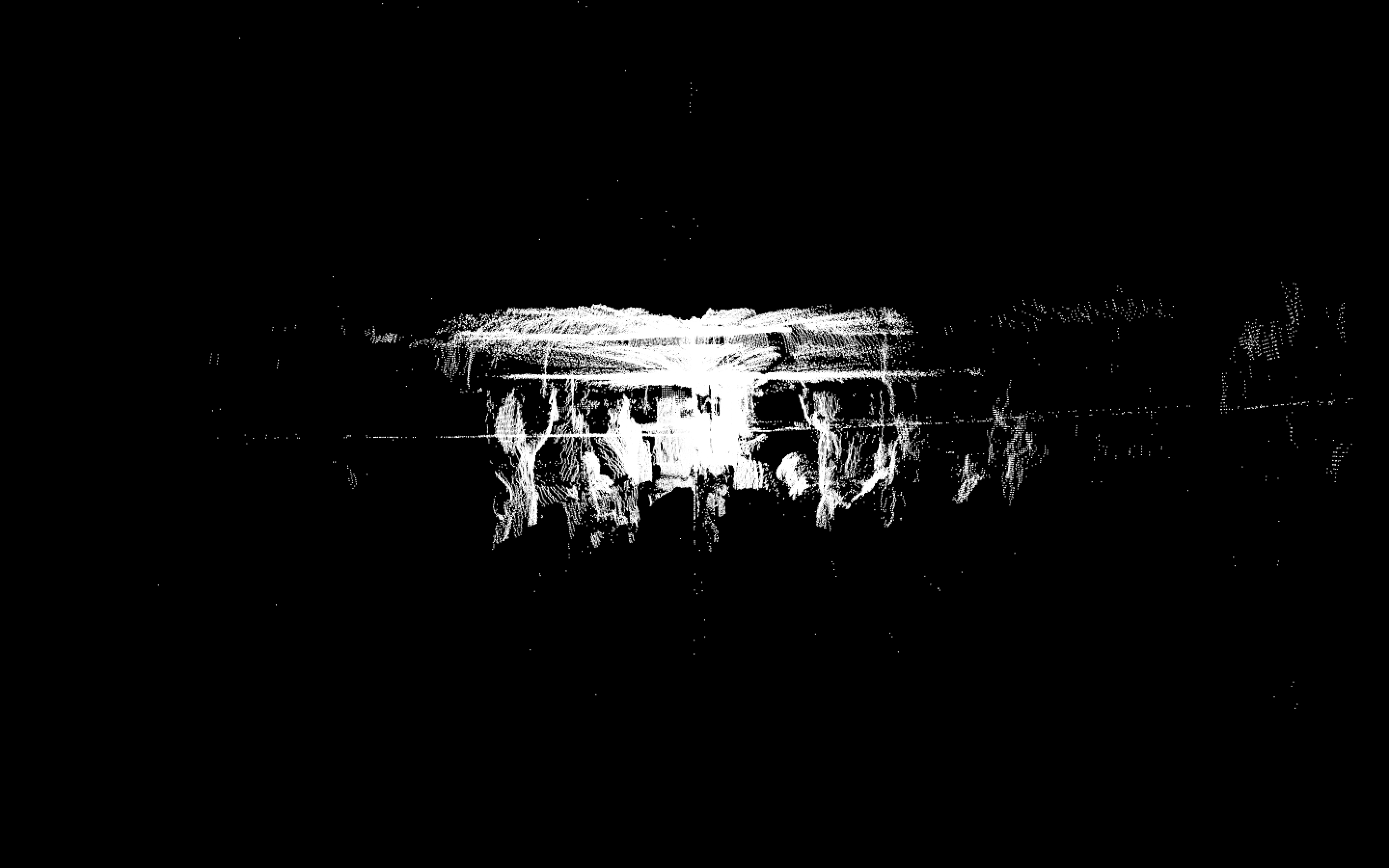
I also did a lot of research on how GPR works, particularly on the hardware portion and what antennas to use etc. A short description is GPR works basically by reflecting pulses of radar energy that are produced on a surface antenna. This then creates wavelengths that go outward into the ground. If an object is below ground, it will bounce off that instead of merely the ground, and will travel back to the receiving antenna at a different time (in nanoseconds). There are 2 main important types of GPR images. The first thing is a reflection profile. This is the long image that you do an immediate scan. This will show the bumps in the ground and look like this:
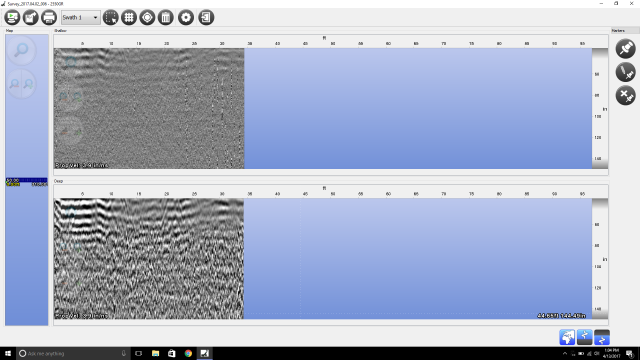
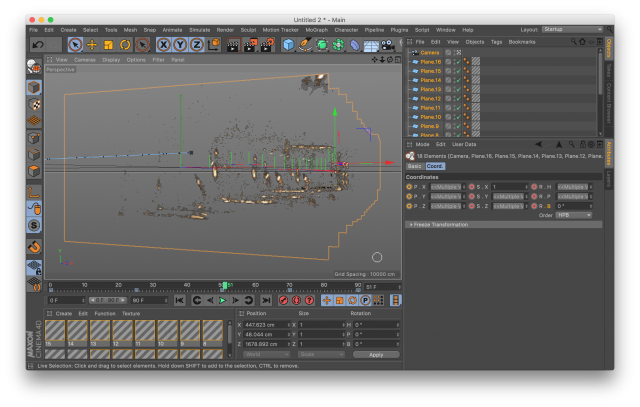
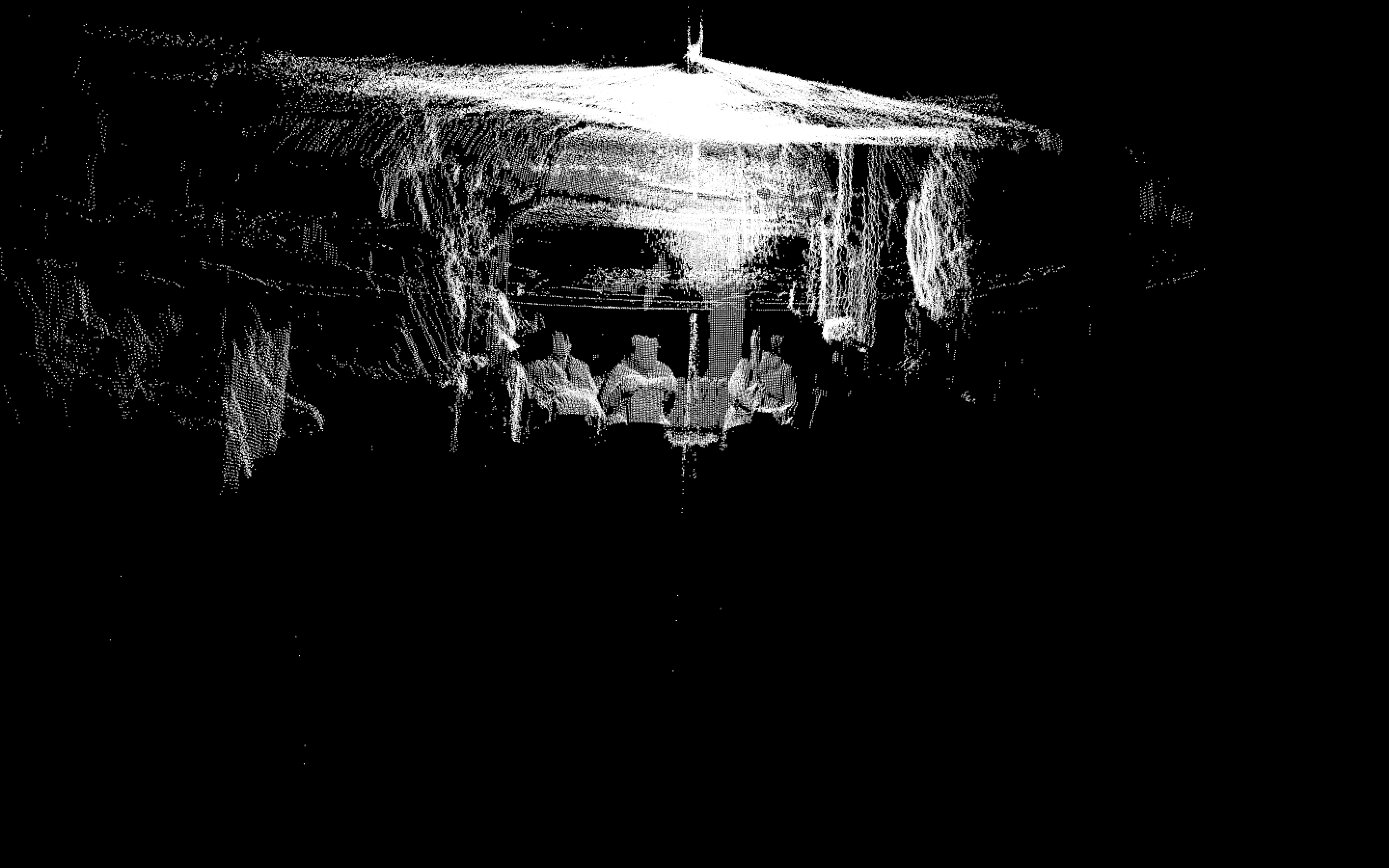
The next is an isosurface rendering. This is basically what happens if you get a lot of scans in a grid. If you line up a bunch of the scans, you essentially get horizontal slicing of what you can turn into a 3D model. This looks something more like this:
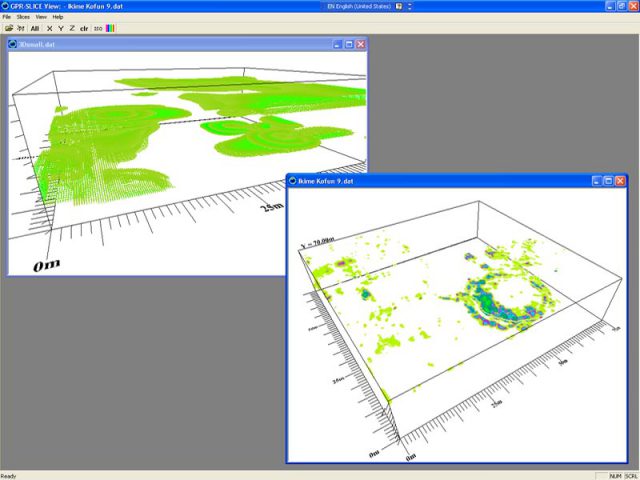
In some ways, as far as events, my event was helping to get GeoSpatial involved, doing research to find interesting places to go to, learning a lot about GPR to ask educated questions, and then having the day that we scanned. The act of scanning itself is an event which can also be captured.
Because the data was slightly difficult to read at first (Thank you Golan for going through it with me through strange photoshop raw files with guessing bits) and getting very sick, I am slightly more behind than I would like. I have the data and will be meeting with Jesse Styles on Tuesday to get opinions on how I could turn this into a 3D soundscape. This is a very difficult project for me because it is big, involves people outside of CMU, and every part of it is completely out of my normal wheel-house. My next big difficulty is going to be learning how to synthesize this into sound, as I very rarely work with it. I feel like I am still learning a lot throughout this though. I really want to thank GeoSpatial for being so kind and sharing their time and software with us!
Golan also showed me this super cool artwork made by Benedikt Gross in which he uses computational tractors to create enormous earthworks. These tractors/bulldozers can be programmed to go in set patterns and can act like a 3D printer/CNC router! 

If you are interested in seeing any of the raw data, reach out to me. I cannot unfortunately share the SubSite software as Google Drive will only allow me to share it with people at GeoSpatial.





























































 ->
->














 Finally I used a 7×7 grid to find the closest 49 pictures in the TSNE grid from a given image (ideally the image that I take), and put these batch of pictures into Autopano.
Finally I used a 7×7 grid to find the closest 49 pictures in the TSNE grid from a given image (ideally the image that I take), and put these batch of pictures into Autopano.