Pose Flatland
why / what
Pose Flatland is a visualisation of a horizontal sheets of commonality, orthogonal to but intersecting with myriad disparate human threads across the world. It does this by overlaying the physical flattened poses of people across the world, letting us discover similar being in distant places. A many (24) eyed world-sized camera.
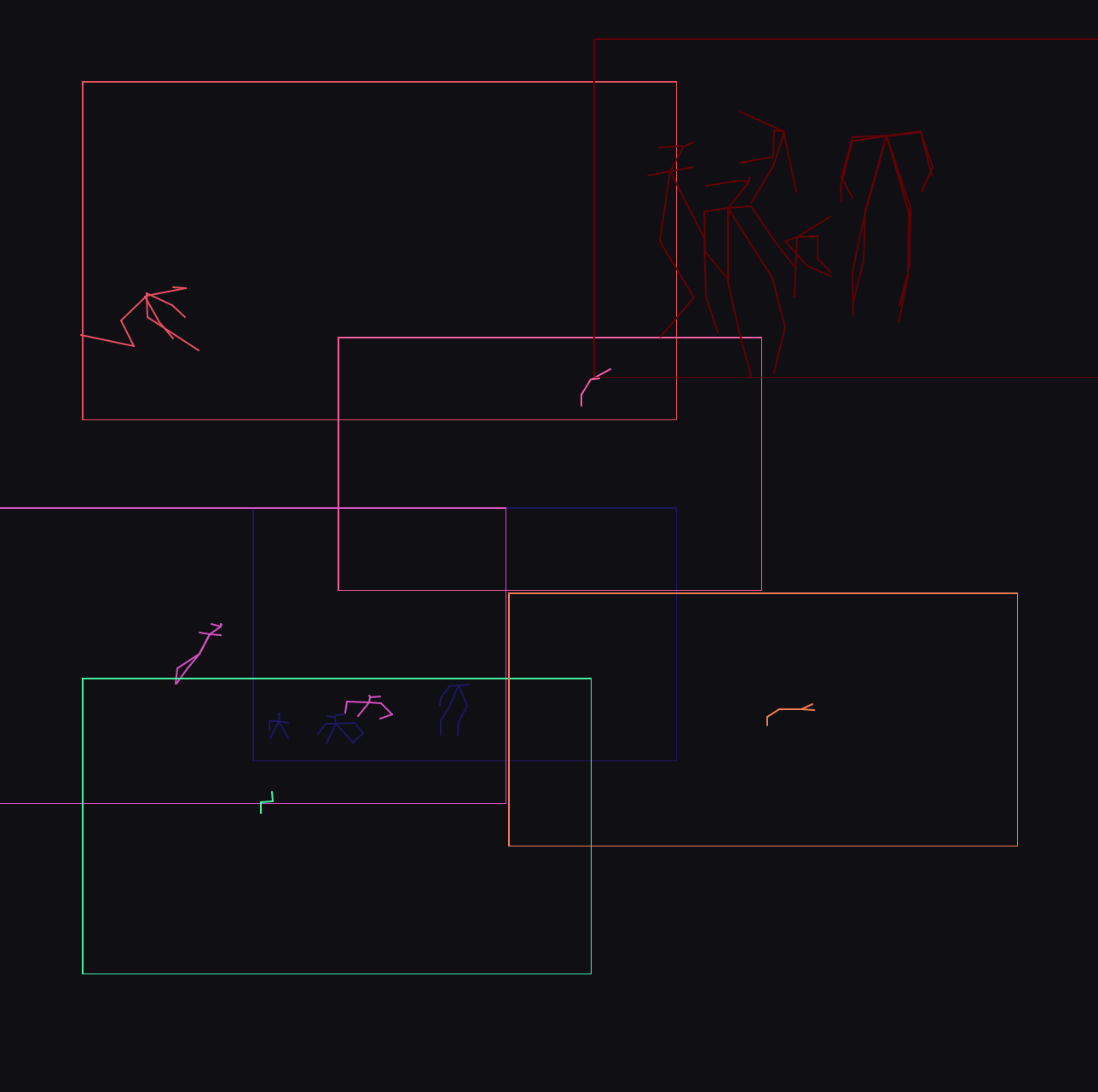
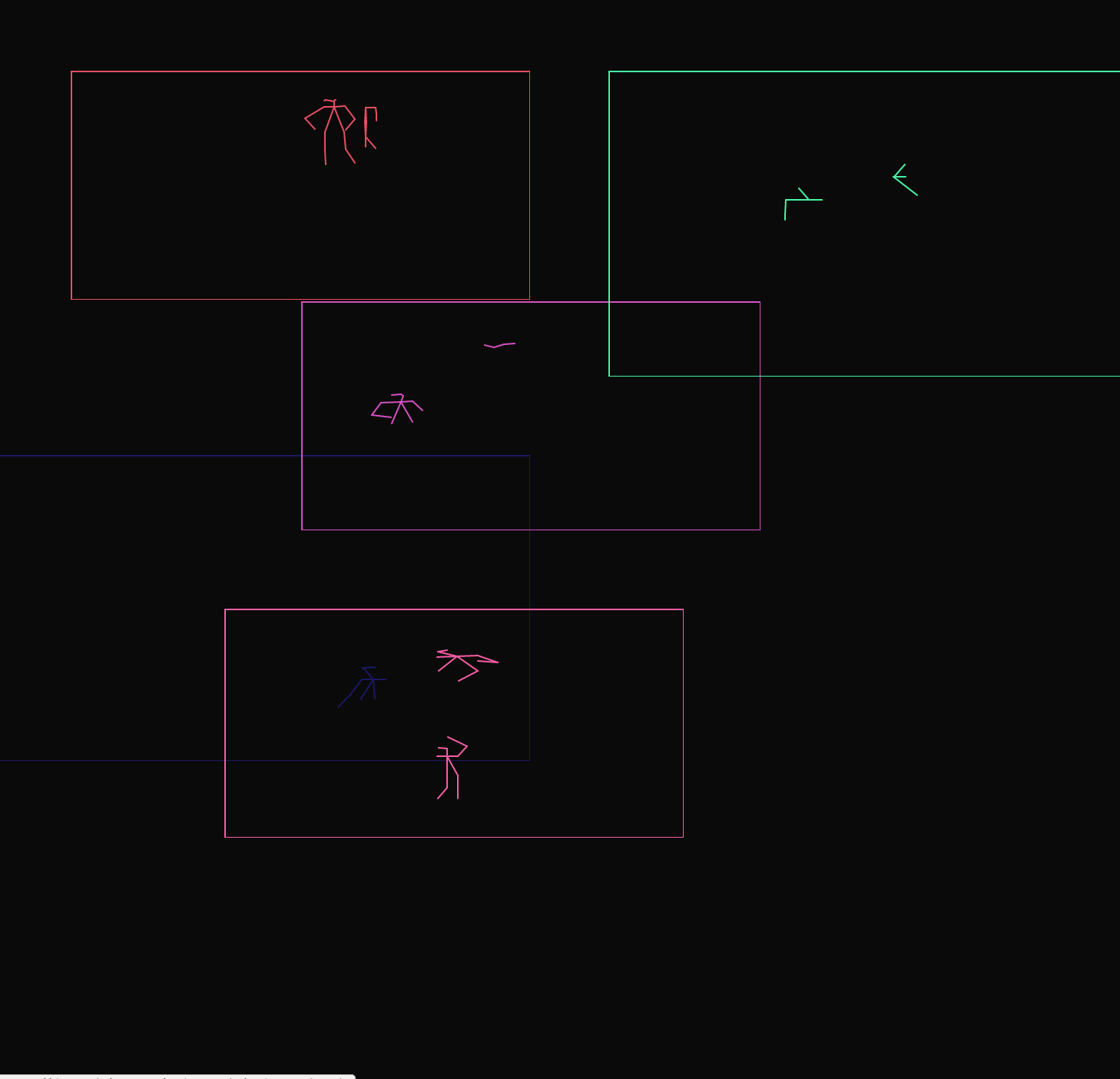
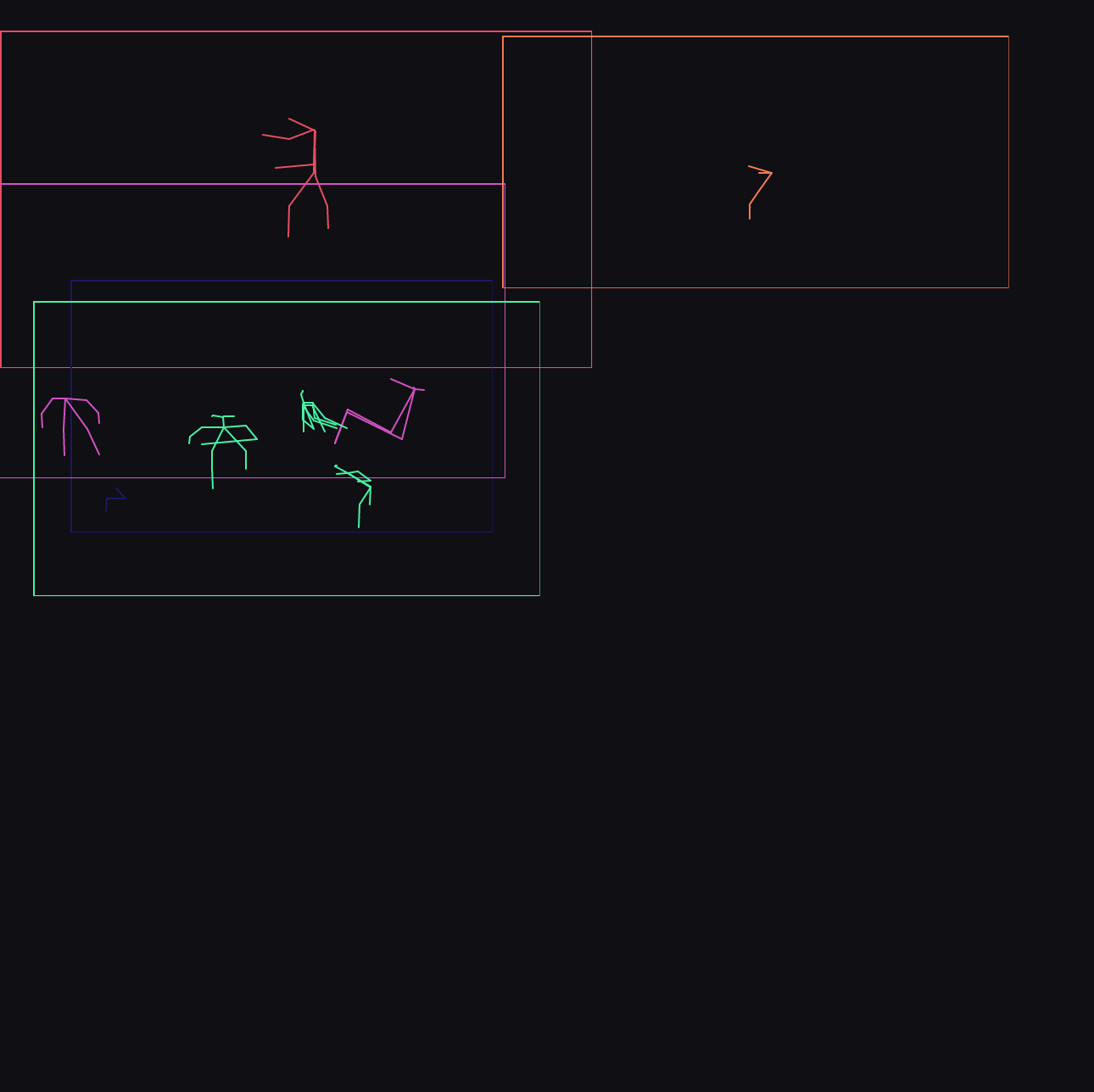
how
I adapted an implementation of Real Time Multi-Person pose segmentation, to infer pose skeletons from raw RGB monocular images.
Then, I fed in live video from unsecured ipcameras on insecam.org, processing it frame by frame. After some more optimisations — moving the CPU computation to the GPU — the final network is able to process video at ~10 frames per second into pose skeletons, using a GTX 1080 Ti.
Example output from network:
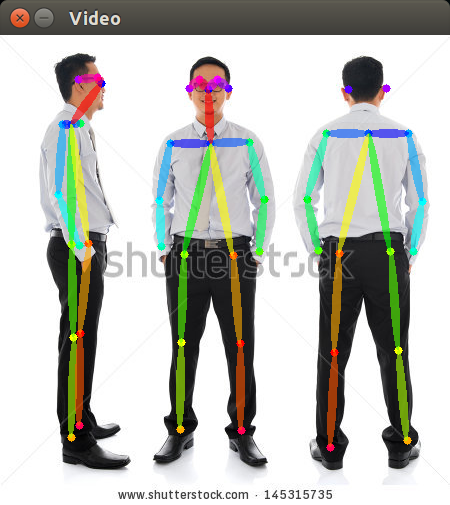
You can see the pose skeleton overlaid onto a stock photo, with the bones labeled.
I created a webserver exposing this functionality, creating a streams of pose skeletons from a streams of video, and then used p5js to visualise the skeletons, overlaying them into one composition. In this iteration, 24 cameras are overlaid. The cameras cover locations where common human experience occurs – streets, restaurants, the beach, the gym, the factory, the office, the kitchen. For each of those categories, multiple locations from across the world are present.
The visualisation only updates when a camera is active and a person is detected, the final composition varying over time as patterns of activity move over the sampled locations. In the above images, the bottom image is taken near noon in Delhi, whereas the top two are from near noon in New York.
The source code is available here: aman-tiwari/pose-world
prior art
Looking back (especially when coupled with the final visualisaion), this project directly links to Golan Levin’s Ghost Pole Propogator, which uses computer vision algorithms to contract people silhouettes into centerlines.

Anonymized feedback from the group critique, 4/13/2017.
It would help alot in explaining your project if you showed examples (screenshots) of the security cameras first, and then showed the skeletonization process (i.e. a GIF or embedded demonstration video). Once you show those two things, your goals would be a lot more clear. Also, a paper sketch of your final concept (i.e. hotel rooms) would help explain the goal of where you’re trying to go with this.
Skeletons from security cameras. But — proof ? perhaps too divorced from original video. Think about translation. Are you in invested in surveillance? Deal with the how and the why.
The results might be more interesting and intelligible if we saw the webcam videos, greyed out, underneath the skeletons. The stick figures, by themselves, could otherwise just be random.
I don’t know what I’m looking at
Conceptually strong, end result is underwhelming without proper context+
^ I don’t know if I agree, it’s in real time, that’s cool (oh I agree with “without proper context”)
I really like the simple neon lines. +
I think I understood this because we spoke about it together before. Maybe you should explain your computational process in a little more detail. But your concept is very strong, humorous and intelligent — congrats (–> CMU speak)
reminds me of minimalist early 80s computer graphics
Reminds me greatly of Manfred Mohr’s work – pioneering digital artist who from the 60’s has exclusively worked with multidimensional cubes “generates 2-D semiotic graphic constructs using multidimensional hypercubes.’’
Now that I sort of understand what you did, I want to hear more about the concept again. It kind of went over my head before
Is this the same machine learning neural network that the Panoptic Studio uses at CMU? Their results look very similar.