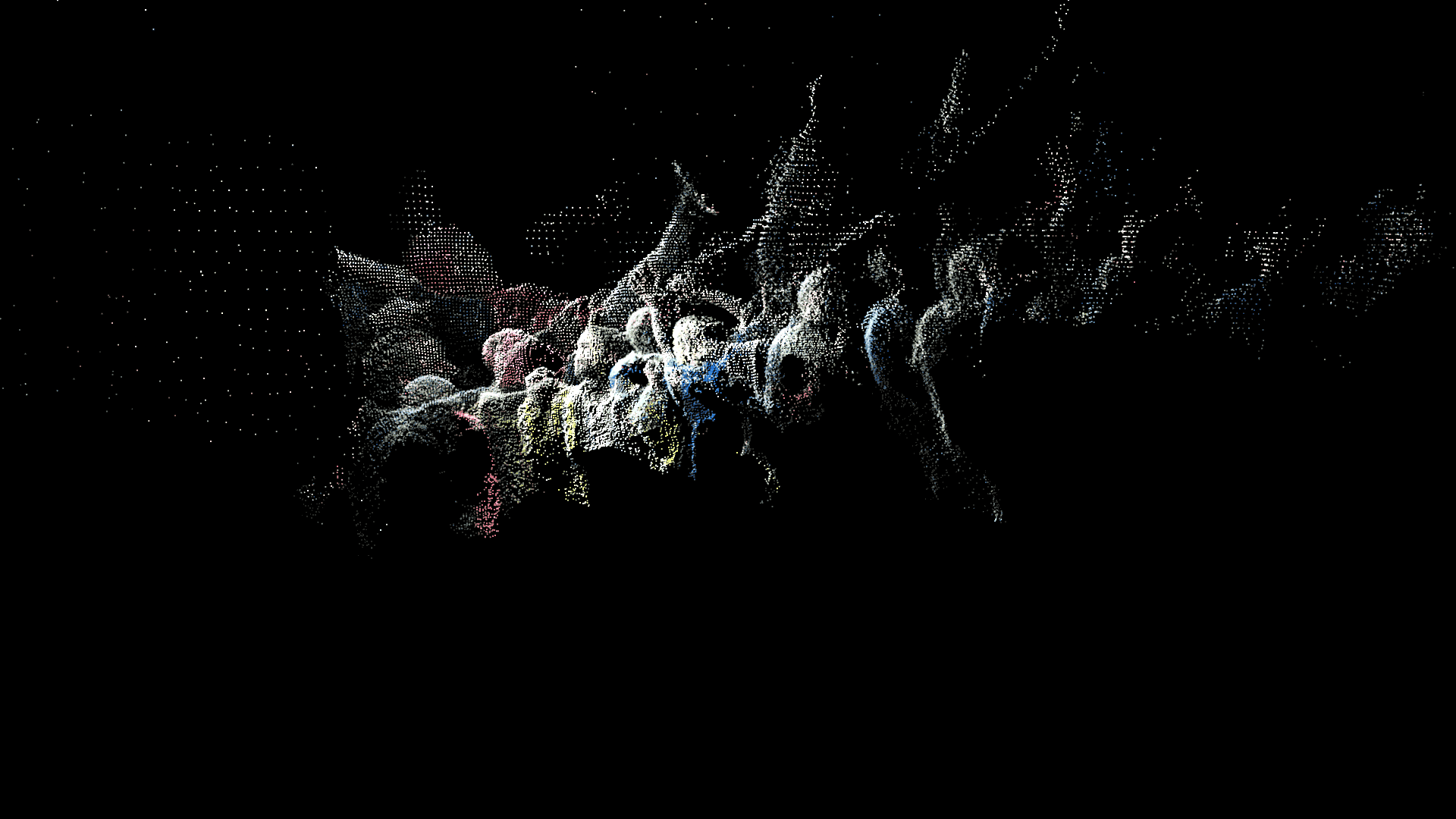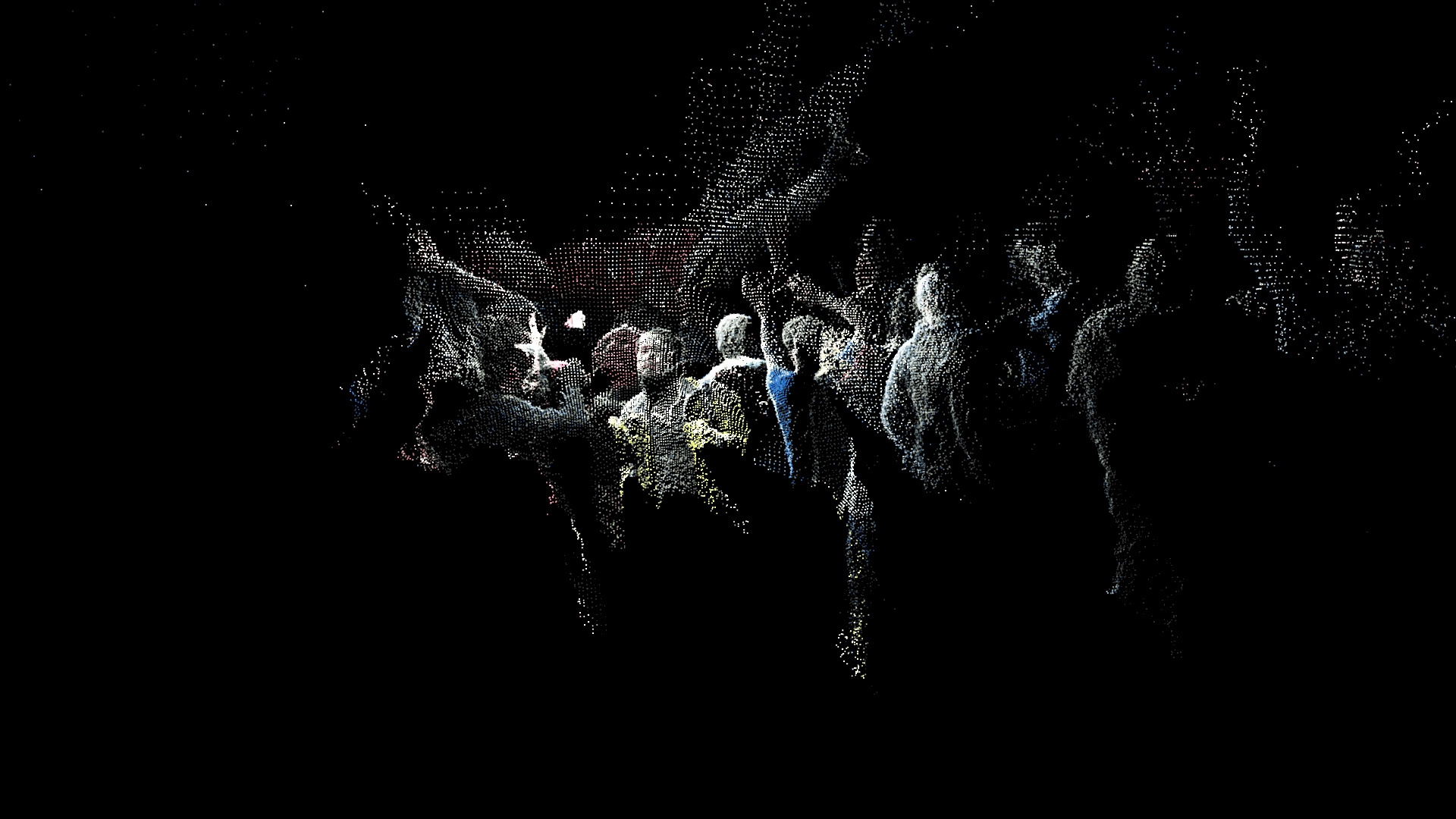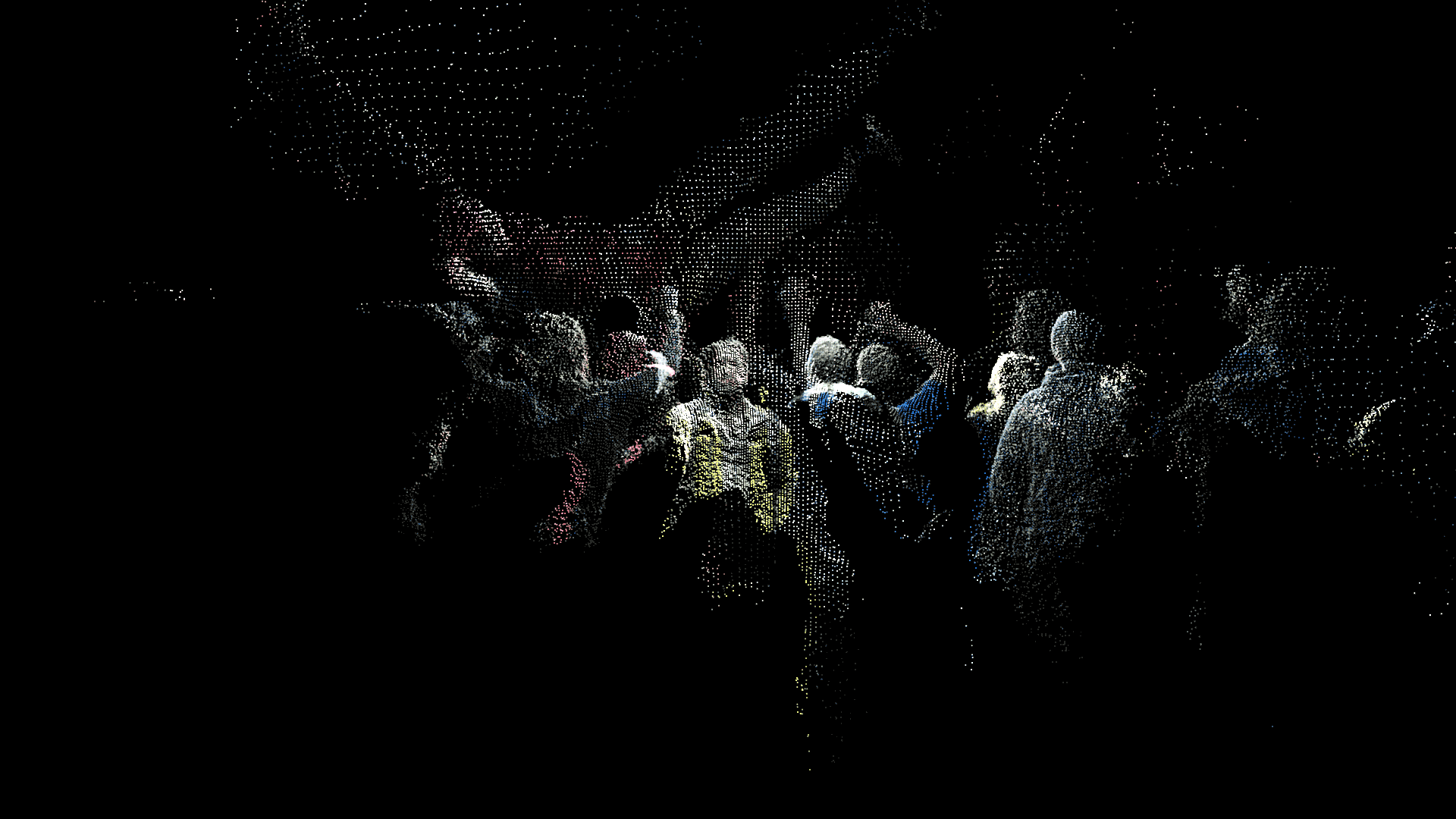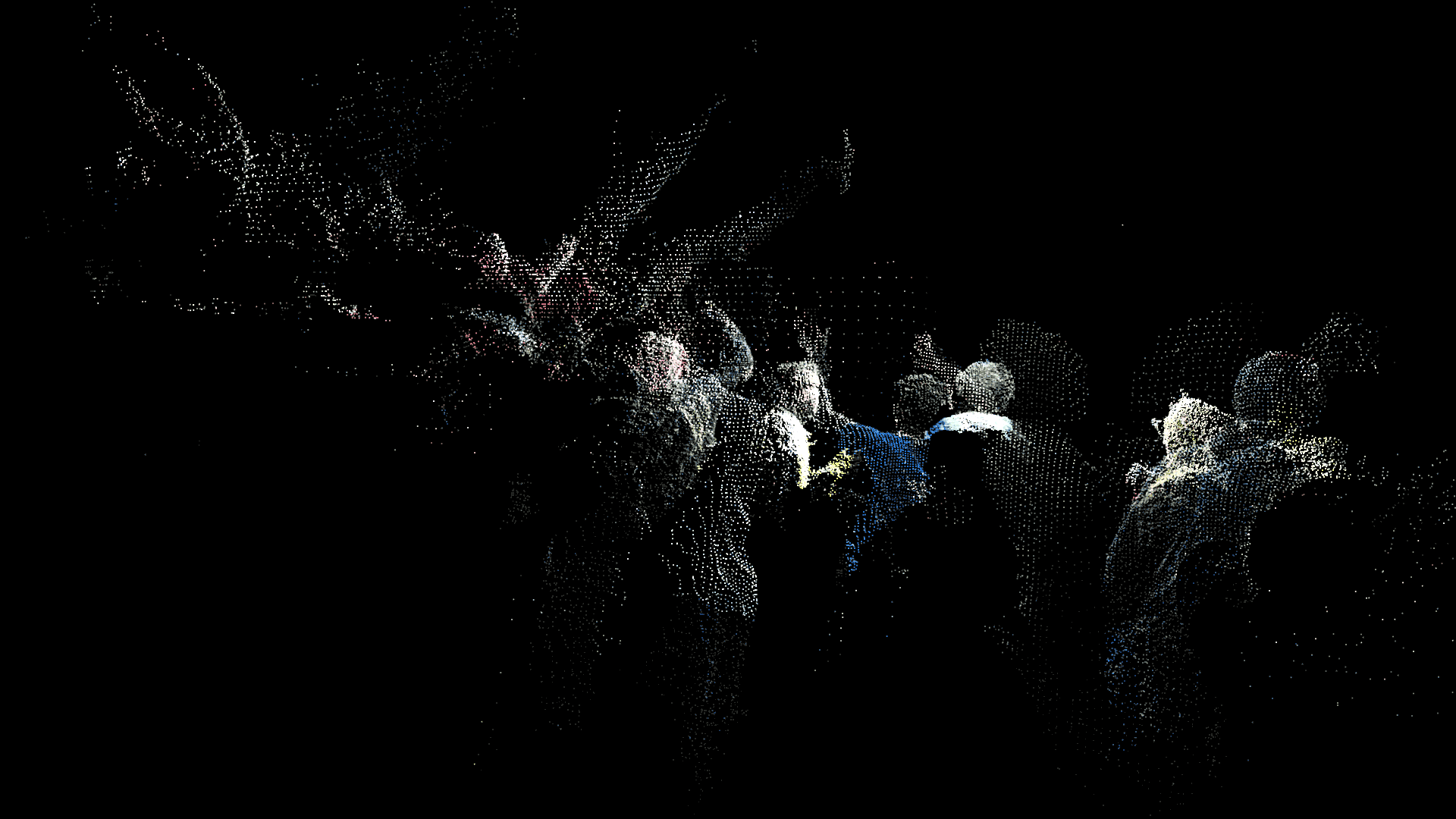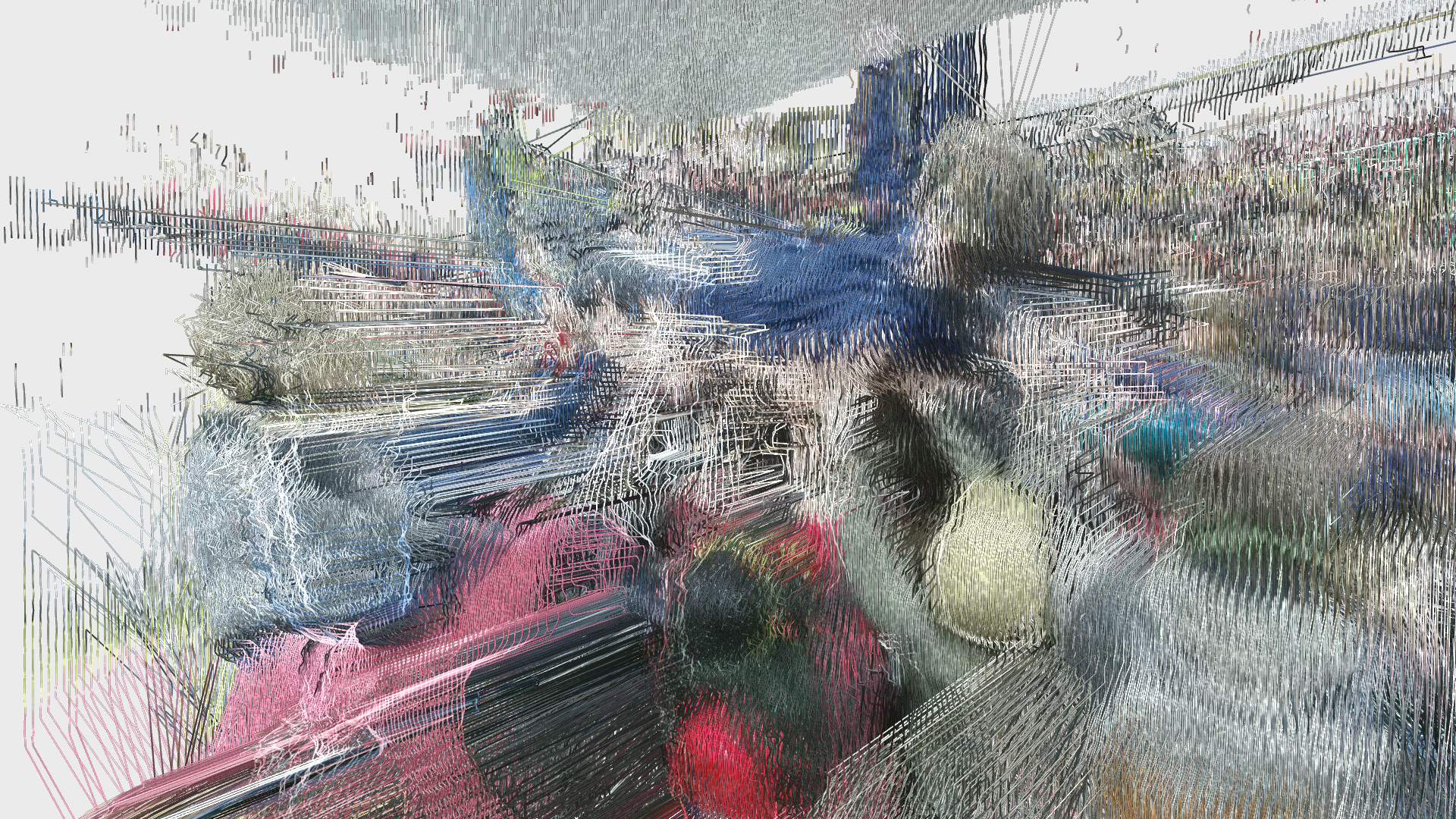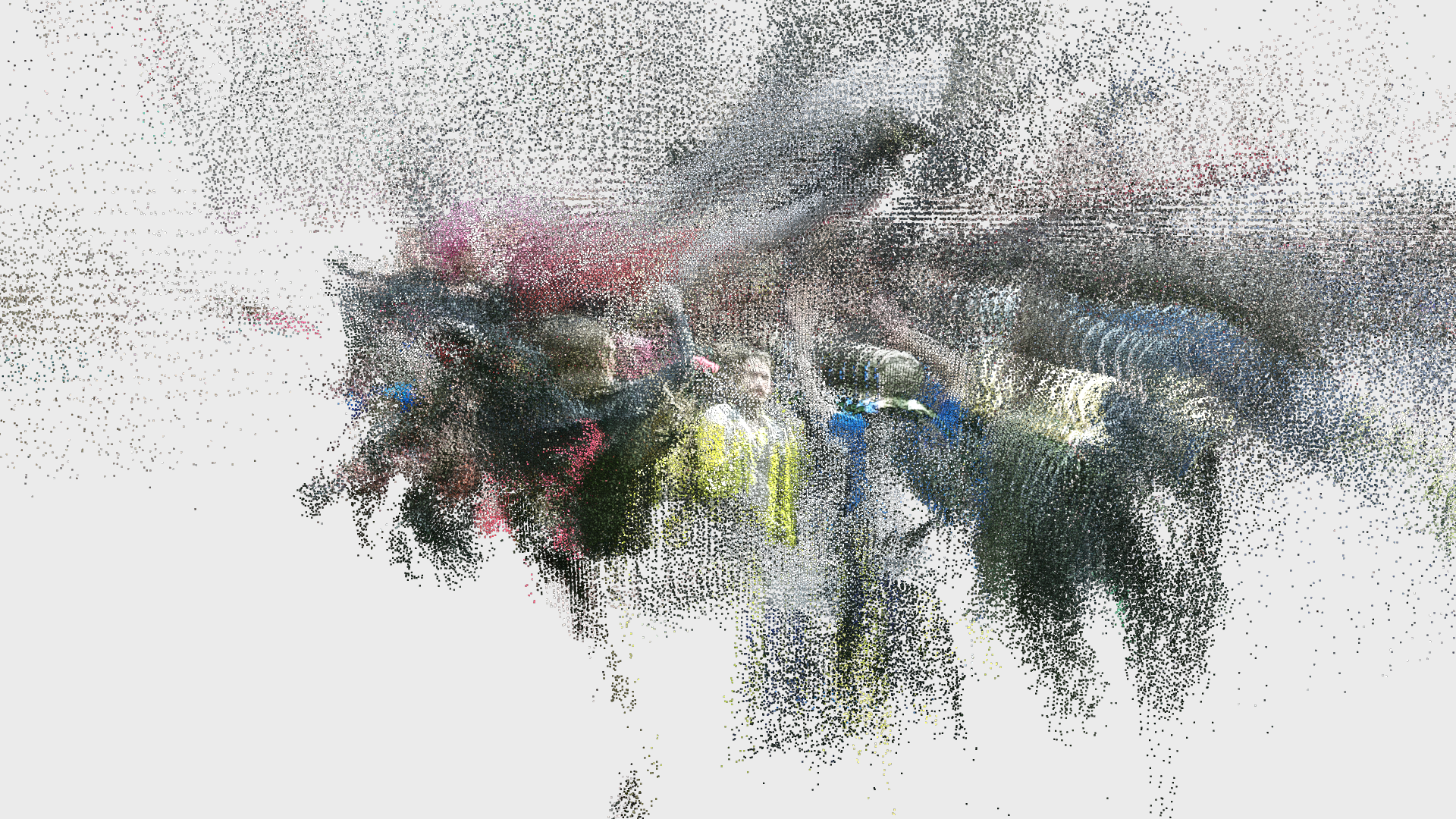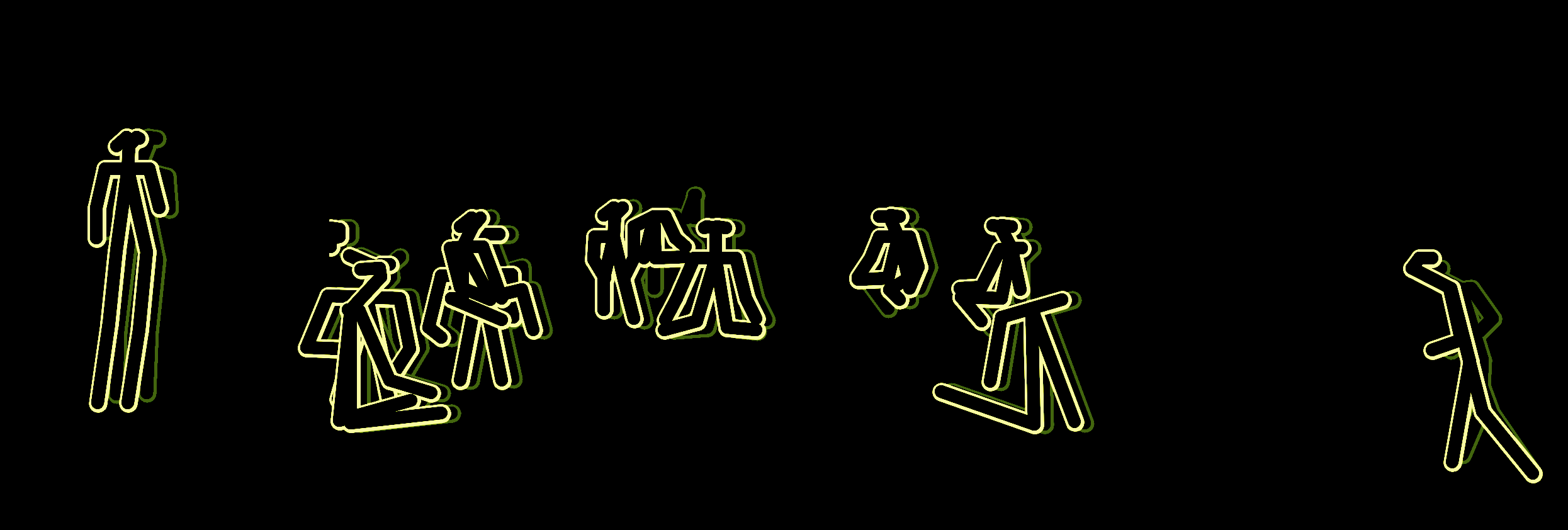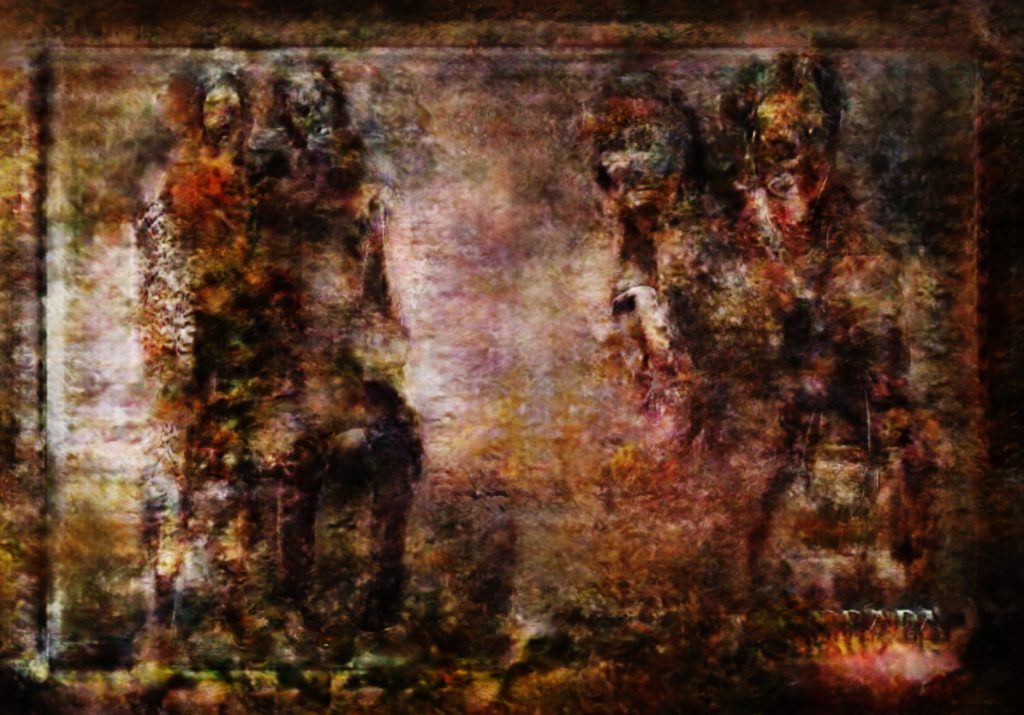body, my body is both the title of my final project, and a song by the Pittsburgh-based dance/music duo, slowdanger, for which I’ve made the music video, in addition to a VR dance piece.
For much of the semester, I’ve been working with as many methods of motion capture as I could get access to. At Carnegie Mellon, I’m fortunate enough to have at my fingertips multiple motion capture research labs, as well as many other methods for capturing bodies in space and motion. I began to collaborate with slowdanger in March, as we are collectively interested in sensory perception, kinesthetic experience and understanding, and ways to imbue and express feelings of embodiment in visual, digital, and mixed reality experiences. This project has allowed me to further investigate my core research questions of human perception, representation, and communication within experiences with evolving technology – specifically focused on the notion of embodiment, as experienced by a performer and translated to (sensed by, interacted with, responded to by) a user/audience/witness.
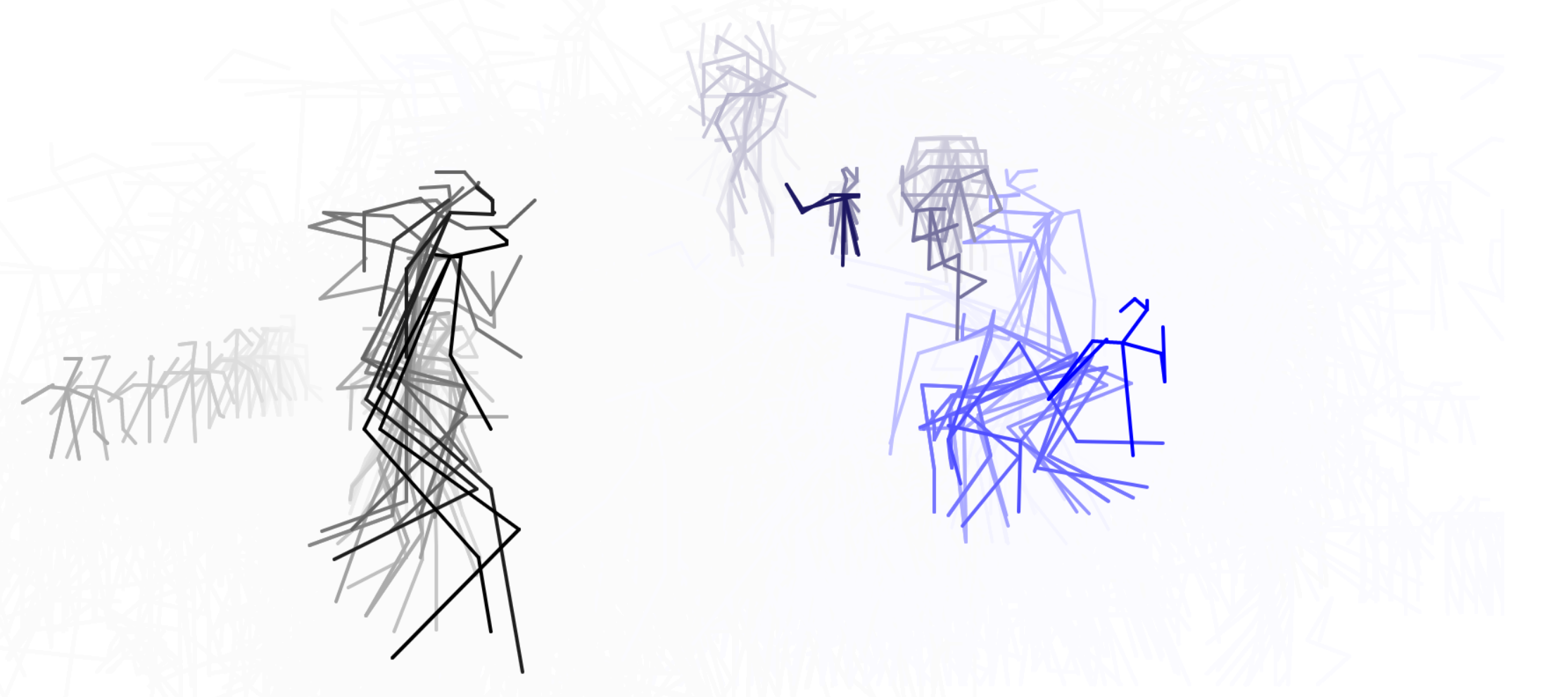
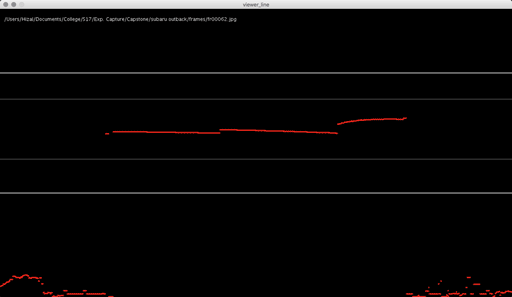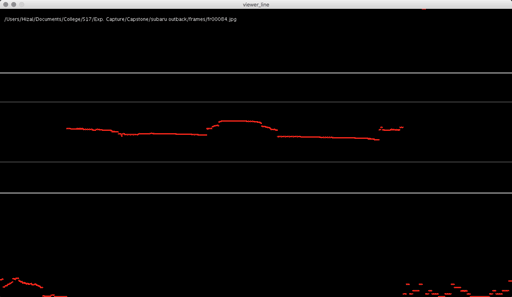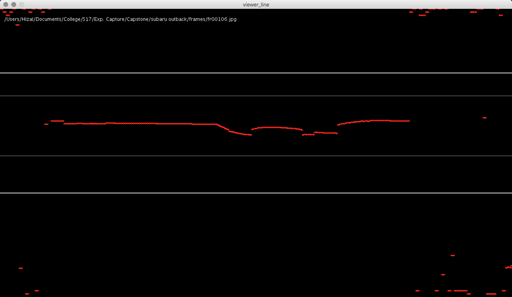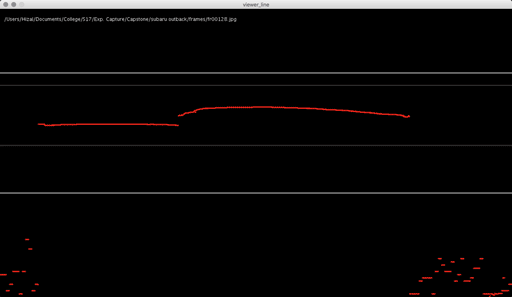
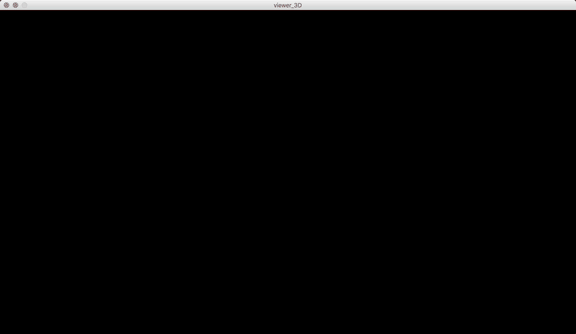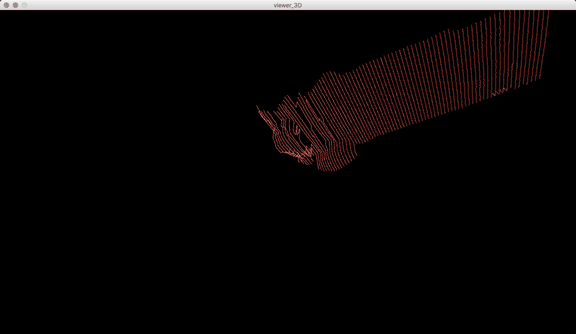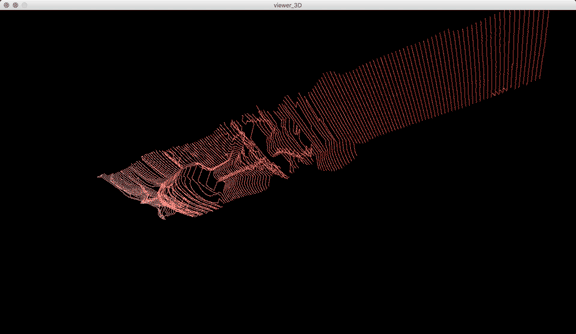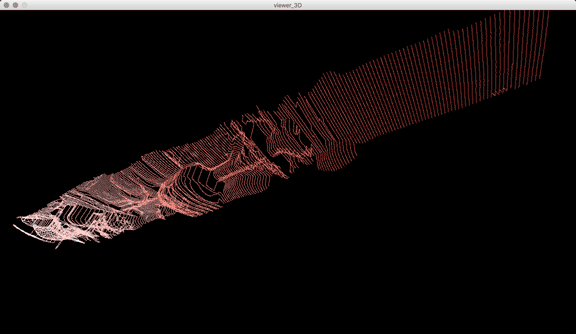
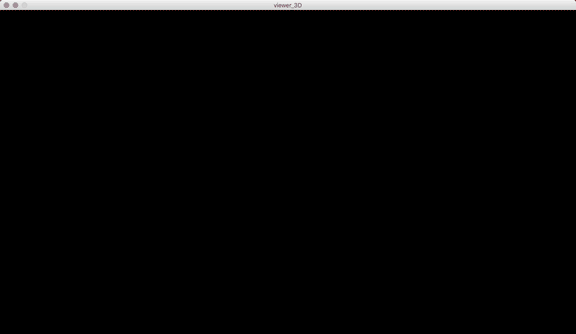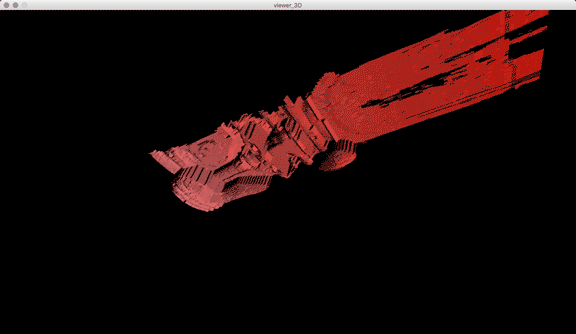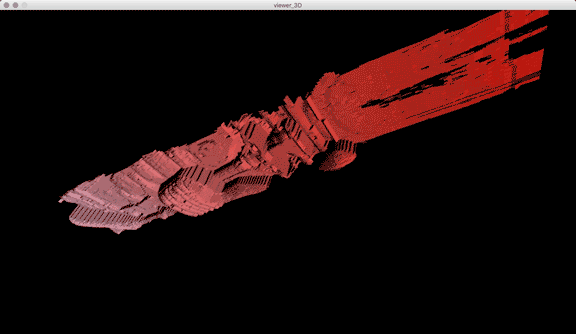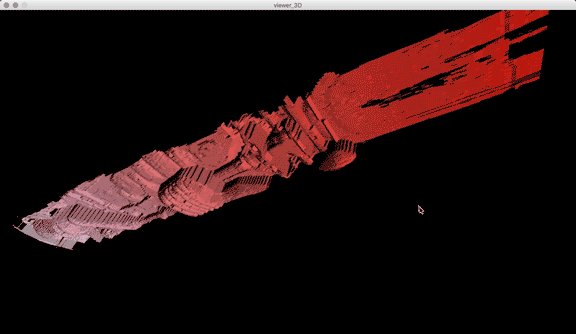
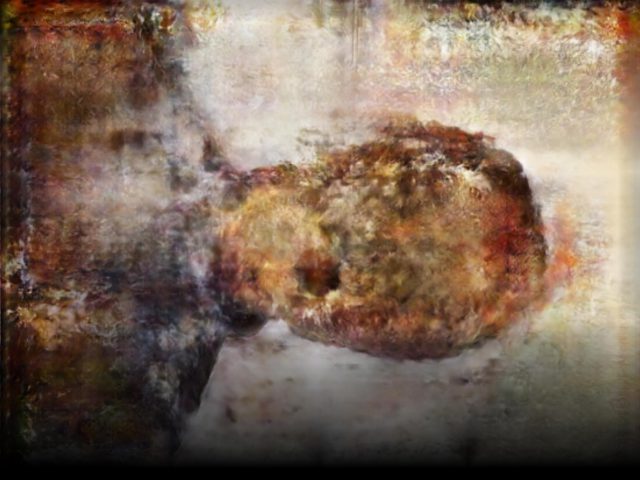
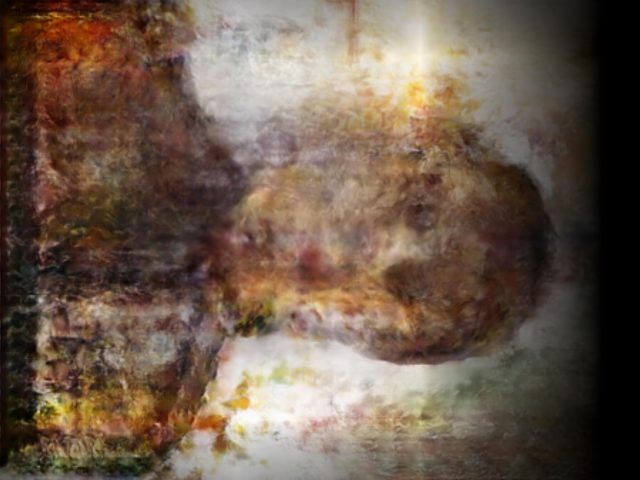
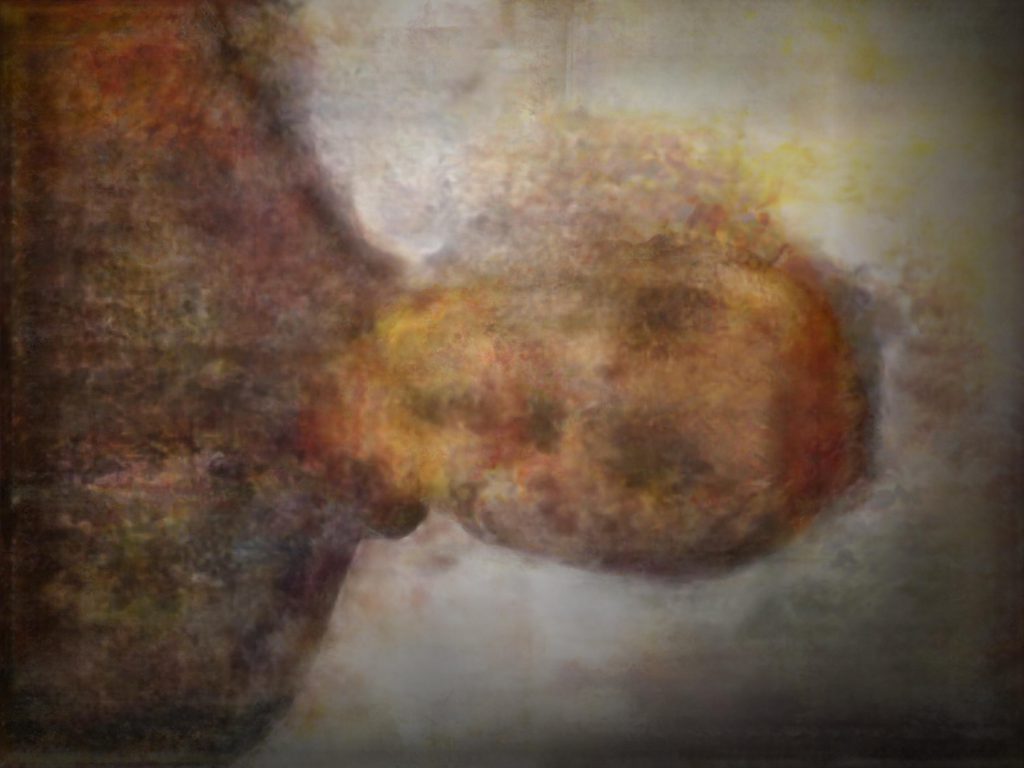
In addition to these conceptual questions, I also went through a very technical investigation into the capture and display (both interactively and statically) of the data generated by the various motion capture processes available to me. I was able to work with CMU Robotics / CS student, Hanbyul Joo, and the Panoptic Studio, which is a massively multiview system for markerless motion capture using 480 VGA cameras, 30+ HD cameras, 10 RGB-D sensors (Kinects), with hardware-based sync and calibration. I am very interested in the emergent field of volumetric capture, and being able to “film” people volumetrically for use in immersive experiences such as VR, MR, and interactive installation. I want to be able to capture people as they are – without having to wear motion capture suits with retroreflective markers – and to capture multiple people in physical contact with each other, which in traditional motion capture is extremely difficult to do. Dance is the perfect form to explore this, and with slowdanger we definitely pushed the limits of each system we were working with. For the capture in the Panoptic Studio I was told, yes they can touch, but hugging is very difficult. So the two dancers began in a hug. Then, in the Motion Capture Research Lab, with the leotards and markers, I was told that one dancer picking the other up would probably not work. So were born two peitàs of each dancer carrying the other. The hug from the Panoptic Studio worked (at least for my purposes, in which I was only using the dense point clouds, not the skeletons), but the two pietàs resulted in the rainfall of retroreflective balls from the leotards to the floor. I did not end up using this capture in my final piece, but I’m interested to experiment with it later to see what happens when a motion capture skeleton suddenly disintegrates.
Here’s a look into the capture process:
One of the big technical hurdles I encountered during this project was working with the PLY files generated by the Panoptic Dome. These are text files with x,y,z and r,g,b data which create a series of points that generate a dense point cloud – a 3 dimensional visualization of the captured object or person. Displaying these point clouds, or turning them into meshes with texture, is a reasonably documented workflow, through software such as Meshlab or Agisoft PhotoScan. However, scripting this process to generate high-resolution meshes with texture on thousands of PLY files, aka thousands of frames of a capture, is extremely difficult, and virtually non-existent. Each PLY file I received is about 25 megabytes, and in a 3 minute capture, there are roughly 8,000 frames. This means scripting either the display of these point clouds (relatively unaltered) or the creation of decimated meshes with high resolution textures re-projected onto the decimated mesh – is pushing the limits of the processing power of our current computers. 3D software such as Maya and Unity do not import PLY’s natively. This project required a good amount of collaboration, and I’m grateful to Charlotte Stiles, Ricardo Tucker, and Golan who all worked with me to try various methods of displaying and animating the point clouds. What ended up working was an OpenFrameworks app that used ofxAssimpModelLoader and ofMesh to load the point clouds, and ofxTimeline to edit them with keyframes on a timeline. When I first tried to display the point clouds, they were coming in with incorrect colors (all black), so with some research it was determined that the RGB values had to be reformatted from 0-255 integer values to 0-1 floats. I wanted to be able to get these point clouds into the other 3D software I was using, Maya and Unity, but OpenFrameworks was the only program to load and display them in a usable way, so I captured these animations through the ofApp using an Atomos Ninja Flame recorder, and then composited those videos with my other 3D animation into the final video using After Effects.
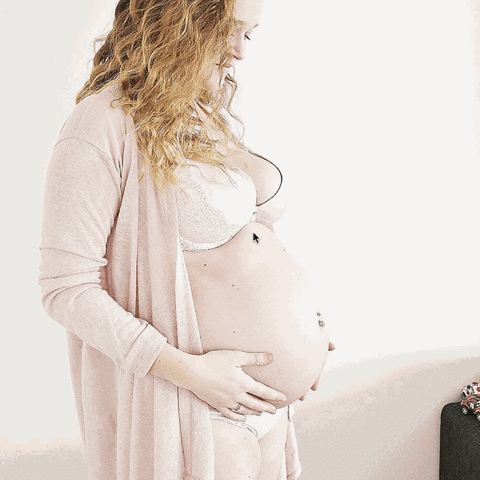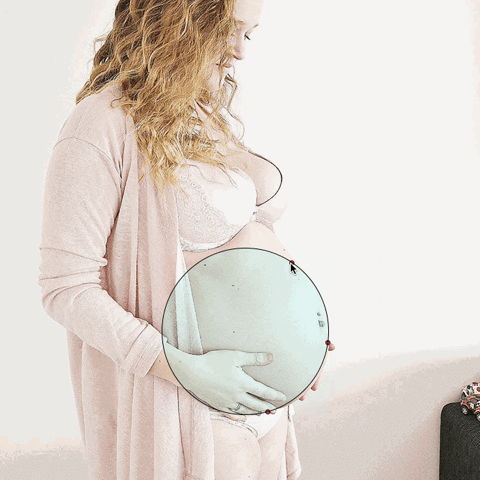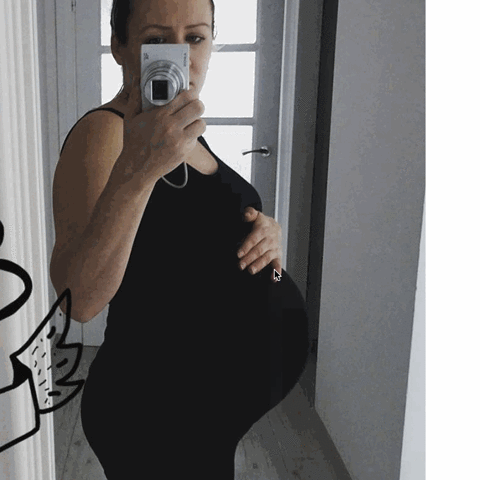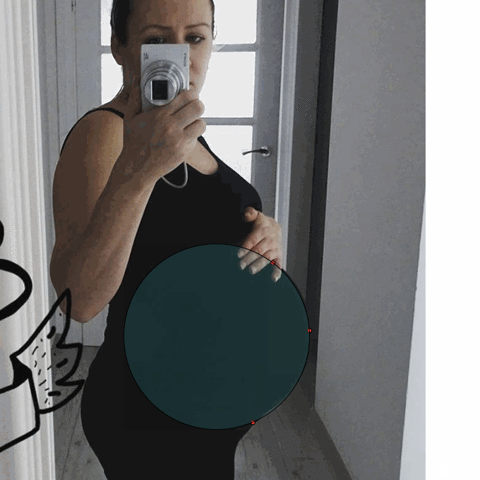
Here’s a gif from the music video:

From the song ‘body, my body‘ music video, by slowdanger, Anna Thompson and Taylor Knight, from the album, body released on MISC Records, 2017.
In addition to the music video, I was curious to create an immersive experience of the dance, using VR or AR. I had worked with Unity and Google Cardboard in a previous project for this course, but had not created anything for Oculus or Vive yet, so I decided to dive in and try to make a VR version of the dance for Oculus. For this, I worked with the motion capture data that I captured in the traditional mocap lab, using skeleton/joint rigs. For the figures, I took 3D scans of the dancer’s bodies, a full body scan and a closer head/shoulders scan, and rigged these to the motion capture data using Maya. For the Maya elements of the project, I worked in collaboration with Catherine Luo, as the slowdanger project stretched across two classes, and Catherine was in my group for the other class. She is also fabulous in Maya and very interested in character modeling, so we learned a lot together about rigging, skin weighting, and building usable models from 3D scans. Once we had these rigged models, I was able to import them from Maya into Unity to create an environment for the dancers to exist in (using 3D scans of trees taken with the Skanect Structure Sensor) and to build this project for VR. Witnessing this VR version of the dance, and witnessing others experience this, was extremely fascinating. Putting the dancer in VR allows the user to place themselves right in the middle of this duet, sometimes even passing through the dancers’ bodies (as they did not have colliders). This is something that is usually not possible in dance performances that happen live, so this created a fascinating situation where some users actually started to try to “dance” with the dancers, putting their bodies in similar positions to the dancers, clearly “sensing” a physical connection to them, and other users were occasionally very surprised when a dancer would leap towards them in VR. This created a collision of personal space and virtual space with bodies that straddled the line between the uncanny valley and actual perception as individual, recognizable people because of the 3D scanned texture and real movement captured. The reactions I received were more intense than I expected, and people largely responded physically and emotionally to the piece, saying that the experience was very surreal or more intense because the bodies felt in many ways like real people – there was a sense of intimacy with being so close to the figures (who clearly were unaware of the user). All of this is very fascinating to me, and something I want to play with more. I showed the VR piece to slowdanger themselves, and this is one of the most fascinating observations I’ve been able to have, witnessing the actual people experiencing their motion-captured, 3D scanned avatars in virtual reality. I’m curious what would happen if I was able to put the temporal visualization of the dancers into VR, where the textures changed over time, photographically – so facial expressions would be visible, and thus the texture would not be static as it was with the 3D scan rigged to a mocap skeleton. I’d like to try to work with the point cloud data further to attempt to get it to be compatible with Unity and Maya. I did find a tutorial on Sketchfab that loaded a point cloud into Unity, and was able to get it working, though the point cloud was made of triangles and would have worked better if it was more dense to begin with (to get higher resolution data), and I was not able to work with the scripts to get them to load and display many frames at once, to animate them.
Overall, I am very excited about the possibilities of this material, especially working with 3D scans rather than computer-modeled assets. This creates a very different experience for the user/participant/witness. I plan to work with motion capture further, especially dedicated to creating situations where embodiment is highlighted or explored, and I’d really like to do some experiments in multi-person VR, MR or AR that is affected or triggered by physical contact between people, and other explorations of human experience enmeshed in digital experience.