My event project is a software that takes in lots of different photographs of a certain event as input, then uses computer vision to find the similarity and differences between the images in order to sort them, and finally produce a video/animation of the event by playing the sorted images in sequence.


Animation of a browsing horse and a running horse automatically generated by my program.
(More demos coming soon!)
Inspiration
I was inspired by those animations complied from different photographs Golan showed us on class, eg. the sunset. I thought it’s an interesting way to observe an event, yet aligning the photos manually seemed inefficient. What if I can make a machine that automatically does this? I can simply pose any question to it: How does a horse run? How does a person dance? and get an answer right away.

Eventide, 2004 from Cassandra C. Jones on Vimeo.
I soon found it a very challenging problem. I tried to break it down into many smaller problems in order to solve it.
Background Extraction
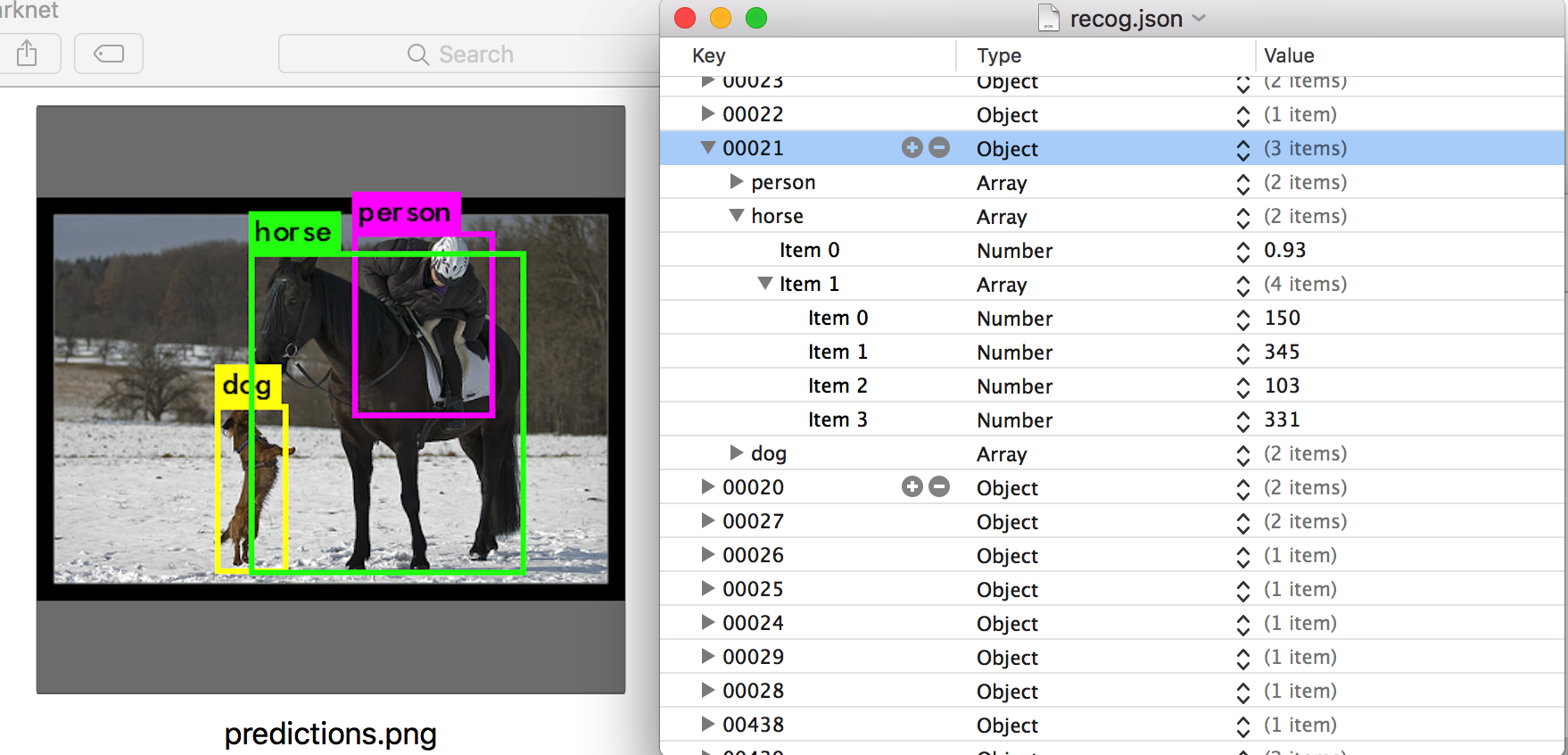
I used a general object detection tool powered by neural networks called darknet to find the bounding boxes of objects in an image. However most objects have irregular shapes that do not resemble a box. So finding out exactly which pixels are actually part of the object and which ones are part of the (potentially busy) background is a problem.
After much thought, I finally came up with the following algorithm:
Since I already have the bounding box of the subject, if I extend the bounding box in four directions by say 10 pixels, The content between the two boxes is both a) definitely not part of the subject, and b) visually similar to the background within the bounding box.
The program then learns the visual information in these pixels, and delete everything within the bounding box that look like them.
The results look like this:
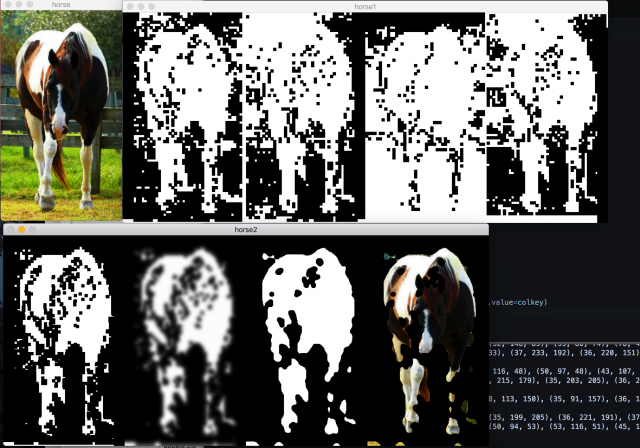

Although it is (sort of) working, it is not accurate. Since all future operations depend on it, the error propagation will be extremely large, and the final result will be foreseeably crappy.
Fortunately, before I waste more time on my wonky algorithm, Golan pointed me to this paper on semantic image segmentation and how Dan Sakamoto used it in his project (thanks Golan). The result is very accurate.


The algorithm can recognize 20 different types of objects.
I wrote a script similar to Dan Sakamoto’s which steals results from the algorithm’s online demo. Two images are downloaded for each result: one is the original photo, the other has the objects masked in color. I did some tricks in openCV and managed to extract the exact pixels of the object.
Image Comparison
I decided to develop an algorithm that can decide the similarity between any two images, and to sort all images, I simply recursively find the next most similar image and append it to the sequence.

Since the subject in an image can come in all sorts of different sizes and colors, and might be cropped, rotated, blurred, etc., I tried to use a brute-force window search to counter this problem.
The program scales and translate the second image into tens of different positions and sizes, and overlays it on top of the first image to see how much of them overlaps. A score is thus calculated, and the alignment with the highest score “wins”.

This, although naive and rather slow, turned out to be reasonably accurate. Currently only the outline is compared, I’m thinking about improving it by doing some feature-matching.
Image sorting
To sort all the images, with the information about the similarity (distance) between any two of them, is analogous to the traveling salesman problem:

I simply used Nearest Neighbor to solve it, but will probably substitute it with a more optimized algorithm. Here is a sequence of alignments chosen from 300 photos.

Notice how the horses’ head gradually lowered.
Rendering
I didn’t expect exporting the sequence with all image aligned would be such a headache. Since during the matching phase, the images went through a myriad of transformations, I now have to find out what happened to each of them. And worse, the transformation needs to be propagated from one image to the next. Eventually I have it figured out.

An interesting thing happened: the horses keep getting smaller! I guess it’s because the program is trying to fit the new horses into the old horses. Since this shrinking seems to be linear, I simply wrote a linear growing to counter it:

Sans-background version:

It took a whole night to run the code and produce the above result, so I only had time to run it on horses. I plan also to run it on birds, athletes, airplanes, etc. during the following nights.
Anonymous feedback from group crit, 4/13/2017:
Technically, this is a tour-de-force; well done. However, the horse subject seems arbitrary. Even if it’s not arbitrary (you could connect it to Muybridge), you need to take it to a new place, or to some new extreme. Tell a story, or have the horse transform into something remarkable (slowly changing into other animals, etc.)
Charlie recommended this: multi still image ad by Michel Gondry:
https://www.youtube.com/watch?v=f7T9B7Y4ET0
Sorting images into a sequence using computer vision. 9 eyes jon rafman – commercial of people getting out of bed in the morning.
This is a really computationally difficult project and I’m super impressed you pulled it off+
^^^^^^ + ++ + + ++ + + + + + + + + + !!!!!!!! +++Yaass
“i guess the program is trying to fit the new horses in the old horses” lol
for the image alignment, you could compute the 2d correlation & find the peaks in it to find the best offset to align them. there are also more clever image registration algorithms but the 2d correlation is ok.
Tali Dekel at MIT did this: http://people.csail.mit.edu/talidekel/ (she gave a talk last semester about it and showed a computationally sorted horse animation done with google images). I honestly would email her and show her your project, she works at Google now I think +
This honestly feels like a computer vision project more than an art project – not a bad thing. I feel like your work often straddles this line. I think the seemingly arbitrary choice of subject makes it a computer vision project
^ one could use this tool with more provocative subject matter to make really interesting statements. What events could be ‘reordered’ to reveal something about the original?+
^ yes it feels like research for the feasibility of a project
Interesting cmu class which addresses many of the problems you are encountering: 86-375
Great diagrams and explanation
the horse animation !
its like microsoft hyperlapse
what if u applied it to porn (been done!) (but by hand) (true)
^ or speech? Scrambling up a speech with an “alternative speech”
what if you applied it to live / time delayed video
You could take a very short video of someone moving very slightly, and then sort the frames in the LEAST congruous order
^experiment with other weird sorting functions (ie. “sort by redness of images”, “sort by amount of motion blur”, “sort by how much people are smiling”, etc)
^ I love this. Totally different project but I love it as a concept
This feels like a good candidate for playing with “cannon time.” Such as, begin with your horse, and as the video comes along, more horses follow, other elements etc