Skies worth Seeing
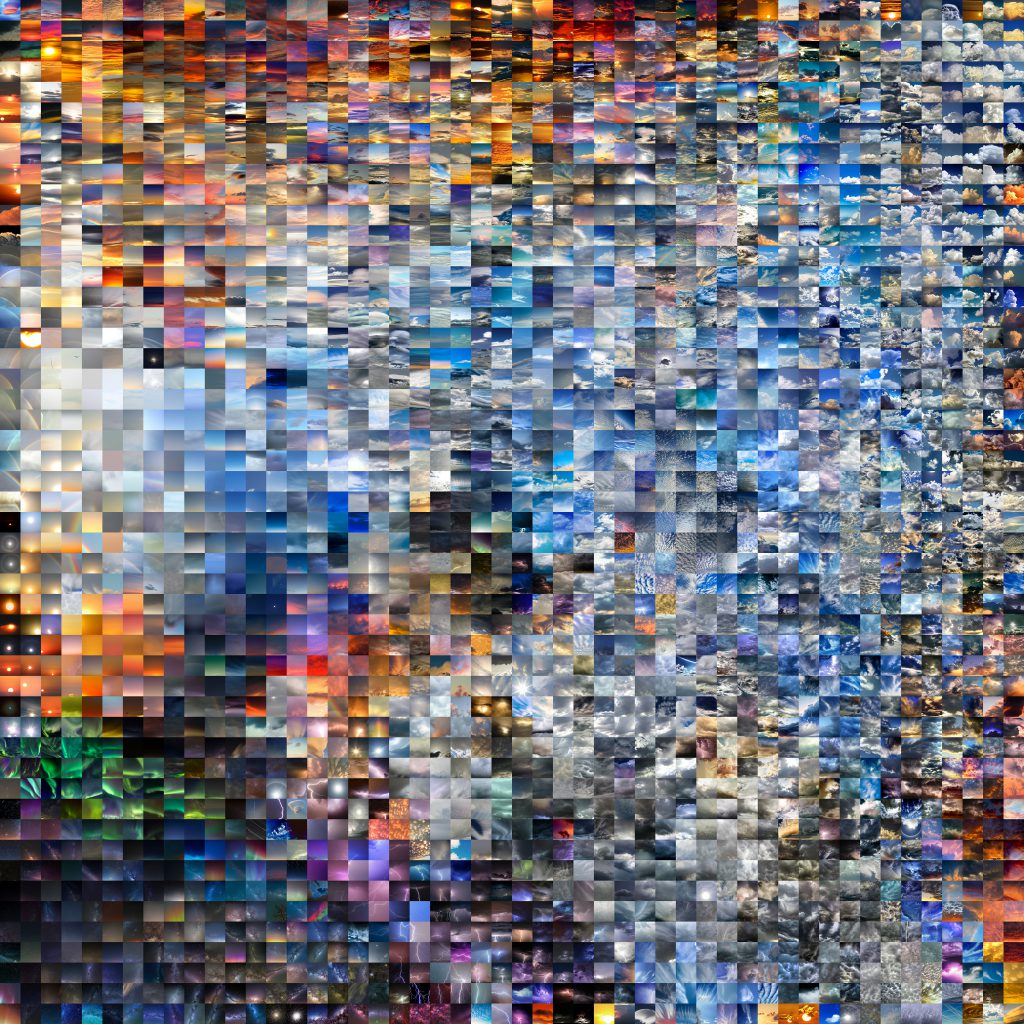
One of the subjects that appears again and again in my own photography is the sky. It is no doubt a classic subject for many photographers. The sky is of course always present and available to photograph, but is not necessarily always a compelling subject- so when does the sky become worth capturing? What are the qualities of the sky that transform it from a granted element of our everyday environment, into a moving and even sublime subject for a photograph?
To answer these questions and more, I looked to Flickr and my own image archive.
Choosing/culling images; identifying my own bias
Using the Openframeworks add-on ofxFlickr, by Brett Renfer, I was able to scrape thousands of images of skies.
My choice in tags, “sky, skyscape, clouds, cloudy sky, blue sky, clear sky, night sky, storm, stormy sky, starscape” absolutely had a large impact on the scraped images, as did the way that I was sorting the results (primarily by relevance and interestingness, as per Flickr’s API). Moreso, I was not able to find many images that were of the sky and only the sky- I had to reject many of the scraped images outright: clearly manipulated images, “astrophotography” type images of the sun or deep sky objects, monochrome images, illustrations, aerial images, or images with obtrusive foreground objects. Foreground objects were the most common reason for rejection; all together about 45% of the scraped images were rejected.

Many of the other images I scraped were acceptable in that the sky was clearly the primary subject, yet some landscape remained. This is an understandable compositional choice in photography but still was not appropriate for the analysis I wanted to make; with Golan’s help I developed a tool in Processing that would allow me to quickly crop images to just the sky.

The Unsorted Images
Arranged in a grid based on the order in which I downloaded them, they already reveal some information about the way the sky is photographed.

My primary observation at this stage is just how much variety there is in the images. The sky is traditionally thought of as blue, yet blue isn’t necessarily dominant in the collage. A huge amount of different sky conditions are represented, and the editing treatments span from the subtle to the incredibly exaggerated. Beyond this though, the unsorted collage is hard to interpret.
The Sorted Images
Seeking a greater sense of order in the images, I chose to sort using t-SNE, or t-distributed stochastic neighbor embedding. For this, I used the ofxTSNE add on by Gene Kogan. The sorted image itself is compelling, but can also better reveal the trends and variation within the dataset.
Now with some kind of organization, trends within the dataset start to emerge. Night skies are popular, but specialized (often requiring equipment like tripods, high ISO capable sensors); there are distinct categories here- auroras, the milky way, and lightning were the most dominant. Sunsets and sunrises dominate the top edge of the collage- this is a time when the sky is predictably interesting, so their high representation seems logical. The photographers here are clearly not shy about bumping up the colors in these images either.
Rainbows have a small but still notable presence; this is a compelling sky event, but is less predictable. Gray, stormy skies also make up a large portion of the image. The cloud formations here seem to be an attractive subject, but have less representation in the image set— perhaps because it isn’t always pleasant or feasible to go out and make images in a storm.
The largest sections, represented in the right side of the collage, show mostly blue skies with medium and large cloud formations. What varies between these two sections is how they are edited; I saw a distinct divide between images that were processed to be much more contrasty, and those that were less altered.
Even within the “calmer” images, where no large cloud features were present, there was a large variation in color. It’s safe to say that many of the more vibrant images here were also edited for increased saturation.

Applying this same process to my own images (albeit a more limited set; I took these ~200 images over the span of a few weeks from my window in Amsterdam) also allows me to compare my habits as a photographer to the Flickr community at large. I generally prefer not to edit my photos heavily, and leave the colors closer to how my camera originally captured them- Flickr users clearly have no problems with bumping up the vibrancy and saturation of their skies to supernatural levels.

Moving Forward
I would like to continue adding to this repository of images of skies and eventually run a larger grid, using a more powerful computer. I seemed to hit the limits of my machine at 2500 images. There are definitely diminishing returns to adding more images, but if I can further automate and streamline my scraping/culling process it could be worth it.
I am also considering what other image categories on Flickr that this method could provide insight into. I’d be particularly interested in exploring how people photograph water.
Additionally, I’m exploring how the collage itself might continue to exist as a media object- I would like to produce an interactive online version that allows a user to zoom in and explore individual images in the collage, and view annotation and metadata related to each specific image as well as the sections.
As a physical object, I think the collage could make a nice silk scarf.





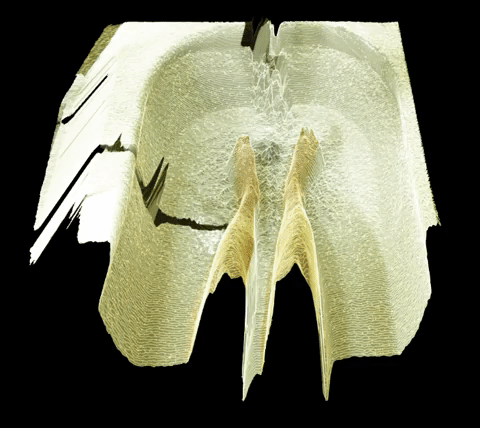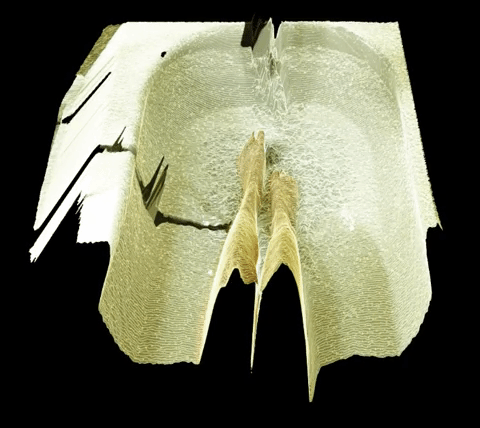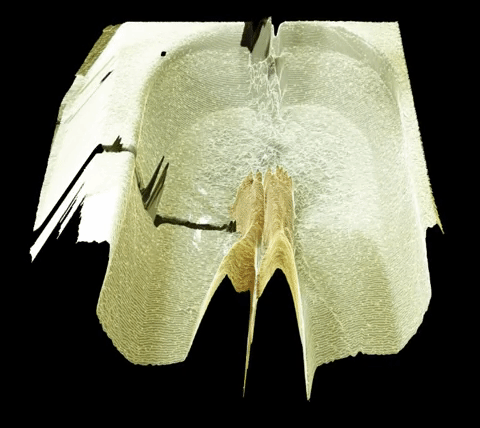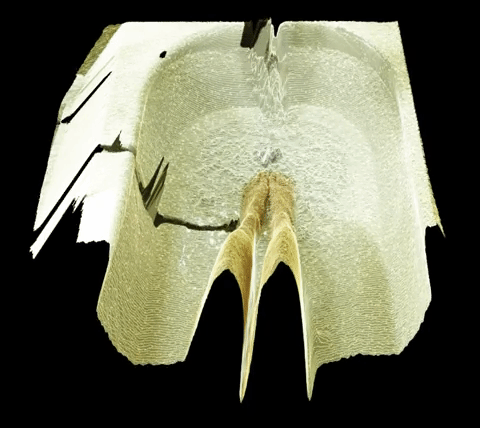










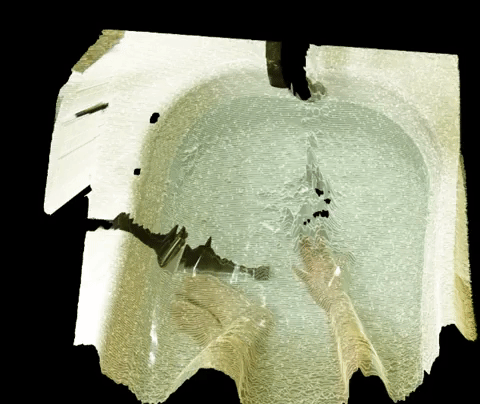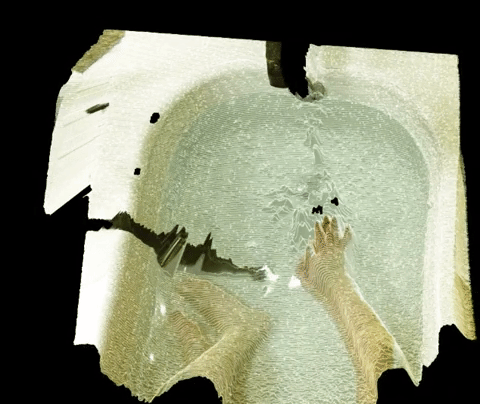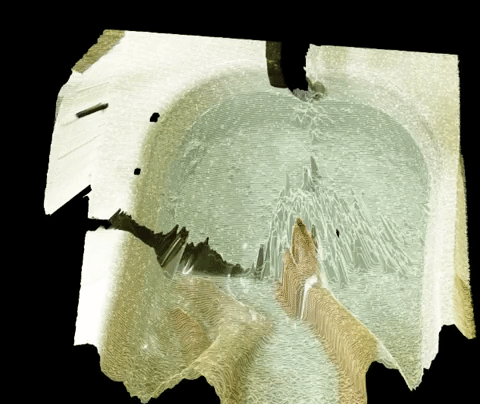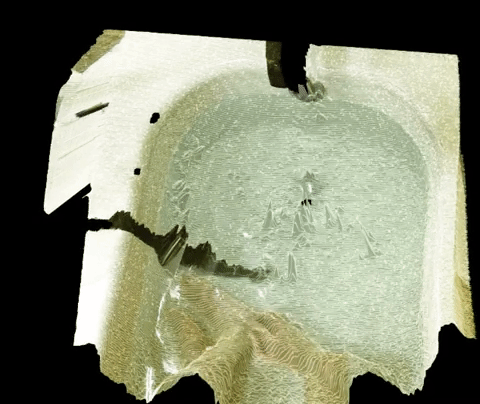
 For my event project, I am largely interested in investigating things that happen underwater. I have two possible methods for capture-
For my event project, I am largely interested in investigating things that happen underwater. I have two possible methods for capture-