My event project is going to be a software that takes in lots of different photographs (from different sources) of a certain event as input, then uses computer vision to find the similarity and differences between the images in order to sort them, and finally produce a video/animation of the event by playing the sorted images in sequence.
For example if I input a lot of images that consist of running horses from google images, one way the software can process them is to first align by the positions of horses in them, and then sort by similarity of the pose of the horse. It can thus produce a video of a running horse consisting of frames from different images.
Similarity, I can input images of dancing people, flying birds, ball games, fights, etc.
I’m using general object detection to find the binding boxes of all objects in images. Then, depending on which works better, I can either do pixel-wise comparison or contour comparison to produce a similarity score for any two arbitrary images.
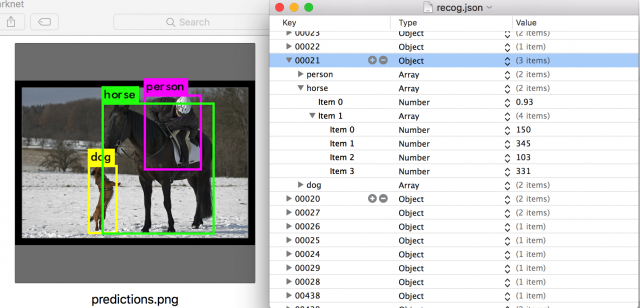
Here’s where I am in the process:
- I wrote a program to download images from ImageNet, where tons of images are categorized by subject.
- I found a neural network object detection tool called darknet. I tweaked its source code so it can print out the bounding boxes of all objects in an image into Terminal. Then I wrote a python program to batch process my source images using this tool, and parse the output.
- I used openCV in python to do some simple manipulations on the source images so the comparison process will probably be more accurate.
What I’m trying to figure out:
Although I have information about the bounding boxes, most objects have irregular shapes that do not resemble a box. So finding out exactly which pixels are actually part of the object and which ones are part of the (potentially busy) background is a problem. I’m going to read darknet’s source code to find out if this information is already in there. If not, I will have to write something myself.