
Image Sequencer
My final project is a continuation of my experiments in the event project, which is a tool to computationally sort images into sequence based on their common features.
The project runs three modules step by step to achieve this:
1) Image segmentation, extracting object of interest from the background,
2) Comparison, comparing the similarity between two given extracted objects, and
3) Sorting, ordering a set of images into sequence using comparison function.
Last time, the algorithm used in each module is fixed. For the final project, I devised several alternative algorithms for each module, so the process can be customized into different pipelines suited for a variety of datasets.
Speeding up
I only had the time to sort one dataset (horses) for my event project since processing time take more than 24 hours. So the first priority is to speed it up.
I designed several numpy filters applied on images as matrices to replace pixel by pixel processing. This made the comparison part of my program run around 200 times faster. However the image segmentation is still relatively slow because the images are uploaded and then downloaded from the online image segmentation demo.
Now that the program runs much faster, I had the chance to apply it on a variety of datasets.
Sorting Objects
475 Bottles from Technisches Museum Wien

Sorting faces
My previous algorithm compares two images based on the outline of the object of interest. However, this is not always desired for every dataset. For example, the outlines of people’s heads might be similar, yet their facial features and expressions can be vastly different so if made adjacent frames, it wouldn’t look smooth.

I used openCV and dlib for facial landmark detection, and compared the relative spatial location of pairs of key points. Then the program iterates through all faces and place the faces with the most similar key points together. Sorting 348 portraits from MET, this is what I get:

Alternative sorting methods and morphing
From peer feedback, I realized that people are not only interested in the structural similarity between objects in two images, but also other properties such as date of creation, color, and other dataset-specific information.
However, the major problem sorting images using these methods is that the result will look extremely choppy and confusing. Therefore, I thought about the possibility of “morphing” between two images.
If I am able to find a method to break a region of image into several triangles, and perform an affine transformation of the triangles from one image to another, slowly transitioning the color at the same time, I can achieve a smooth morphing effect between the images.
Affine transformation of triangles
In order to do an affine transformation on a triangle from original transformation to target transformation, I first recursively divide the original triangle into many tiny triangles using a method similar to the Sierpinski’s fractal, but instead of leaving the middle triangles untouched my algorithm operates on all the triangles.

The same step of recursion is done on the target triangle. Then, every pixel value of every tiny triangle in the original transformation is read, and then drawn onto the corresponding tiny triangles in the target transformation. Below is a sample result:

Morphing

Since facial landmark detection already provided the key points, a face can now easily be divided into triangles and be transformed into another face. Below is the same portraits from MET sorted by chronological order, morphed.
The problem now is to find a consistent method to break other things that are not faces into many triangles. Currently I’m still trying to think of a way.
Re-sorting frames of a video
An idea suddenly came into my mind, what if I re-sort some images that are already sorted? If I convert a video into frames, shuffle them, and sort them using my own algorithm into a video, what would I get? It will probably still be smoothly animated, but what does the animation mean? Does it tell a new story or give a new insight into the event? The result will be what the algorithm “think” the event “should” be like, without understanding the actual event. I find this to be an exciting way to abuse my own tool.
Left: Original Right: Re-sorted


Alternative background subtraction
I ran the algorithm on my own meaningless dance. It transformed into another, quite different, meaningless dance. I wonder what happens if I do the same on a professional dancer performing a familiar dance.
When I tried to run the image segmentation on ballet dancers, the algorithm believed them to be half-cow, half-human, armless monsters. I guess it hasn’t been trained on sufficient amount of costumed people to recognize them.
So I had to write my own background subtraction algorithm.
In the original video, the background is the same, yet the camera angle is constantly moving, so I couldn’t simply median all the frames and subtract from it. I also couldn’t use similar methods because the dancer is always right at the middle of the frame, and the average/median/maximum of the frames will all have a white blob in the center, which is not helpful.
Therefore I used a similar method described in my event post, which is for each frame, learn the background from a certain region, and subtract the pixels that resembles this sample surrounding the object of interest.
I sample the leftmost section of each frame, where the dancer has never been to, and horizontally stack this section into the width of the frame, and subtract the original from this estimated background.
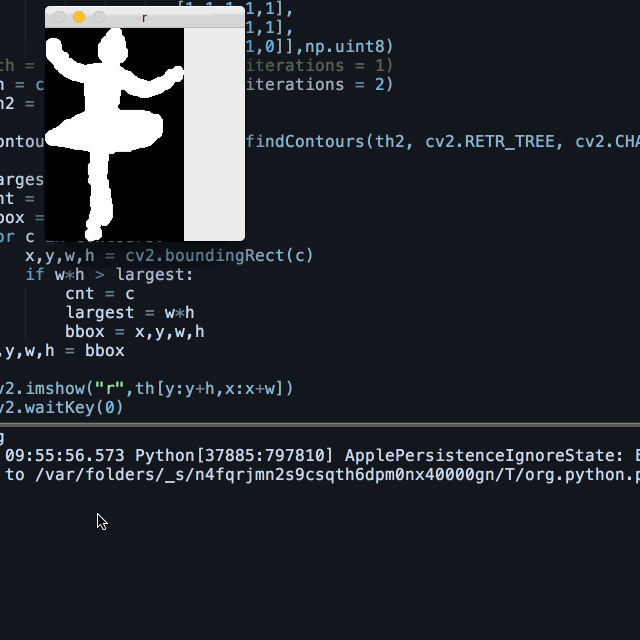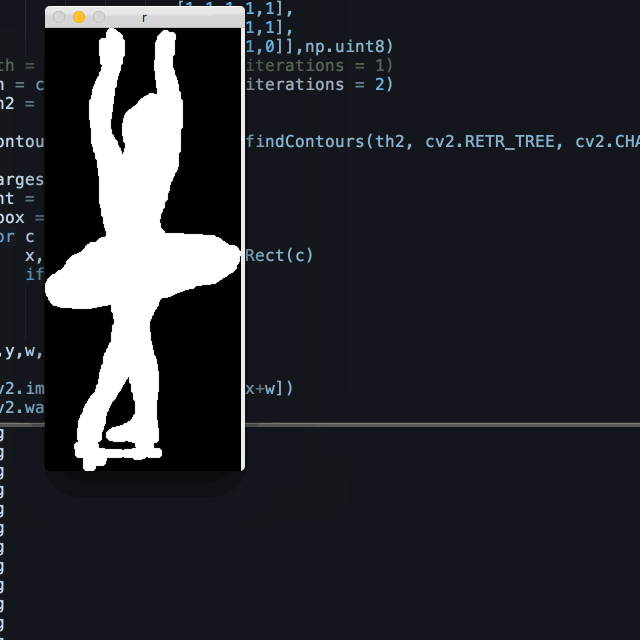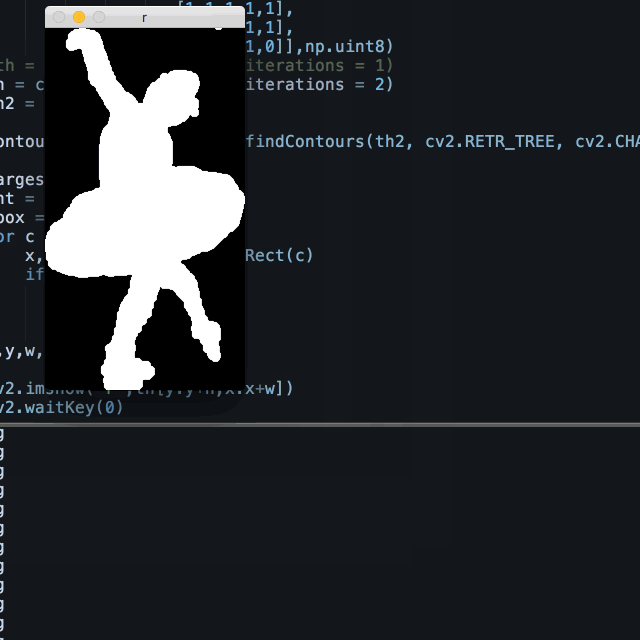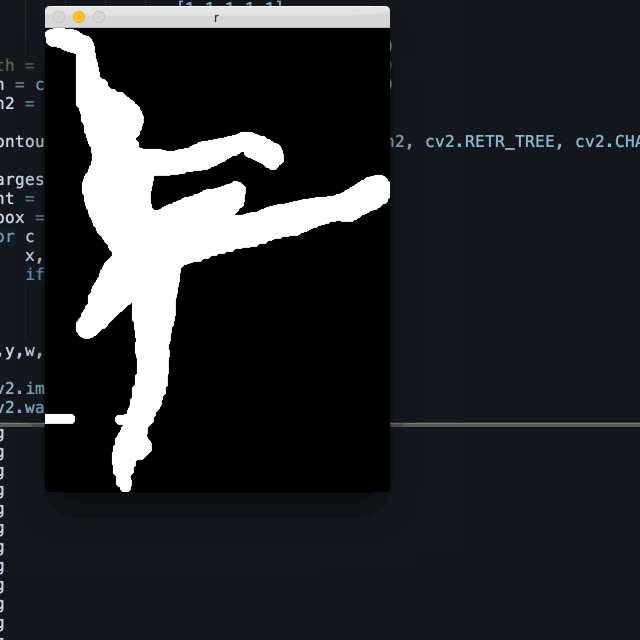
Combined with erode/dialect and other openCV tricks, the it worked pretty well. This method is not only useful for ballets, as it’s a common situation in many datasets to have relatively uniform backgrounds yet complicated foregrounds.
Using the same intensity based registration (now 200x faster), the program complied a grotesque dance I’ve never seen before:
